一、pandas介绍
1、2008年Wes McKinney(韦斯·麦金尼)开发出的库
2、专门用于数据分析的开源python库
3、以numpy为基础,借力numpy模块在计算方面性能高的优势
4、基于matplotlib能够简便的画图
5、独特的数据结构
6、也是三个单词组合而成:panel + data + analysis
面板数据 - 来源于计量经济学,通常用来存储三维的数据
二、为什么使用pandas
1、numpy已经能够帮助我们处理数据,能够结合matplotlib解决部分数据展示等问题,那么pandas用在什么地方
2、便捷的数据处理能力
3、读取文件方便
4、封装了matplotlib、numpy的画图和计算
三、核心数据结构
1、pandas三大数据结构
DataFrame、Panel、Series
四、DataFrame
1、DataFrame结构
既有行索引,又有列索引的二维数组
2、如何创建更有意义的数据
import numpy as np
# 创建一个符合正态分布的10个股票5天的涨跌幅数据
stock_change = np.random.normal(0, 1, (10, 5))stock_changeimport pandas as pd
# 加上行列索引
pd.DataFrame(stock_change)# 添加行索引
stock = ["股票%s" %str(i) for i in range (10)]pd.DataFrame(stock_change, index=stock)# 添加列索引
data = pd.date_range(start="20180101", periods=5, freq="B")datapd.DataFrame(stock_change, index=stock, columns=data)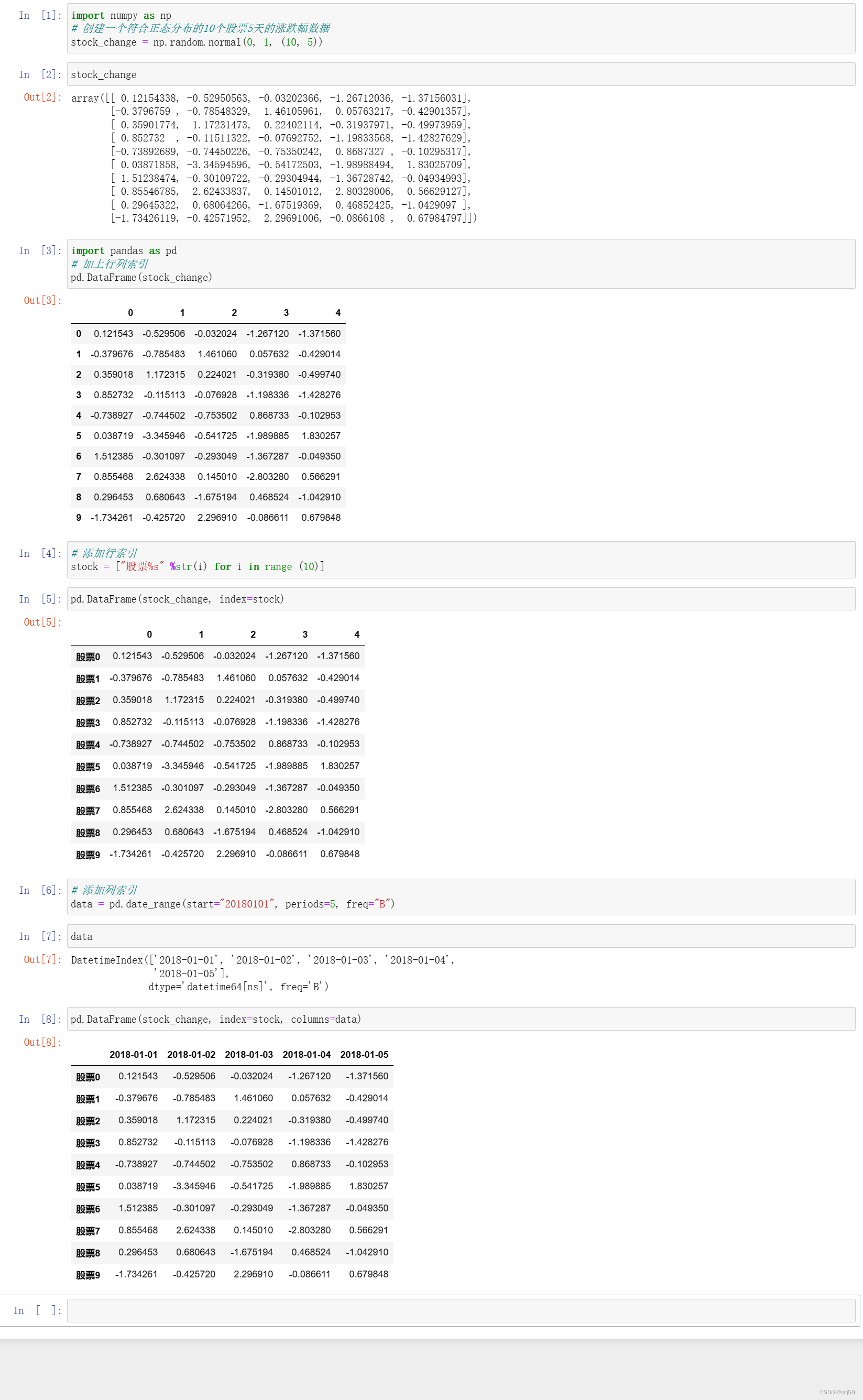
3、DataFrame对象既有行索引,又有列索引
行索引:表明不同行,横向索引,叫index
列索引:表明不同列,纵向索引,叫columns
4、DataFrame的属性
常用属性:
(1)shape
(2)index:DataFrame的行索引列表
(3)columns:DataFrame的列索引列表
(4)values:直接获取其中array的值(排除行索引列索引后的值,就是ndarray)
(5)T:行列的转置
常用方法:
head():前几行
tail():后几行