项目场景:
复现文本摘要任务评估CNN/DM数据集
问题描述
abisee老哥的代码获取的是bin格式的数据集
时间久远,一些依赖的配置版本难以复现
笔者需要能评估Bart 格式的数据集
形式类似于test.source、test.source.tokenized
解决方案:
经过坚持不懈的爬楼找到了有用的生成代码,并且测试成功,故此记录一下
首先指路github地址
此处有更新后的预处理脚本
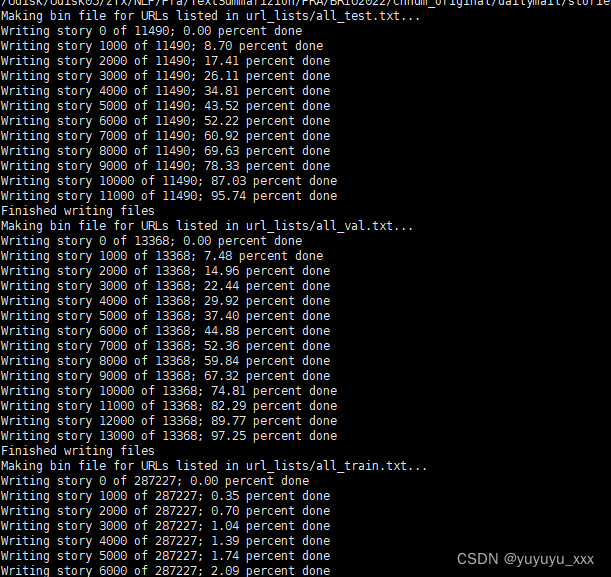
1 下载数据
从这里下载并解压缩CNN和每日邮报的 stories 目录。
2.处理为.source和.target文件
Run 运行
python make_datafiles.py /path/to/cnn/stories /path/to/dailymail/stories
将 /path/to/cnn/stories·替换为您保存下载的 cnn/stories 目录的路径;类似于dailymail/stories。
对于每个URL列表( all_train.txt 、 all_val.txt 和 all_test.txt ),从文件中读取相应的故事并将其写入文本文件 train.source 、 train.target 、 val.source 、 val.target 以及 test.source 和 test.target 。它们将被放置在新创建的 cnn_dm 目录中。
输出现在适合于馈送到BART微调的BPE预处理步骤。
3.完成后的结算画面