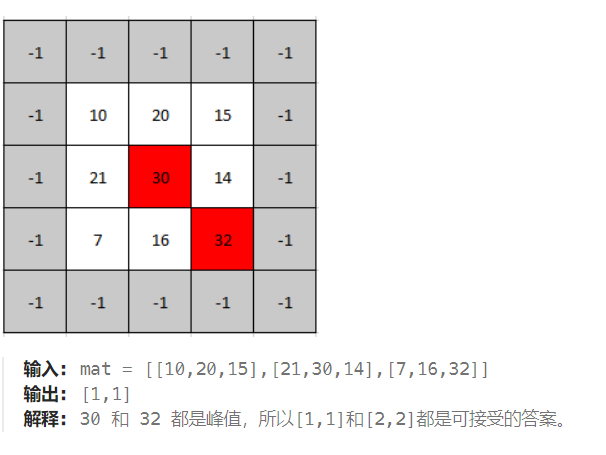
语义分割(Semantic Segmentation)是一种计算机视觉领域的任务,旨在将一张图像中的每一个像素都分配一个语义标签,即将图像中的每个物体区域进行精确的分类划分。例如,在一张街景图中,语义分割可以将人、车、路、天空等每个像素分别标记为不同的标签。语义分割可用于自动驾驶车辆、医学影像处理、机器人视觉以及图像搜索等领域。
本篇文章将从以下方面阐述语义分割的基本原理、应用场景、算法模型以及未来发展。
一、基本原理
在传统的图像处理领域中,常使用图像分割技术,将图像分成多个区域,并用不同的颜色或者纹理进行区分。而语义分割则是在此基础上,为每个像素分配一个特定的标记,即将每个像素都进行更加细致的分类。
语义分割的实现需要利用深度学习模型,根据所学习的表征,将像素映射到对应的语义类别。其中,使用卷积神经网络(Convolutional Neural Network, CNN)是实现语义分割的常用方法,通过在训练集上进行深度学习模型的训练,使其能够将输入图像中的每个像素映射到相应的语义类别。
二、应用场景
语义分割在很多领域都有广泛的应用,例如:
1.自动驾驶:语义分割可帮助自动驾驶车辆在道路上进行准确的车道线识别和行驶轨迹规划,提高行车的安全性。
2.医学影像处理:语义分割可应用于CT、MRI等扫描图像的处理,可以将影像中的不同组织区域进行有效的划分和分类,提高医生对病情的诊断准确性。
3.机器人视觉:语义分割对机器人视觉也有重要应用,在机器人的自主定位和运动规划方面发挥了关键的作用。
4.视频监控:语义分割可以加强视频监控系统的警戒能力,对监测对象进行类别识别、行为分析等工作,可以在城市管理、社会治安等领域中大大提升安全。
三、算法模型
目前,语义分割的算法模型主要分为两类:基于FCN的模型和基于Encoder-Decoder网络的模型。
1.基于FCN的模型:这种模型可以处理不同大小的输入图像,并输出与输入图像尺寸匹配的语义分割结果。比较典型的是U-Net和SegNet等。
2.基于Encoder-Decoder网络的模型:这种模型在语义分割中表现较好,通常分为两个阶段:编码阶段和解码阶段。编码阶段用于提取图像中的特征信息,解码阶段使用已编码的特征信息对像素进行分类。比较典型的是DeepLab和PSPNet等。
四、未来发展
随着深度学习技术的不断发展和计算机性能的不断提升,语义分割在未来的发展中会呈现以下趋势:
1.更高的准确度:随着深度学习模型在图像分割
任务中的应用,并逐步优化网络架构和训练方法,语义分割的准确度将会进一步提高。
2.实时性能的提升:目前语义分割算法的计算复杂度较高,导致实时性能有限。未来的发展将会着重于改善算法的效率,提高语义分割在实时场景下的表现。
3.融合多模态信息:除了图像数据,语义分割还可以融合其他感知信息,如激光雷达(LIDAR)和雷达(Radar)数据,以综合多种传感器的信息来提升语义分割的准确性和鲁棒性。
4.小样本学习:当前的语义分割算法在数据量较大的情况下表现良好,但在小样本场景下的表现有限。未来的发展将会关注如何利用少量标注样本进行高质量的语义分割。
5.领域自适应:通用的语义分割模型在不同地域、不同场景下的适应能力有限。未来的发展将着重于解决领域自适应的问题,使语义分割模型能够适应更广泛的场景和数据。
总结:
语义分割作为图像处理领域的重要任务,具有广泛的应用前景。通过深度学习模型的训练和优化,语义分割在自动驾驶、医学影像处理、机器人视觉和视频监控等领域发挥着关键作用。随着技术的不断发展,未来语义分割将在准确度、实时性能、多模态信息融合、小样本学习和领域自适应等方面取得进一步突破,为我们的生活和工作带来更多便利和应用价值。
MMsegmentation是一个基于PyTorch的图像分割工具库,它提供了多种分割算法的实现,包括语义分割、实例分割、轮廓分割等。MMsegmentation的目标是提供一个易于使用、高效、灵活且可扩展的平台,以便开发者可以轻松地使用最先进的分割算法进行研究和开发。