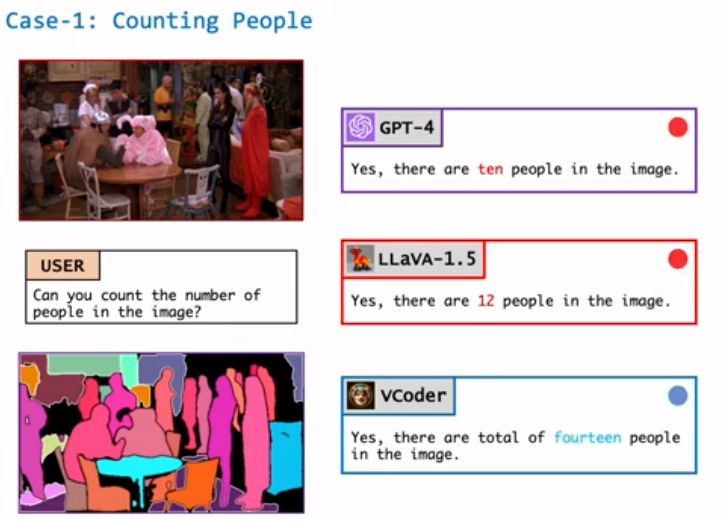
随着OpenAI推出ChatGPT,AIGC迎来了前所未有的发展机遇。大模型技术已经不仅仅是技术趋势,而是深刻地塑造着我们交流、工作和思考的方式。
本文介绍了笔者理解的大模型和AIGC的密切联系,从历史沿革到实际应用案例,再到面临的技术挑战和伦理监管问题,探讨这一技术浪潮如何引领我们进入一个智能化的未来。
前言
2022.11月30号OpenAI推出ChatGPT后随即爆火,五天注册用户数过百万,2个月用户破1亿,成为史上增长最快的消费者应用。随后各大厂也纷纷卷入AIGC领域,迎来国产GPT大模型发布潮(百度"文新一言"、阿里"通义千问"、商汤"商量 SenseChat"等)及AI创业公司成立潮(王小川、李开复等)。
大模型代表一个新的技术AI时代的来临,大模型展现出的强大的语义理解,内容生成以及泛化能力正在逐渐改变我们的工作与生活方式(AI+)、工作方式和思维方式。正如《陆奇的大模型观》所讲当前我们正迎来新范式的新拐点,从信息系统到模型系统过渡,"模型"知识无处不在。人工智能的浪潮正在引领新的技术革命,或许可称为第五次工业革命。
(【注】推荐大家去阅读《陆奇的大模型观》。强烈建议直接看陆奇演讲视频 奇绩创坛| 陆奇最新演讲完整视频|大模型带来的新范式:演讲涵盖陆奇对大模型时代的宏观思考,包括拐点的内在动因、技术演进、创业公司结构性机会点以及给创业者的建议。)
在人工智能的新时代,大模型技术正成为推动AIGC(人工智能生成内容)前沿的关键力量。本文将通过介绍我们的AIGC项目,来深入探讨这一技术的开发、实施与应用。因个人能力限制,文章中可能存在一些理解或表述错误的地方,希望各位大佬能及时批评和指正。
技术交流
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
大模型资料、数据、技术交流提升, 均可加知识星球交流群获取,群友已超过2000人,添加时切记的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:mlc2060,备注:技术交流
方式②、微信搜索公众号:机器学习社区,后台回复:技术交流

AIGC简介与发展历程
在与业务等交谈过程中,经常会听大家提到AIGC、ChatGPT、大模型、XX等许多概念,但也发现部分内容混淆。首先来解决下当下最火概念AIGC、ChatGPT、大模型到底是什么?
-
ChatGPT "Chat Generative Pre-trained Transformer”的缩写,ChatGPT是一种基于人工智能技术的聊天机器人,能用于问答、文本摘要生成、机器翻译、分类、代码生成和对话AI,是一款由OpenAI开发的基于Transformer架构的的自然语言处理工具。
-
AIGC,全名“AI generated content”,又称生成式AI,意为人工智能生成内容。狭义概念是利用AI自动生成内容的生产方式(UGC->PGC->AIGC);广义的AIGC可以看作像人类一样具备生成创造能力的AI技术,包括但不限于文本生成、音频生成、图像生成、视频生成及图像、视频、文本间的跨模态生成等等。
-
大模型:大模型通常是指参数量非常大的深度学习模型,如Transformer架构的GPT-3、BERT、T5等模型。这些模型通过在海量数据上进行训练,能够学习到丰富的语言和知识表示,并展现出强大的自然语言处理能力。
AIGC是一个更广泛的概念,包括多种类型的内容生成;ChatGPT则是一个具体的产品。简单可以这么理解:AIGC是平台,ChatGPT是平台上的某个软件。
结合人工智能的演进历程,AIGC发展大致分三个阶段[人工智能行业生成内容(AIGC)白皮书(2022年)(地址:https://www.vzkoo.com/document/20220907cc987d2511ffc7c895ed6dd4.html?spm=ata.21736010.0.0.56075d51YB56mA)]:
早期萌芽阶段(1950s-1990s),受限于当时的科技水平,AIGC仅限于小范围实验。
-
1957 年,莱杰伦·希勒和伦纳德·艾萨克森完成历史第一支由计算机创作的弦乐四重奏《伊利亚克组曲》。
-
1966年,约瑟夫·魏岑鲍姆和肯尼斯·科尔比开发了世界第一款可人机对话的机器人Eliza。
-
80年代中期,IBM基于(Hidden Markov Model,HMM)创造了语音控制打字机Tangora。
-
80年度末-90年度中,由于高昂系统成本无法带来可观的商业化变现,AIGC未取得重大突破。
沉淀积累阶段(1990s-2010s),AIGC从实验性向实用性逐渐转变。
-
2006年,深度学习算法取得重大突破,及图形处理器(GPU)、张量处理器(TPU)等算力设备性能不断提升,互联网规模膨胀提供海量训练数据,但AIGC仍受限算法效率,应用及效果有待提升。
-
2007年,世界第一部完全由人工智能创作的小说《1 The Road》问世,虽其可读性不强,但象征意义远大于实际意义。
-
2012年,微软公开展示了一个全自动同声传译系统,基于深层神经网络(Deep Neural Network,DNN)可以自动将英文演讲者的内容通过语音识别、语言翻译、语音合成等技术生成中文语音。
- 快速发展阶段(2010s至今)
快速发展阶段(2010s至今),深度学习模型不断迭代,AIGC突破性发展。
-
2014年,随着以生成式对抗网络(Generative Adversarial Network,GAN)为代表深度学习算法的提出和迭代更新,AIGC迎来了新时代,生成内容百花齐放,效果逐渐逼真直至人类难以分辨。
-
2017年,微软人工智能少女“小冰”推出了世界首部100%由人工智能创作的诗集《阳光失了玻璃窗》。
-
2018年英伟达发布了StyleGAN模型可以自动生成图片,目前已经发展到了第四代模型StyleGAN-XL,其生成的高分辨率图片让人难以分辨真假。
-
2019 年,DeepMind 发布了 DVD-GAN 模型用以生成连续视频,在草地、广场等明确场景下表现突出。
-
2021 年,OpenAI 推出了 DALL-E 并于一年后推出了升级版本 DALL-E-2,主要应用于文本与图像的交互生成内容,用户只需输入简短的描述性文字,DALL-E-2 即可创作 出相应极高质量的卡通、写实、抽象等风格的绘画作品。
-
2022年,12月OpenAI的ChatGPT在推出,两个月后用户数量就突破1亿了。在文本生成、代码生成与修改、多轮对话等领域,已经展现了大幅超越过去AI 问答系统的能力。
-
随后各大厂也纷纷卷入AIGC领域(百度“文新一言”、阿里“通义千问”、商汤“商量”SenseChat等),涌现运用AI于写作、编曲、绘画和视频制作等创意领域。目前 AIGC 技术可以自动生成文字、图片、音频、视频,甚至 3D模型和代码,在搜索引擎、艺术创作、影音游戏,以及金融、教育、医疗、工业等领域的应用前景十分广阔。
-
据 TBanic Date 估计,到 2025 年人工智能生成数据占比将达到 10%。
▐ 大模型与AIGC的关联
大模型(Large Models)与AIGC(人工智能生成内容)之间存在密切的关联,AIGC依赖于大型的人工智能模型来生成高质量的内容。它们是人工智能技术发展的两个重要方面。简单来说:
-
技术基础:大模型是实现AIGC的重要技术基础之一。大模型通常经过训练,以从海量数据中学习语言、图像或音频的模式。这些模型能够理解和模仿人类创作的风格和结构,从而在不同的领域中生成新的内容。例如,使用大模型可以生成文本、图像等内容,这些都是AIGC的核心应用场景。
-
性能提升:随着大模型的发展,其生成内容的能力也在不断提高,使得AIGC的质量更加逼真和丰富,从而拓展了应用范围。
-
协同工作:在某些情况下,大模型可能需要与其他技术(如计算机视觉或自然语言理解)结合使用,共同为AIGC服务。
-
产业影响:大模型的广泛应用推动了AIGC相关产业的发展,AIGC利用这些模型在媒体、娱乐、教育、科研和商业领域中创造价值。
总的来说,大模型和AIGC相互促进、共同发展,形成了一个紧密联系的技术生态系统。在这个系统中,大模型提供了底层的技术支持,而AIGC则代表了一种实际的应用形式。
大模型概述
▐ 大模型的定义和特点
大模型(Large Models)在人工智能(AI)和机器学习(ML)领域,通常指的是具有大量参数的(通常包含数百万到数十亿甚至更多的参数)、复杂计算结构和强泛化能力的机器学习模型。这类模型往往是基于神经网络,尤其是深度神经网络,包括但不限于深度卷积神经网络(CNNs)、循环神经网络(RNNs)、长短期记忆网络(LSTMs)和Transformer架构。
其主要特点包括:
-
大量参数:大模型拥有庞大的参数量,通常包含数百万到数十亿甚至更多的参数,远超过传统的小型模型。使其具备极高的表达能力,能够模拟和学习非常复杂的函数关系。
-
强大的学习能力:由于参数量巨大,这些模型具有强大的学习和泛化能力,能够在各种任务上达到或超越人类的表现。
-
大数据集&计算资源密集:为了训练这些模型避免过拟合,并充分利用其学习能力,需要大量的训练数据。且需要大量的计算资源进行训练,包括高性能硬件GPU集群和大量的电力。
-
预训练和微调:大多数大模型采用两阶段的学习过程,首先在大量的无标注数据上进行预训练,然后在特定任务的数据集上进行微调,以获得更好的性能。
-
自我监督学习:许多大模型通过自我监督学习来提高其泛化能力,这种学习方法不需要人工标签,而是让模型自己从输入数据中学习到有用的特征。
-
上下文敏感性:大模型在处理自然语言理解和生成任务时,能考虑到更多的上下文信息,从而生成更加准确和流畅的文本。因此在实践大模型过程中要尽可能输入足够的上下文信息来提高结果的准确度。
-
解释性的挑战:由于模型的复杂性,理解模型的决策过程和内部工作机制是具有挑战性的,这通常被称为模型的解释性或透明度问题。
▐ 典型大模型举例
国际:
| 组织 | 模型/应用 | 备注 |
OpenAI | GPT-1/GPT-2/GPT-3 |
|
OpenAI | GPT-4 |
|
LaMDA |
| |
PaLM-E |
| |
Meta | PaLM-A |
|
Meta | LLaMA |
|
微软 | Windows Copilot |
|
国内:
| 组织 | 模型/应用 | 备注 |
| 复旦大学 | MOSS |
|
| 阿里 | 通义千问 |
|
清华大学 | ChatGLM |
|
| 华为 | 盘古 |
|
商汤 | “商量”SenseChat |
|
腾讯 | 混元 |
|
科大讯飞 | 星火认知 |
|
百川智能 | Baichuan-7B、Baichuan-13B |
|
百度 | 文心一言 2023.10.17 文心大模型4.0正式发布 |
|
【注】更多模型可从huggingface模型平台查看 ;
huggingface国内镜像(地址:https://aliendao.cn/models#/)
总结来看:
-
模型演进方向:模型参数规模更大、多模态支持演进
-
技术成熟度:国内整体能力尚处在追赶GPT3.5阶段,部分中文能力上逼近GPT3.5(见下附图),与国外有一定差距
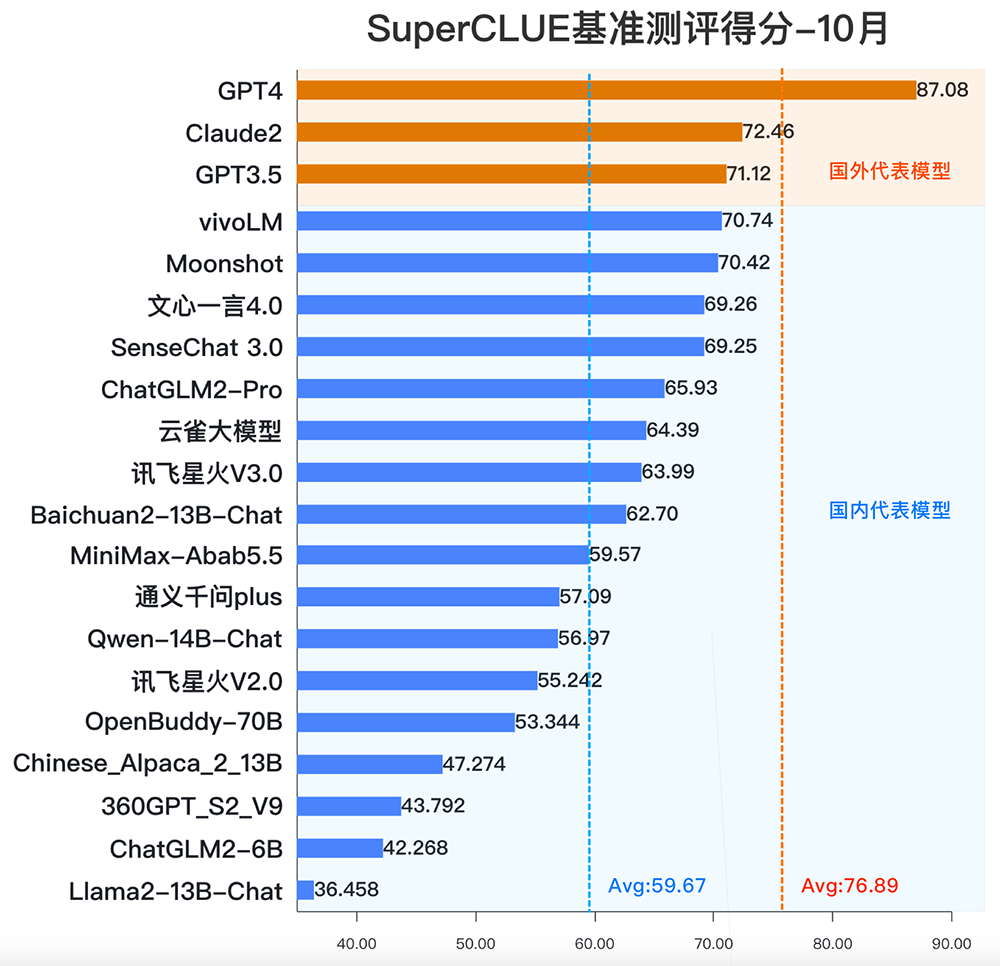
【附】中文能力上10月 SuperCLUE 评测排名
AIGC应用探索
▐ 业务背景
笔者所在业务存在多国家多语种的千万级别的海外特色供给,因多语种翻译、商品信息不足、供应商能力等问题导致大量商品属性缺失、图片素材质量低;导致用户理解难、转化低、万求高。面对极大品量,运营手动仅可补全少量头部商品,无法全量优化。在AI技术成熟的背景下,考虑采用AIGC的方式对商品的属性、卖点、素材图片、场景图等信息进行补全及优化。
▐ AIGC技术落地过程
作为一名业务技术开发,必须时刻围绕解决业务实际问题、技术创新驱动业务发展、快速响应市场变化等方面思考。在项目启动初期,我们首先基于探物香水标品场景2000个品批量AIGC素材,验证AIGC生产可行性。并经过多次脑暴探索,明确要做能够带来业务价值的、能够规模化的、能够突出国际垂类优势的AIGC应用。不做炫技的,落不了地的,没有业务感知的,不做通用的模型,算力(资源不允许)。
因此技术目标:搭建可复用可扩展、嵌入产供投链路的AIGC工程引擎;辅助业务快速落地AIGC场景。技术选型核心三步:1、模型底层选择;2、语言&框架选择;3、整体架构设计。
生文模型:初期我们采用GPT4、GPT3.5,后面也逐步引入了通义千问、vertex-PaLM2、claude2等。
生图模型:Stable Diffusion
成本方面估算:对于英文,1个token大约为4个英文字符或0.75个英文单词;对于中文,1中文约1-3个token。前期试验下来,探物品 cost=0.12元/品,是在业务可接受的范围。
测算token数网站:https://gpttools.com/estimator
综合开源社区活跃、可靠性,以及前期我们采用GPT模型适配度等多方面考虑,在模型层我们采用LangChain框架构建。
| 特点 | LangChain | Llama-Index | Semantic Kernel(微软) |
| 语言 | Python ;Js/Ts | Python | TypeScript |
可组合性 | 是 | 是 | 是 |
LLMs和Prompt管理 | 是 | 是 | 是 |
Chains(编排能力) | 是 | 否 | 是 |
数据索引处理 | 是 | 是 | 是 |
任务管理(agents) | 是 | 否 | 是 |
状态管理 | 是 | 否 | 是 |
Evaluation | 是 | 否 | 是 |
文档 | https://github.com/hwchase17/langchain https://langchain.github.io/ | https://github.com/microsoft/semantic-kernel https://learn.microsoft.com/en-us/semantic-kernel/ |
【注】这些框架的目的是为 LLM 交互创建一个底层编排引擎
LangChain是一个基于大型语言模型(LLMs)构建应用的框架。它的核心思想是定义标准接口(可以自定义实现)& 可以将不同的组件“链接”起来,创建更高级的LLMs应用 ,类似spring全家桶。它可以帮助你实现聊天机器人、生成式问答、文本摘要等功能。
| | langchain-java | |
生态繁荣度和可靠性 | 高,社区活跃,github 4.7W+star | 低,集团内部团队自建 |
扩展工具多样性 | 高度丰富的组件能力 | 极少 |
集团中间件兼容 | 和集团内部对接都需要进行框架层开发,比如hsf调用、数据库对接、服务化的能力 | 支持 |
集团容器兼容 | 支持 | 支持 |
集团LLM接口兼容 | 需要进行框架层对接,开发成本较低 | 有对接成本 |
开发成本 | python数据处理(爬取、清洗、标注)、大模型交互python性价比更高,可快速搭建试错 | 跟数据处理和大模型交互更重,试错周期长 |
文档 | langchain官网:https://python.langchain.com/en |
【语言选择】:python+java结合的方式:
-
核心LLM执行引擎层:langchain-python选型具备优势(数据处理、大模型交互python性价比更高,也可快速搭建试错)
-
上层能力层可以采用java工程搭建(偏业务交互)
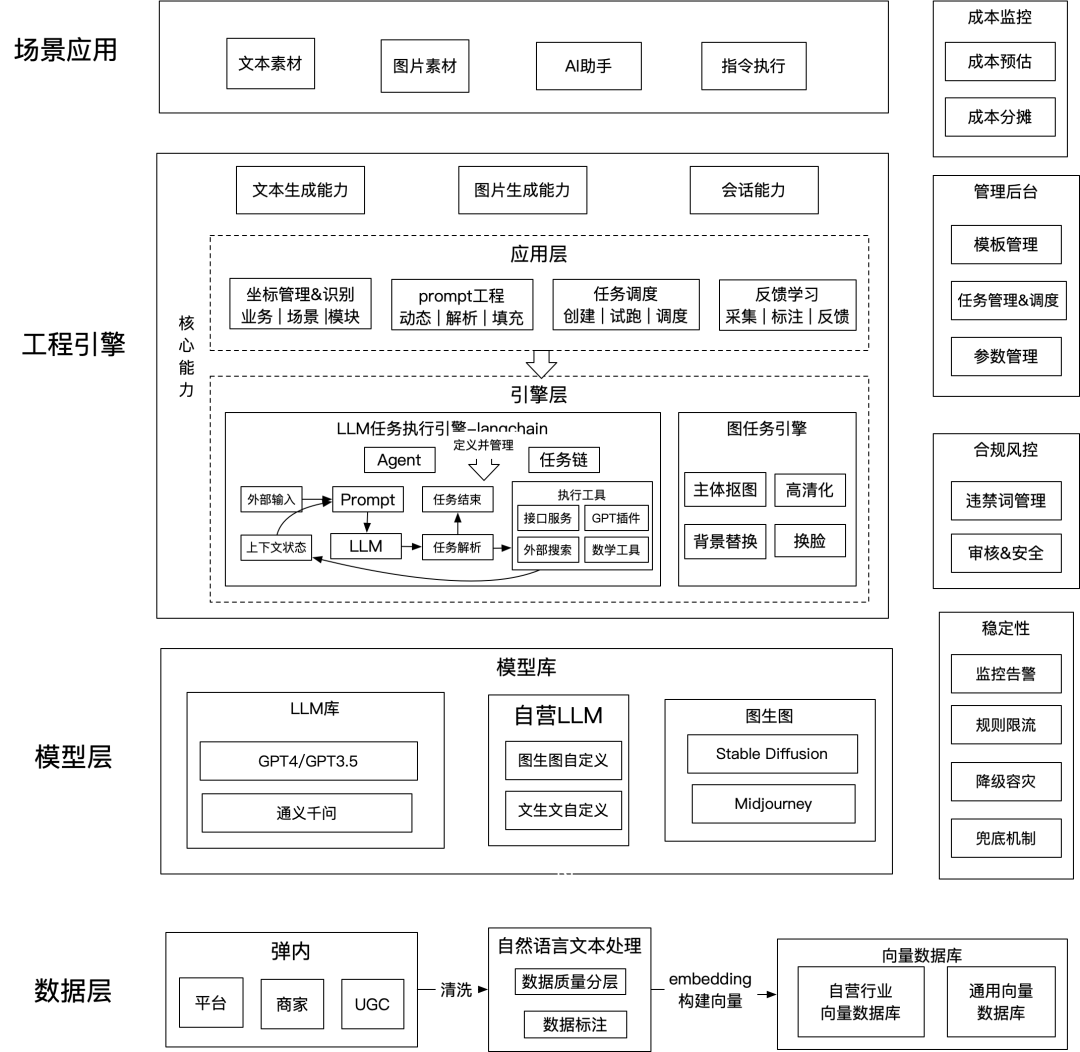
数据层:弹内/弹外数据->自然语言文本处理->国际自营行业向量数据库
模型层:依赖集团内部/国际自营大模型能力
工程引擎:横向通用能力视角(生文、生图、会话等),支撑上层业务场景&嵌入生产投放链路
-
LLM任务执行引擎层:基于langchain框架思想构建,将 LLM 模型与外部数据源进行连接,按场景编排链路,以及选择执行工具
-
图任务引擎:高清化能力、图像切割能力、背景替换合图能力
-
prompt工程能力:prompt模板定义(Instruction、Input Data、Output Indicator、requirements等),动态化模板解析&填充能力(具备外部输入+规则动态拼接能力,串联生产链路)
-
任务调度能力:支持业务excel/圈品等多方式任务创建、任务试跑(准确性校验&费用预估等)、DTS任务调度执行能力
▐ 部分实践案例
建设批量文生文AIGC工程引擎,具备prompt模板提示&自动填充、任务试跑预览、费用预估、批量化AIGC生产等能力。已应用素材文生文、商品咨询FAQ生产等场景。

建设图生图AIGC工程引擎,完成图片的超分处理、AI二创等工程建设,支持业务优化商品图片素材质量。已应用探物标品素材图生图等场景。

▐ 其他应用场景
下面是本人收集的一些应用场景case,希望给大家更多的思考启发。
外部公司应用场景更广,这里简单列举下:
-
AIGC+传媒:写稿机器人、采访助手、视频字幕生成、语音播报、视频锦集、人工智能合成主播等
-
AIGC+电商:商品3D模型、虚拟主播、虚拟货场等
-
AIGC+影视:AI剧本创作、AI合成人脸和声音、AI创作角色和场景、AI自动生成影视预告片等
-
AIGC+娱乐:AI换脸应用(如FaceAPP、ZAO)、AI作曲(如初音未来虚拟歌姬)、AI合成音视频动画等
-
AIGC+教育:AI合成虚拟教师、AI根据课本制作历史人物形象、AI将2D课本转换为3D
-
AIGC+金融:通过AIGC实现金融资讯、产品介绍视频内容的自动化生产,通过AIGC塑造虚拟数字人客服等
-
AIGC+医疗;AIGC为失声者合成语言音频、为残疾人合成肢体投影、为心理疾病患者合成医护陪伴等
-
AIGC+工业:通过AIGC完成工程设计中重复的低层次任务,通过AIGC生成衍生设计,为工程师提供灵感等。
AIGC的实践挑战
笔者在AIGC应用的初探,技术挑战与机遇并存。下面给大家分享下AIGC的实践挑战以及部分解决思路。
▐ 技术挑战
| 问题 | 描述 | 解决方案及思路 |
知识量有限 | | |
效果问题 | | |
延迟问题 | |
|
资源和性能 | | |
▐ 伦理和监管问题
随着大模型在AIGC中的广泛应用,它们引发了关于数据隐私、版权、内容监管和偏见等问题的讨论。因此,大模型的使用不仅涉及技术层面,还涉及伦理和法律层面。
| 问题 | 描述 | 解决方案及思路 |
安全与合规 | 如政治敏感、违法犯罪、伦理道德等问题,尤其是LLM直接面向C端场景 | 1、建设安全校验模块能力 3、C端:生成式大模型必须通过SFT、RLHF等微调技术对大模型做适配微调,对齐人类的价值观; |
政策问题 | 对于类GPT能力作为C端应用的开放程度需受限于政策 | 1、上线前需安全评估 |
【附】网信办411公布《生成式人工智能服务管理办法》征求意见稿,规范生成式人工智能产品(AIGC,如 ChatGPT)的开发和使用方式、行业的定义、对生产者的要求和责任等方面。意见稿中尤其提出:“利用生成式人工智能产品向公众提供服务前,应当按照《具有舆论属性或社会动员能力的互联网信息服务安全评估规定》向国家网信部门申报安全评估,并按照《互联网信息服务算法推荐管理规定》履行算法备案和变更、注销备案手续。
C端应用上线需要过“双新评估”:

AIGC的未来展望
业务侧规划:基于业务场景继续创新,扩大战果。更多还是聚焦基建和业务场景应用。
技术期待:AI大势浩浩荡荡,顺之者昌逆之者亡。YY几个未来的期待场景
-
增强的交互式AI:类似google最近发布的Gemini,改变当前信息交互方式,期待每个人都有专属钢铁侠中的人工智能“贾维斯”。
-
个性化和定制化内容:大数据+AIGC根据用户偏好、历史行为和实时反馈生成的个性化和定制化内容。
-
虚拟现实内容:AIGC多模态内容生成发展,图像、视频、音频等,未来说不定AI构建虚拟现实内容。
附录
-
langchain 官方文档 https://python.langchain.com/en/latest/getting_started/getting_started.html
-
langchain 快速入门中文版 https://github.com/liaokongVFX/LangChain-Chinese-Getting-Started-Guide
-
吴恩达llm教程 https://www.deeplearning.ai/short-courses/
-
GPT开发应用利器:LangChain https://zhuanlan.zhihu.com/p/630253274
-
LangChain使用调研 https://blog.csdn.net/benben044/article/details/130843326
-
openai 原始接口文档 https://platform.openai.com/docs/api-reference/completions