SM: streaming Multiprocessor 流多处理器
sm里面有多个(sp)cuda core
32个线程称为一个warp,一个warp是一个基本执行单元
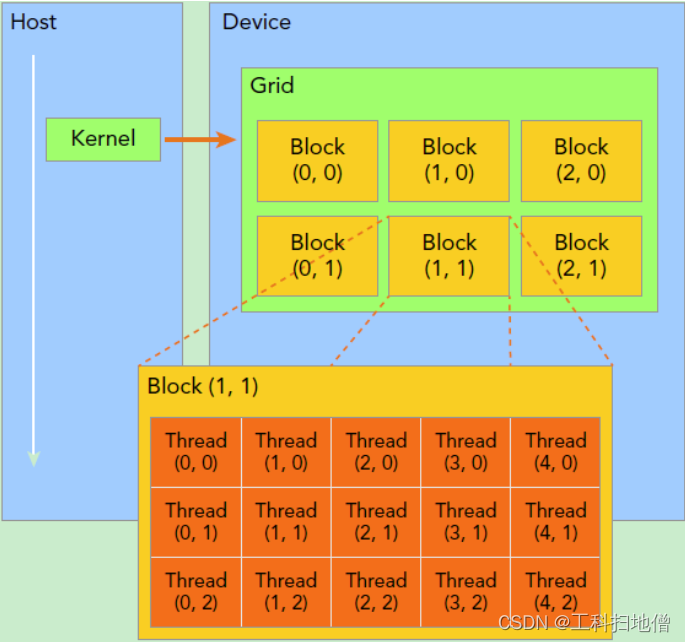
抽象概念:grid 网格 block 块 thread 线程
块中的线程大小是有讲究的,关乎到资源的调度,一般是128,256,512并且是32的倍数
Device:指的是 GPU 芯片。Grid:对应 Device 级别的调度单位,一组block,一个grid中的block可以在多个SM中执行。Block:对应 SM(Streaming Multiprocessor) 级别的调度单位,一组thread,同block中的thread可以协作。Thread:对应 CUDA Core 级别的调度单位,最小执行单元。
一个 thread 一定对应一个 CUDA Core,但是CUDA Core可能对应多个 thread。一个Block内的线程一定会在同一个SM(Streaming Multiprocessor,注意不是后面经常提到的Shared Memory)内,一个SM可以运行多个Block。每一个block内的thread会以warp为单位进行运算,一个warp对应一条指令流,一个warp内的thread是真正同步的,同一个warp内的thread可以读取其他warp的值
dim3 grid(3, 2);
dim3 block(5, 3);
kernel_fun<<< grid, block >>>(prams...);
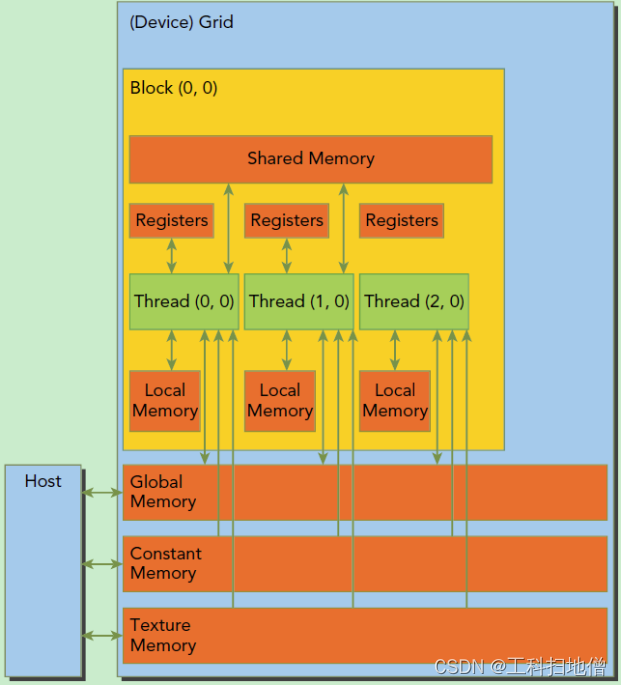
cuda的内存模型
典型的CUDA程序的执行流程如下:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
核函数用__global__符号声明,在调用时需要用<<<grid, block>>>来指定kernel要执行的线程数量
在CUDA中,每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量threadIdx来获得。
global:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。
device:在device上执行,单仅可以从device中调用,不可以和__global__同时用。
host:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译