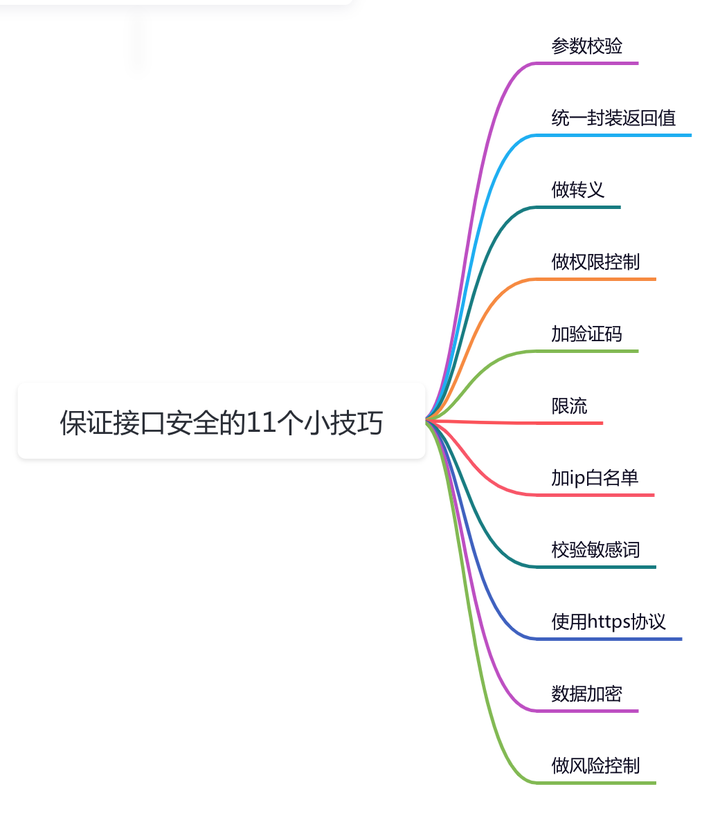
一、定义
自监督学习(SSL)是机器学习的一种范式,用于处理未标记数据以获取有用的表示,以帮助下游学习任务。SSL方法最显著的特点是它们不需要人类标注的标签,这意味着它的训练完全基于由未标记的数据样本组成的数据集。典型的SSL流程包括在第一阶段学习监督信号(自动生成的标签),这些监督信号将用于后续阶段中的某些监督学习任务。因此,SSL可以视为无监督学习和监督学习的中间形式。
自监督学习的核心思想是从输入数据中创建虚拟的监督信号,然后使用这些虚拟标签来训练模型。在训练过程中,模型根据虚拟标签进行优化,以学习数据中的有用特征和模式。这些虚拟标签可以是从原始数据中自动生成的,例如从图像中移除一部分内容并让模型预测缺失的内容,或者从文本中掩盖部分单词并让模型填补缺失的单词。
自监督学习主要是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。 也就是说,自监督学习不需要任何的外部标记数据,这些标签是从输入数据自身中得到的。
自监督学习的模式仍然是Pretrain-Fintune的模式,即先在pretext上进行预训练,然后将学习到的参数迁移到下游任务网络中,进行微调得到最终的网络。

二、方法
自监督学习的方法主要可以分为 3 类:
1. 基于上下文(Context based)
基于数据本身的上下文信息,可以构造很多任务,比如在 NLP 领域中Word2vec 主要是利用语句的顺序,例如 CBOW 通过前后的词来预测中间的词,而 Skip-Gram 通过中间的词来预测前后的词。;在图像中,图像拼图、图像修复、图像着色、图像旋转等任务都是典型的作为pretext的例子。
2. 基于时序(Temporal Based)
样本间具有很多约束关系,最能体现时序的数据类型就是视频了。例如,对于视频中的每一帧,其实存在着特征相似的概念,简单来说我们可以认为视频中的相邻帧特征是相似的,而相隔较远的视频帧是不相似的,通过构建这种相似(position)和不相似(negative)的样本来进行自监督约束。或者可以设计一个模型,来判断当前的视频序列是否是正确的顺序。
3. 基于对比(Contrastive Based)
对比约束,它通过学习对两个事物的相似或不相似进行编码来构建表征。通过构建正样本(positive)和负样本(negative),然后度量正负样本的距离来实现自监督学习,即样本和正样本之间的距离远远大于样本和负样本之间的距离,可以使用点积的方式构造距离函数,然后构造一个 softmax 分类器,以正确分类正样本和负样本。
https://zhuanlan.zhihu.com/p/108906502![]() https://zhuanlan.zhihu.com/p/108906502
https://zhuanlan.zhihu.com/p/108906502
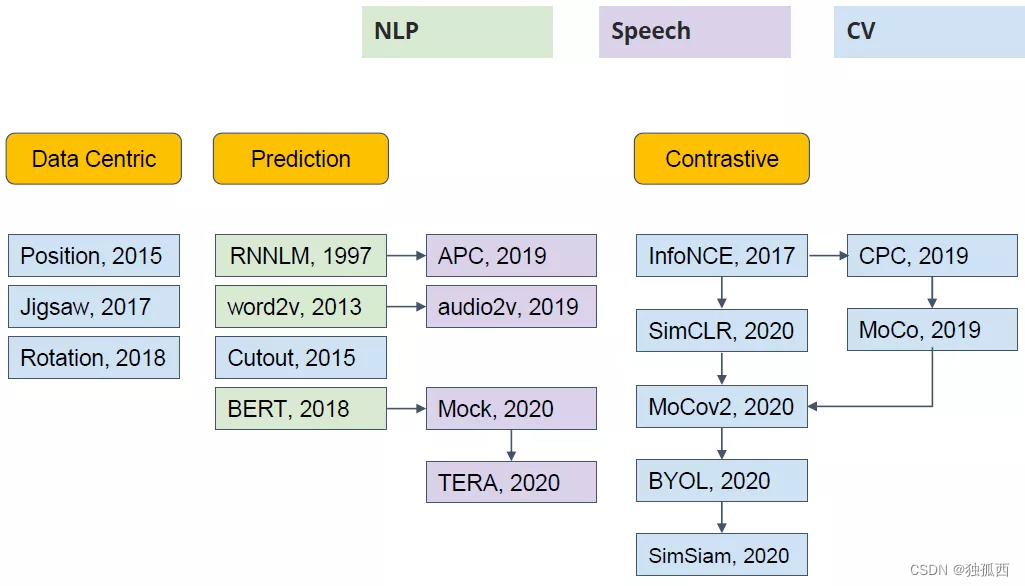
https://www.cnblogs.com/polly333/p/17791786.html![]() https://www.cnblogs.com/polly333/p/17791786.html自监督学习分类:
https://www.cnblogs.com/polly333/p/17791786.html自监督学习分类:
三、自监督VIO
- SelfVIO: Self-supervised deep monocular Visual–Inertial Odometry and depth estimation:GAN网络,位姿估计与深度估计组合进行,开源
- DeepVIO: Self-supervised Deep Learning of Monocular Visual Inertial Odometry using 3D Geometric Constraints:端到端的单目VIO,从双目中获取监督信息
- Vision-Aided Absolute Trajectory Estimation Using an Unsupervised Deep Network with Online Error Correction:VIOLearner,在网络训练过程中加入传统模型的引导,开源
- CodeVIO: Visual-Inertial Odometry with Learned Optimizable Dense Depth:通过原始图像和级联稀疏深度图预测稠密的深度图及其不确定度的编码网络+通过对深度信息进行编码得到用于 VIO 优化的深度向量的变分自编码器
- BoomVIO: bootstrapped monocular visual-inertial odometry with absolute trajectory estimation through unsupervised deep learning
- Unsupervised monocular visual- inertial odometry network
- Unsupervised Learning of Depth and Pose Based on Monocular Camera and Inertial Measurement Unit (IMU)
- Scale-Aware Visual-Inertial Depth Estimation and Odometry Using Monocular Self-Supervised Learning
- Attention Guided Unsupervised learning of Monocular Visual-inertial Odometry
- CoVIO: Online Continual Learning for Visual-Inertial Odometry
- Unsupervised Deep Visual-Inertial Odometry with Online Error Correction for RGB-D Imagery