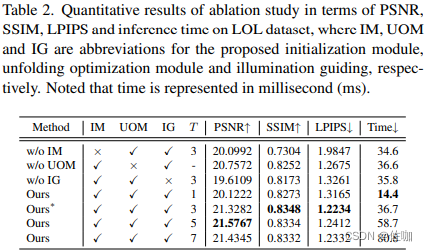
一:各文件的使用回顾
1.items的使用
items 文件主要用于定义储存爬取到的数据的数据结构,方便在爬虫和 Item Pipeline 之间传递数据。
items.pyimport scrapyclass TencentItem(scrapy.Item):# define the fields for your item here like:title = scrapy.Field()position = scrapy.Field()date = scrapy.Field()
2.pipline的使用
(1)pipelines介绍
管道文件 pipelines.py 主要用来对抓取的数据进行处理:一般一个类即为一个管道,比如创建存入MySQL、MangoDB 的管道类。管道文件中 process_item() 方法即为处理所抓数据的具体方法。
(2)pipelines常用方法
process_item(self,item,spider):处理爬虫抓取的具体数据,在process_item()函数中 必须要return item,因为存在多管道时,会把此函数的返回值继续交由下一个管道继续处理;open_spider():爬虫项目启动时只执行一次,一般用于数据库连接;close_spider():爬虫项目结束时只执行一次,一般用于收尾工作,如数据库的关闭。
(3)pipelines注意点
pipeline对应的值越小优先级越高pipeline中的process_item方法的名字不能够修改为其他的名称
二:工作流程回顾
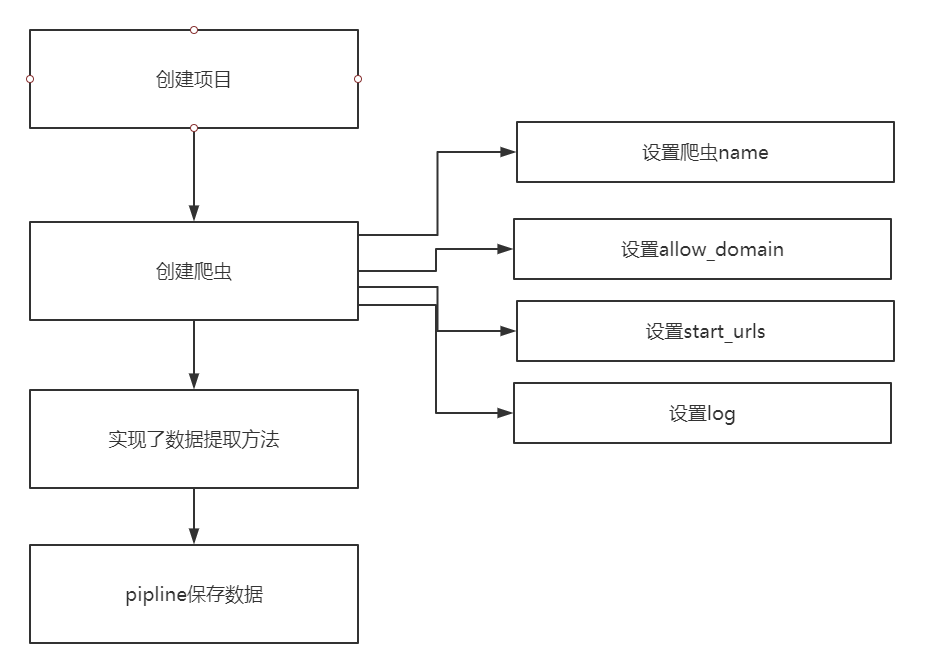
1.如何处理翻页

2.scrapy.Request知识点
scrapy.Request(url, callback=None, method='GET', headers=None, body=None,cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None)常用参数为:
callback:指定传入的URL交给那个解析函数去处理
meta:实现不同的解析函数中传递数据,meta默认会携带部分信息,比如下载延迟,请求深度
dont_filter:让scrapy的去重不会过滤当前URL,scrapy默认有URL去重功能,对需要重复请求的URL有重要用途
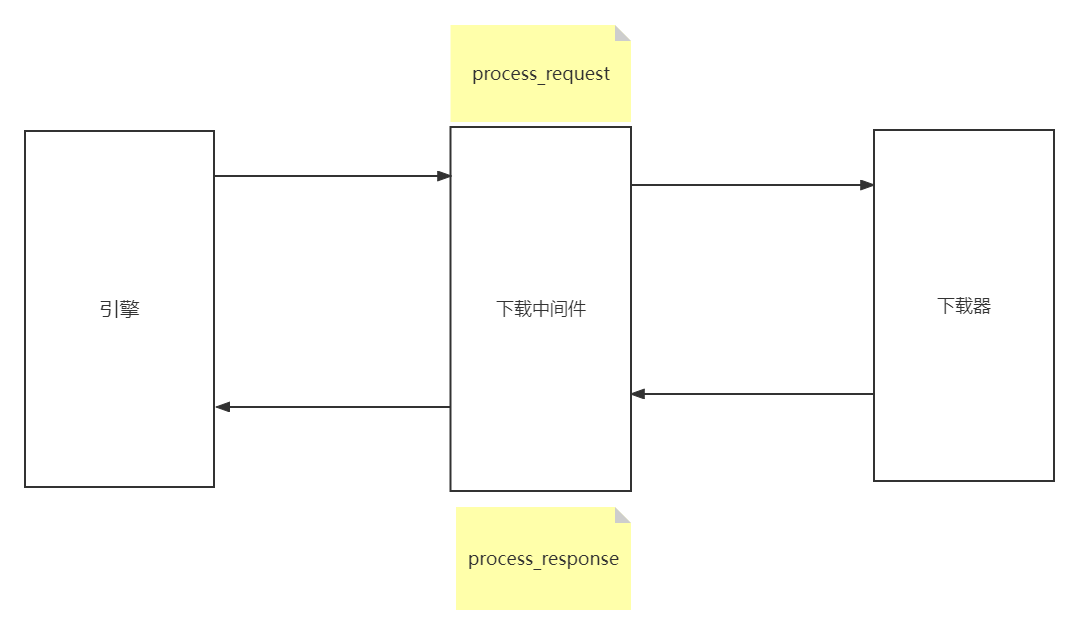
三:Scrapy下载中间件
下载中间件是scrapy提供用于用于在爬虫过程中可修改Request和Response,用于扩展scrapy的功能
使用方法:
- 编写一个
Download Middlewares和我们编写一个pipeline一样,定义一个类,然后在settings中开启Download Middlewares默认方法 - 处理请求,处理响应,对应两个方法:
process_request(self,request,spider):当每个request通过下载中间件时,该方法被调用process_response(self,request,response,spider):当下载器完成http请求,传递响应给引擎的时候调用
当每个Request对象经过下载中间件时会被调用,优先级越高的中间件,越先调用;该方法应该返回以下对象:None/Response对象/Request对象/抛出IgnoreRequest异常
- 返回
None:scrapy会继续执行其他中间件相应的方法; - 返回
Response对象:scrapy不会再调用其他中间件的process_request方法,也不会去发起下载,而是直接返回该Response对象 - 返回
Request对象:scrapy不会再调用其他中间件的process_request()方法,而是将其放置调度器待调度下载 - 如果这个方法抛出异常,则会调用
process_exception方法
process_response(request,response,spider)
当每个Response经过下载中间件会被调用,优先级越高的中间件,越晚被调用,与process_request()相反;该方法返回以下对象:Response对象/Request对象/抛出IgnoreRequest异常。
- 返回
Response对象:scrapy会继续调用其他中间件的process_response方法; - 返回
Request对象:停止中间器调用,将其放置到调度器待调度下载; - 抛出
IgnoreRequest异常:Request.errback会被调用来处理函数,如果没有处理,它将会被忽略且不会写进日志。
1.中间件工作流程
下载中间件的工作原理如下:
- 当
Scrapy引擎收到需要下载的请求时,会将请求发送给下载中间件。 - 下载中间件接收到请求后,可以对请求进行修改,比如添加
headers、代理等。 - 修改后的请求被发送到目标服务器,目标服务器返回响应数据。
- 下载中间件接收到响应数据后,可以对响应进行修改,比如解密、解压缩、修改编码等。
- 修改后的响应被返回给
Scrapy引擎,引擎会继续处理响应数据。
2.通过中间件设置随机UA
爬虫在频繁访问一个页面的时候,这个请求如果一直保持一致。那么很容易被服务器发现,从而禁止掉这个请求头的访问。因此我们要在访问这个页面之前随机的更改请求头,这样才可以避免爬虫被抓。随机更改请求头,可以在下载中间件实现。在请求发送给服务器之前,随机的选择一个请求头。这样就可以避免总使用一个请求头。
需求: 通过中间件设置随机UA
中间件核心介绍:
# 拦截所有的请求def process_request(self, request, spider):# request 是请求对象 spider指向的是当前爬虫对象# Called for each request that goes through the downloader# middleware.# Must either:# - return None: continue processing this request# 返回空 继续执行这个方法送往下载器 等合适的下载器进行处理# - or return a Response object# 返回的是一个响应对象 终止当前流程 直接将该响应通过引擎返回给爬虫# - or return a Request object# 返回的是一个请求对象 终止当前流程 将请求对象返回给调度器 大多数情况下是更换新的request请求# - or raise IgnoreRequest: process_exception() methods of# 抛出异常 异常会给process_exception()方法进行处理 如果没有一个异常处理该异常# 那么该请求就直接被忽略了 也不会记录错误日志# installed downloader middleware will be calledreturn None# 自定义下载中间件
# 导入随机UA的库
import random
from fake_useragent import UserAgentclass UADownloaderMiddleware:def process_request(self, request, spider):ua = UserAgent()user_agent = ua.randomrequest.headers['User-Agent'] = user_agent注意: 在settings中开启当前中间件
DOWNLOADER_MIDDLEWARES = {# 'mw.middlewares.MwDownloaderMiddleware': 543,'mw.middlewares.UADownloaderMiddleware': 543,
}爬虫程序.py
class UaSpider(scrapy.Spider):name = 'ua'allowed_domains = ['httpsbin.org']start_urls = ['https://httpbin.org/user-agent']def parse(self, response):print(response.text)# dont_filter=True scrapy会进行自动去重yield scrapy.Request(url=self.start_urls[0],callback=self.parse,dont_filter=True)
3.Scrapy下载图片
scrapy为下载item中包含的文件提供了一个可重用的item pipelines,这些pipeline有些共同的方法和结构,一般来说你会使用Images Pipeline
内置方式下载图片:
使用images pipeline下载文件步骤:
- 定义好一个
Item,然后在这个item中定义两个属性,分别为image_urls以及images。image_urls是用来存储需要下载的文件的url链接,需要给一个列表 - 当文件下载完成后,会把文件下载的相关信息存储到
item的images属性中。如下载路径、下载的url和图片校验码等 - 在配置文件
settings.py中配置IMAGES_STORE,这个配置用来设置文件下载路径 - 启动
pipeline:在ITEM_PIPELINES中设置scrapy.pipelines.images.ImagesPipeline:1
![[mysql 基于C++实现数据库连接池 连接池的使用] 持续更新中](https://img-blog.csdnimg.cn/direct/4a9a02ef547d45dcb9e5094eb407ae6e.png)