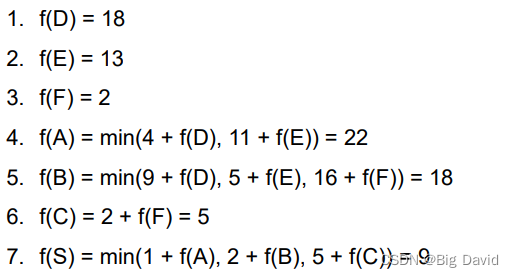1. 序号编码
序号编码通常用于处理类别间具有大小关系的数据。例如成绩,可以分为低、中、高三档,并且存在“高>中>低”的排序关系。序号编码会按照大小关系对类别型特征赋予一个数值ID,例如高表示为3、中表示为2、低表示为1,转换后依然保留了大小关系。
2. 独热编码
独热编码通常用于处理类别间不具有大小关系的特征。例如血型,一共有4个取值(A型血、B型血、AB型血、O型血),独热编码会把血型变成一个4维稀疏向量,A型血表示为(1,0,0,0),B型血表示为(0,1,0,0),AB型血表示为(0,0,1,0),O型血表示为(0,0,0,1)。对于类别取值较多的情况下使用独热编码需要注意以下问题。
(1)使用稀疏向量来节省空间。在独热编码下,特征向量只有某一维取值为1,其他位置取值均为0.因此可以利用向量的稀疏表示有效地节省空间,并且目前大部分的算法均接受稀疏向量形式的输入。举个例子:
对于向量 ,其稀疏表示为
10代表 的长度,[4,6]表示非零元素的下标,[1,3]表示非零元素的值。
(2)配合特征选择来降低维度。高维度特征会带来几方面的问题。一是K近邻算法中,高维空间下两点之间的距离很难得到有效地衡量;二是逻辑回归模型中,参数的数量会随着维度的增高而增加,容易引起过拟合问题;三是通常只有部分维度是对分类、预测有帮助,因此可以考虑配合特征选择来降低维度。比如PCA。
以下内容为GPT补充:
独热编码是一种常见的稀疏表示方法,用于将分类变量转换为机器学习算法可以处理的形式。然而,独热编码的一个缺点是它会产生非常稀疏的向量,可能占用大量的内存空间,尤其在处理大规模数据集时。
为了改进独热编码以节省空间,可以考虑以下方法:
1. 使用稀疏矩阵:在许多机器学习库中,可以使用稀疏矩阵来表示独热编码。稀疏矩阵只存储非零元素的位置和值,而且在计算时可以进行优化,从而节省内存空间。
2. 哈希技巧:可以使用哈希技巧将独热编码的向量映射到一个更小的空间中,从而减少存储空间。这种方法可以通过哈希函数将原始的独热编码向量映射到一个固定长度的哈希表中。
3. 压缩编码:可以使用压缩编码技术(如变长编码)来减少存储独热编码向量所需的位数,从而节省空间。
通过以上方法,可以改进独热编码以节省空间,特别是在处理大规模数据集时。
3. 二进制编码
二进制编码主要分为两步,先用序号编码为每个类别赋予一个类别ID,然后将类别ID对应的二进制编码作为结果。以A、B、AB、O血型为例,表1.1是二进制编码的过程。A型血的ID为1,二进制表示为001;B型血的ID为2,二进制表示为010;以此类推可以得到AB型血和O型血的二进制表示。可以看出,二进制编码本质上是利用二进制对ID进行哈希映射,最终得到0/1特征向量,且维数少于独热编码,节省了存储空间。

除了以上常见的编码方法以外,有兴趣的读者还可以进一步了解其他的编码方式,比如Helmert Contrast、Sum Contrast、Polynomial Contrast、Backward Contrast等。