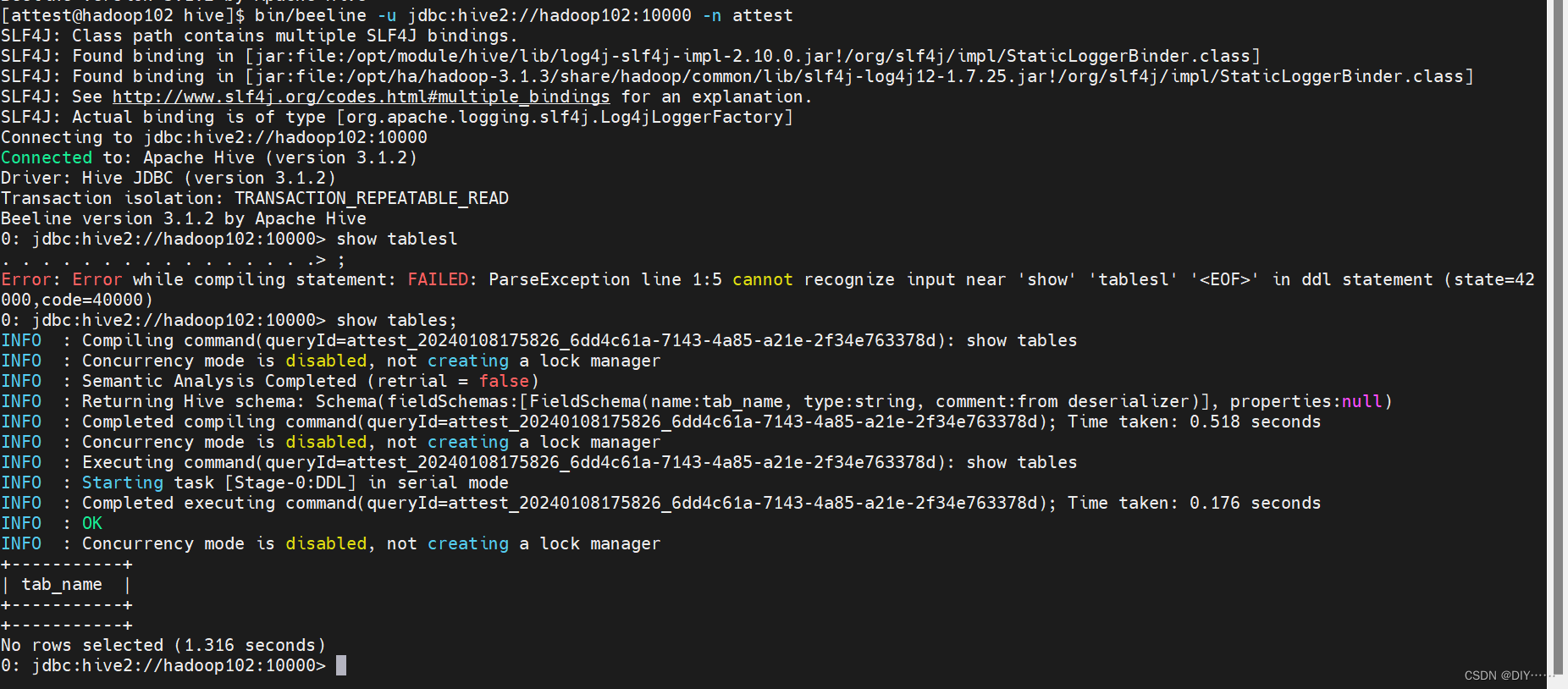
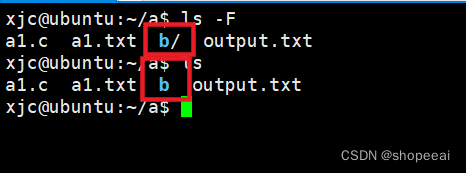
正则表达式RE
用来处理文本
正则表达式(Regular Expression, RE)是一种字符模式, 用于在查找过程中匹配指定的字符. 在大多数程序里, 正则表达式都被置于两个正斜杠之间;
例如/l[oO]ve/就是由正斜杠界定的正则表达式, 它将匹配被查找的行中任何位置出现的相同模式. 在正则表达式中,元 字符是最重要的概念
元字符使正则表达式具有处理能力。所谓元字符就是指ß那些在正则表达式中具有特殊意义的专用字符,可以用来规定 其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
正则表达式基本元字符
基本正则表达式元字符
元字符
示例 功能
^ 行首定位符
^love(匹配以love开头)
$ 行尾定位符
love$(匹配以love结尾)
. 匹配单个字符
l..e (匹配以中间为任何字符且l开头e结尾)
* 匹配前导符0到多次 全部匹配 grep "o*" /etc/passwd
ab*love(匹配ab开头love结尾)
.* 匹配任意多个字符 (贪婪匹配
[ ] 匹配方括号中任意一个字符
[lL]ove(匹配love或Love)
[ - ] 匹配指定范围内的一个字符
[a-z0-9]ove
[^] 匹配不在指定组里的字符
[^a-z0-9]ove
\ 用来转义元字符
love\.
\< 词首定位符 #由数字或字母组成的
\<love
\> 词尾定位符
love\>
正则表达式拓展元字符
= 等于 != 不等于 =~ 匹配
扩展正则表达式元字符
+ 匹配一个或多个前导字符
[a-z]+ove
? 匹配零个或一个前导字符
lo?ve
"r.*t" 贪婪匹配
-P "r.*?" 非贪婪匹配
a|b 匹配a或b
love|hate
() 组字符loveable|rs
love(able|rs) ov+ ov+ (ov)+
(oo)+ 两个oo出现一次或者多个
(..)(..)\1\2 标签匹配字符 #
(love)able\1er
x{m} 字符x重复m次
o{5}
o{,3} 字符最多出现3次
x{m,} 字符x重复至少m次
o{5,} 字符最少出现5次
x{m,n} 字符x重复m到n次
o{5,10} 字符o重复5到10次
shell 编程-grep
常见参数
egrep 支持正则表达式的拓展元字符 (或grep -E)
grep -v 除它
配合正则练习
例:
编辑文件lianxi.txt内容如下
Two roads diverged in a yellow wood,
And sorry I could not travel both
And be one traveler, long I stood
And looked down one as far as I could
To where it bent in the undergrowth;
Then took the other, as just as fair,
And having perhaps the better claim,
Because it was grassy and wanted wear;
Though as for that the passing there
Had worn them really about the same,
And both that morning equally lay
In leaves no step had trodden black.
Oh, I kept the first for another day!
Yet knowing how way leads on to way,
I doubted if I should ever come back.
I shall be telling this with a sigh
Somewhere ages and ages hence:
Two roads diverged in a wood,and I—
I took the one less traveled by,
And that has made all the difference.
1、从文本中查找包含字符串"yellow"的行
grep "yellow" lianxi.txt
2、从文本中查找包含字符串"travel"或"traveler"的行
egrep 'travel|traveler' lianxi.txt
3、从文本中查找以字母"T"开头的行
grep "^T" lianxi.txt
4、从文本中查找以字母";"结尾的行
grep ";$" lianxi.txt
5、从文本中查找包含单词"fair"的行
grep "<fair" lianxi.txt
6、从文本中查找以字母"i"和字母'e'结尾的行
grep "[ie]$" lianxi.txt
7、从文本中查找包含两个字母"o"的行
egrep "o{2}" lianxi.txt
8、从文本中查找包含三个或更多连续字母"o"的行
egrep "o{3,}" lianxi.txt
9、从文本中查找以大写字母开头的单词的行
grep "^[A-Z]" lianxi.txt
10、从文本中查找以小写字母开头的单词,但不包含大写字母的单词的行
egrep "^[a-z]" lianxi.txt | egrep -v [A-Z]
11、从文本中查找至少包含一个数字的行
grep "[0-9]" lianxi.txt
12、从文本中查找所有"n"的前导字符不是"i"和"k"的所有内容
egrep "[^ki]n" lianxi.txt
shell 编程-SED(流文本编辑器)
非交互式编辑器,一次处理一行内容。
sed "参数" '模式'
常用参数
-f 指定一个规则文件
-n 阻止输入行输出
-r 扩展正则
常用模式
s 替换
g 整行(也可以是数字,替换第几个)
d 删除
p 打印
a 追加
i 是插入#sed 's/新值/旧值/' 文件名
使用多重指令时用;隔开:
# sed 's/新值/旧值/; s/新值/旧值/' 文件名
使用脚本文件:
脚本:namestate
-f<script文件>或--file=<script文件> 以选项中指定的script文件来处理输入的文本文件。
$ sed -f namestate 文件名
保存输出:
$ sed -f namestate 文件名 > 对文件脚本后生成的新文件名
阻止输入行自动显示:
$ sed -n 's/MA/Massachusetts/p' file1.txt
sed流编辑器用法及解析
sed: stream editor(流编辑器)的缩写. 它们最常见的用法是进行文本的替换.
实用案例:
删除文件的第1行
#sed '1d' 文件名
删除文件的第1到2行
#sed '1,2d' 文件名
删除第2行到最后一行
#sed '2,$d' 文件名
匹配到root,删除此行
#sed '/root/d' 文件名
匹配到root行,到某一行
#sed '/root/,2d' 文件名
删除奇数行
#sed '1~2d' 文件名
删除偶数行
#sed '0~2d' 文件名
运用正则配合练习
拷贝/etc/passwd 文件到/opt下练习
cat -n /etc/passwd >> /opt/passwd
cd /opt/
1. 显示passwd文件的3-9行:
sed -n "3,9p" passwd
2. 显示包含oo字符串的行到包含gin字符串的行:
sed '/oo/,/gin/p' passwd
3. 在文件第一行添加haha,文件结尾添加yesyes:
sed -i '1i\haha' passwd
sed -i '$a\yesyes' passwd
4. 用hahaha替换oo,打印前20行:
sed -i 's/oo/hahaha/g' passwd
sed -n '1,20p' passwd
5. 删除空行和以#开头的行:
sed -i '/^$/d;/^#/d' passwd
6. 取出一个文件路径的目录名称:
echo $( cd $( dirname $0 ) ; pwd)
7. 在第8行下面插入hahaha第10行上面插入lalala:
sed -i '8a\hahaha;' passwd
sed -i '10i\lalala' passwd
8. 删除10到20行最后一个字符:
sed -i '10,20s/.$//g' passwd9. 文件中出现所有sbin都被替换成hahaha,只有发生变化的行才被打印:
sed -i "s/sbin/hahaha/gp" passwd
10. 解除文件注释,并删除4-6行:
sed -i 's/^#//g' passwd
sed -i '4,6d' passwd11. 删除1-3行并用root替换sbin:
sed -i '1,3d' passwd
sed -i 's/sbin/root/g' passwd
12. 删除1-8行并打印1-20行:
sed -i '1,8d' passwd -e sed -n '1,20p' passwd
13. 删除所有包含var的行:
sed -i '/var/d' passwd
14. 把10行以后的末尾加上cloud:
sed -i '10,$ s/$/cloud/g' passwd15. 打印第1到10行,删除5行后面所有的行:
sed -n '1,10p' passwd && sed -i '5,$d' passwd16. 将字符串/var替换成/hahaha,打印10,20行:
sed -i 's/var/hahaha/g' passwd && sed -n "10p;20p" passwd
shell 编程-AWK
awk是行处理器: 相比较屏幕处理的优点,在处理庞大文件时不会出现内存溢出或是处理缓慢的问题,通常用来格式化文本信息
awk处理过程: 依次对每一行进行处理,然后输出 默认分隔符是空格或者tab键
awk 参数 'BEGIN{处理之前要做的} {处理内容} END{处理之后的内容}
BEGIN{}
行处理前
{处理内容}
END{}
行处理 行处理后
awk工作原理
awk -F":" '{print $1,$3}' /etc/passwd
(1)awk使用一行作为输入,并将这一行赋给变量$0,每一行可称作为一个记录,以换行符结束
(2)然后,行被:分解成字段,每个字段存储在已编号的变量中,从$1开始
(3)awk如何知道空格来分隔字段的呢?因为有一个内部变量FS来确定字段分隔符,初始时,FS赋为空格或者是tab
(4)awk打印字段时,将以设置的方法,使用print函数打印,awk在打印的字段间加上空格,因为$1,$3间有一个,逗号。逗 号比较特殊,映射为另一个变量,成为输出字段分隔符OFS,OFS默认为空格
(5)awk打印字段时,将从文件中获取每一行,并将其存储在$0中,覆盖原来的内容,然后将新的字符串分隔成字段并进行处理。该过程持续到处理文件结束。默认分隔符是空格或者tab键
awk中的特殊变量:
常用:
- NR: 表示记录编号, 当awk将行为记录时, 该变量相当于当前行号
- NF: 表示字段数量, 当awk将行为记录时, 该变量相当于当前列号
难理解:
FS(输入字段分隔符) # 以什么符号去分割
OFS(输出字段分隔符) # 以什么分隔符显示
NR(Number of record)行数
FNR按不同的文件分开
RS(输入记录分隔符)
ORS(输出记录分隔符)
NF 字段个数
AWK实用理解案例
拷贝/etc/passwd 文件到/opt下练习
cat -n /etc/passwd >> /opt/passwd
cd /opt/1. 打印文件中的第2列和第3列
awk '{ print $2, $3}' passwd
2. 打印3行指定列的第7列字符
awk -F":" 'NR==3{ print $7 }' passwd
3. 统计文件的行数
awk '{ print NR}' passwd
4. 在脚本中, 传递变量到awk中
var=1000
echo | awk -v VARIABLE=$var '{ print VARIABLE }'
5. 指定字段分隔符-F或在BEGIN{ FS=":" }
$ awk -F: '{ print $2, $3 }' passwd
$ awk 'BEGIN{ FS=":" }{ print $2, $3 }' passwd
6. 在awk中使用for循环 (了解)
每行打印两次
# awk -F: '{for(i=1;i<=2;i++) {print $0}}' passwd
root:x:0:0:root:/root:/bin/bash
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
分别打印每行每列
# awk -F: '{ for(i=1;i<=NF;i++) {print $i}}' passwd
7. 在awk中使用if条件判断 (了解)
显示管理员用户名
awk -F: '{if($3==0) {print $1 " is administrator."}}'passwd
统计系统用户
awk -F":" '{if($3>0 && $3<1000){i++}} END{print i}' /passwd




![基于博弈树的开源五子棋AI教程[3 极大极小搜索]](https://img-blog.csdnimg.cn/direct/f6b6876dbfc04c6ab5611af858b4704a.png)