| Category | Content |
|---|---|
| 论文题目 | MM-VID: Advancing Video Understanding with GPT-4V(ision) |
| 作者 | Kevin Lin, Faisal Ahmed, Linjie Li, Chung-Ching Lin, Ehsan Azarnasab, Zhengyuan Yang, Jianfeng Wang, Lin Liang, Zicheng Liu, Yumao Lu, Ce Liu, Lijuan Wang (Microsoft Azure AI)
另一篇论文:EgoVLP: https://arxiv.org/pdf/2206.01670.pdf EgoVLPv2:https://github.com/facebookresearch/EgoVLPv2 他的主页:https://github.com/QinghongLin 他也是VLog的作者。以及 UniVTG 的作者。 |
| 发表年份 | 2023 |
| 摘要 | 提出了MM-VID,一个综合系统,结合了GPT-4V和专门的视觉、音频和语音工具,以促进高级视频理解。MM-VID旨在应对长篇视频和复杂任务的挑战,如在长时间内容中进行推理和理解跨越多集的故事情节。MM-VID使用GPT-4V进行视频到脚本的生成,将多模态元素转录为长文本脚本,从而为大型语言模型(LLM)实现视频理解铺平了道路。 |
| 引言 | 探讨了如何理解长视频,特别是那些跨越一个小时以上的视频。这是一个复杂的任务,需要能够分析图像和音频序列的高级方法。这一挑战还包括从各种来源提取信息,如区分讲话者、识别角色和维持叙事连贯性。 |
| 主要内容 | MM-VID包括四个模块:多模态预处理、外部知识收集、剪辑级视频描述生成和脚本生成。我们详细描述了每个模块。MM-VID从输入的视频文件开始,输出描述视频内容的脚本,使LLM能够实现各种视频理解功能。 |
| 实验 | 基于MM-REACT代码库实现了MM-VID,并使用Azure Cognitive Services API提供的自动语音识别(ASR)工具,以及PySceneDetect进行场景检测。我们讨论了MM-VID的不同能力,例如基于脚本的问答、多模态推理、长时视频理解、多视频集分析、角色识别、扬声器识别和音频描述生成等。我们还进行了用户研究,探索了MM-VID对视觉障碍人群的潜力。 |
| 结论 | 介绍了MM-VID,一个与GPT-4V协同工作的系统,用于推进视频理解。MM-VID利用GPT-4V将视频内容转录成长而详细的脚本,从而丰富LLM的高级视频理解能力。实验结果表明MM-VID在处理挑战性任务方面的有效性,包括理解长达一小时的视频、跨多集的分析、识别角色和发言者以及与视频游戏和图形用户界面的互动。此外,我们进行了广泛的用户研究,从不同用户群体那里收集反馈。 |
| 阅读心得 |
首先,这篇文章没有代码。 就是提出了一个整合体,把几个模型(主要是两个预处理工具+GPT4v+GPT4)整合起来用来给一个video生成脚本。 运行的话估计是和VLog那个repo一样,需要online的调用openai接口服务(api_key). 分5步实现: step1: pre-processing - scene detection (使用工具PySceneDetect,一个视频处理工具可以检测一些场景切换,剪辑等内容) step2: pre-processing - automatic speech recognition (ASR) (语音处理工具) step3: The input video is then split into multiple clips according to the scene detection algorithm (分割整个video为小片段10s) step4: employ GPT-4V, which takes the clip-level video frames as input and generates a detailed description for each video clip step5: GPT-4 is adopted to generate a coherent script for the full video, conditioning on the clip-level video descriptions, ASR, and video metadata if available |
【PaperReading】2. MM-VID

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/237145.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
git ssh key 配置
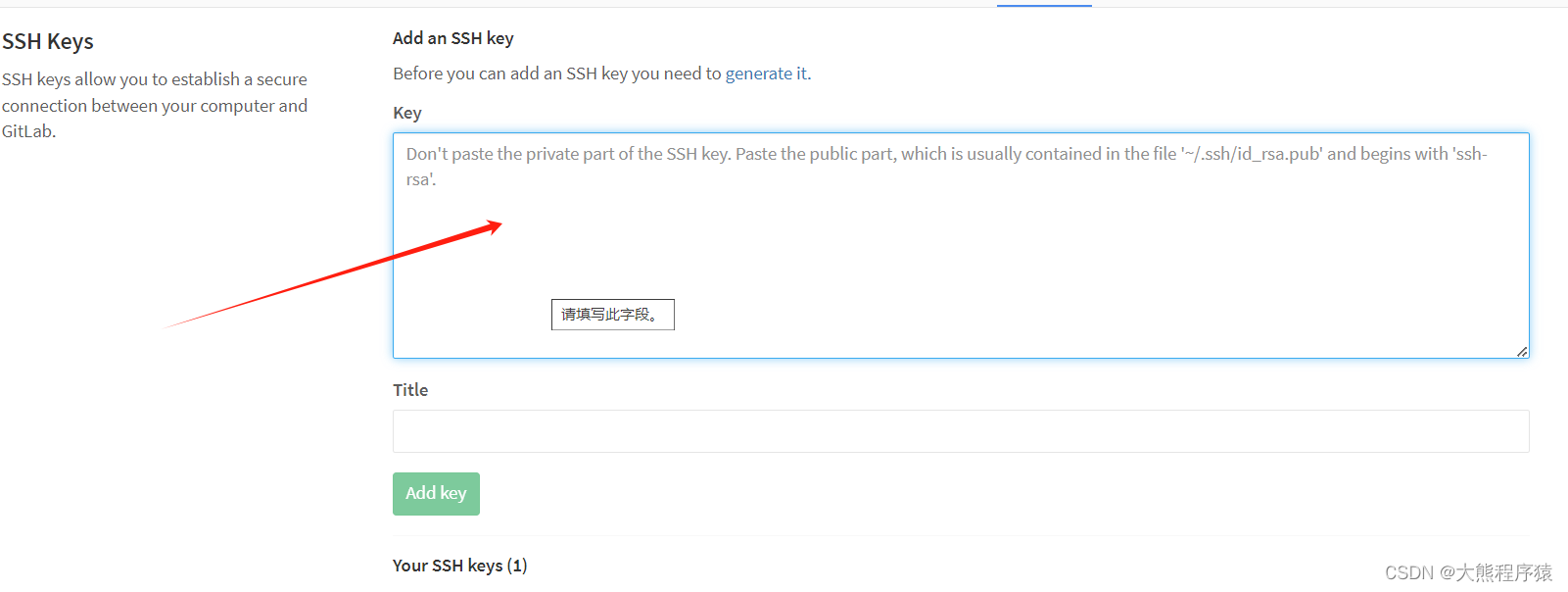
一、Profile Settings-->SSH Keys
我们点击这里会有详情的文档介绍生成sshkey。 ssh-keygen -t rsa -b 2048 -C "邮箱" --回车... 将生成的id_rsa.pub粘贴到如下保存 git config --global user.name "用户名"
git config --global user.email "邮…

SpringBoot使用MockMVC单元测试Controller
对模块进行集成测试时,希望能够通过输入URL对Controller进行测试,如果通过启动服务器,建立http client进行测试,这样会使得测试变得很麻烦,比如启动速度慢,测试验证不方便,依赖网络环境等&#…
Unity中Shader面片一直面向摄像机
文章目录 前言一、实现思路1、 我们要实现模型面片一直跟着摄像机旋转,那么就需要用到旋转矩阵2、确定 原坐标系 和 目标坐标系3、确定旋转后坐标系基向量二、确定旋转后 坐标系基向量 在 原坐标系 下的值1、Z轴基向量2、假设Y轴基向量 和 世界空间下 的Y轴方向一致竖直向上3、…

视频剪辑方法:智能转码从视频到图片序列,高效转换攻略
在视频编辑和后期处理中,经常要将视频转换为图片序列,以便进行单独编辑或应用。下面一起来看云炫AI智剪如何批量智能转码的方法,高效地将视频转换为图片序列。 视频转为序列图片缩略图效果
视频转为序列图片的效果图,画面清晰&a…

单例模式的八种写法、单例和并发的关系
文章目录 1.单例模式的作用2.单例模式的适用场景3.饿汉式静态常量(可用)静态代码块(可用) 4.懒汉式线程不安全(不可用)同步方法(线程安全,但不推荐用)同步代码块…
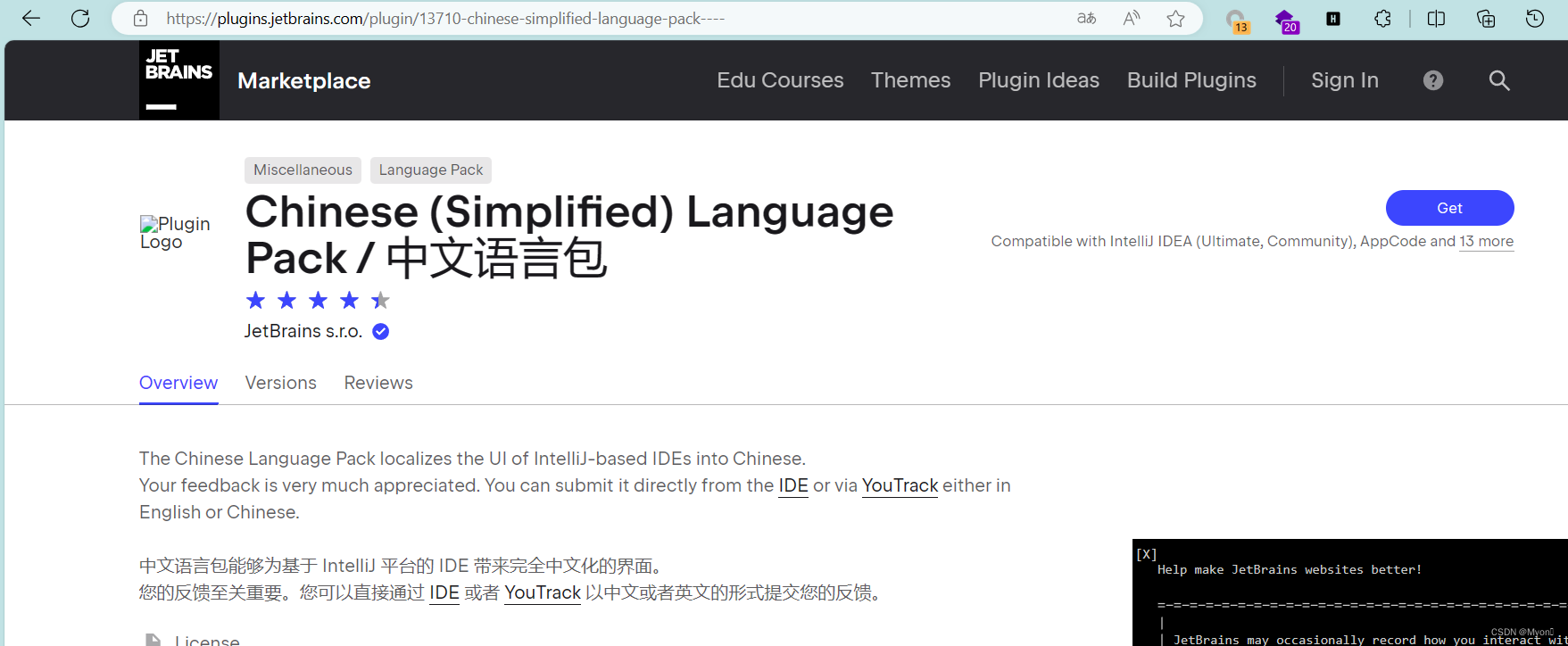
关于PhpStorm的安装激活与汉化
访问官网下载PhpStorm
https://www.jetbrains.com/phpstorm/download/#sectionwindows 点击download 下载好后,双击exe安装程序
点击下一步 选择安装位置 前两个肯定需要勾选:
创建桌面快捷方式;创建关联php;
根据以往经验&am…

canvasdrawer 微信原生小程序生成海报图片
在小程序中生成海报是一种非常有效的推广方式
用户可以使用小程序的过程中生成小程序海报并分享给他人
通过海报的形式,用户可以直观地了解产品或服务的特点和优势
常见绘制海报方式
目前,小程序海报有两种常见的实现方式: canvas 绘制…

LTESniffer:一款功能强大的LTE上下行链路安全监控工具
关于LTESniffer
LTESniffer是一款功能强大的LTE上下行链路安全监控工具,该工具是一款针对LTE的安全开源工具。
该工具首先可以解码物理下行控制信道(PDCCH)并获取所有活动用户的下行链路控制信息(DCI)和无线网络临时…

【iOS】数据持久化(四)之FMDB基本使用
正如我们前面所看到的,原生SQLite API在使用时还是比较麻烦的,于是,开源社区就出现了一系列将SQLite API进行封装的库,其中FMDB的被大多数人所使用
FMDB和SQLite相比较,SQLite比较原始,操作比较复杂&#…
POI:对Word的基本操作
1 向word中写入文本并设置样式
package com.example;import org.apache.poi.xwpf.usermodel.*;import java.io.File;
import java.io.FileOutputStream;/*** Author:xiexu* Date:2024/1/12 23:54*/
public class WriteWord {static String PATH "…

数据库:如何取消mysql的密码
因为调试MySQL数据接口,总是需要输入密码很烦,所以决定取消mysql的root密码,
网上推荐的有两种方法:
1、mysql命令
SET PASSWORD FOR rootlocalhostPASSWORD();
2、运行 mysqladmin 命令
mysqladmin -u root -p password
…
逼格满满,推荐一个高效测试用例工具:XMind2TestCase !
一、背景 软件测试的核心是什么?毫无疑问是测试分析和测试用例设计,也是日常测试投入最多时间的工作内容之一。
然而,传统的测试用例设计过程有很多痛点:
1、使用Excel表格进行测试用例设计,虽然成本低,但…
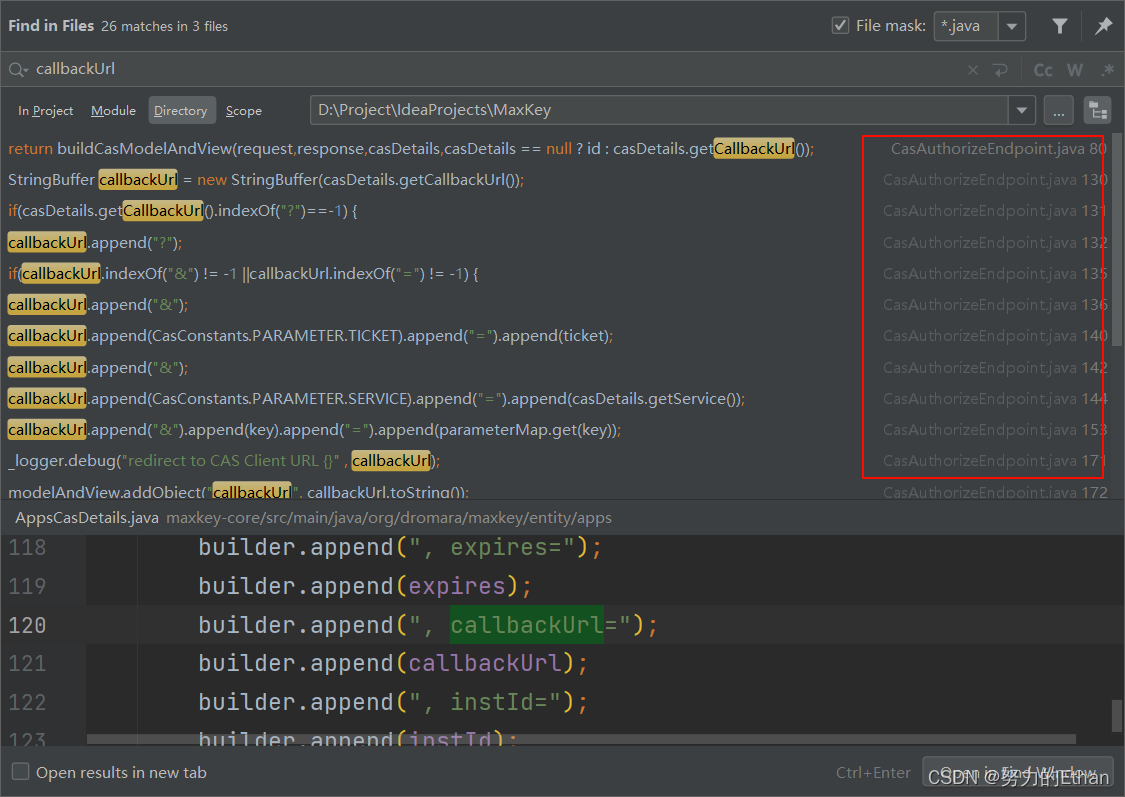
MaxKey 单点登录认证系统——实现登录后自动跳转及分析思路
Maxkey单点登录系统集成业务系统应用之后,登录界面登录之后不会自动跳转业务系统,需要在首页点击相应应用之后,才能实现跳转业务系统,故以下本人提供解决方法和分析思路。 环境配置
本例使用的是CAS协议实现单点登录
Maxkey 服务…

Golang的API项目快速开始
开启一个简单的API服务。
golang的教程网上一大堆,官网也有非常详细的教程,这里不在赘述这些基础语法教程,我们意在快速进入项目开发阶段。
golang好用语法教程传送门: m.runoob.com/go/ 编写第一个API 前提:按照上一…

麒麟操作系统缓存rpm包,制作离线yum源
缓存rpm包,以make为例
mkdir -p /data/yum
yumdownloader --resolve --destdir/data/yum make制作离线yum包
yum install createrepo -y
cd /data/yum
createrepo .写yum配置文件/etc/yum.repos.d/local.repo
[local-repo]
namelocal-repo
baseurlfile:///data/…

python_selenium零基础爬虫学习案例_知网文献信息
案例最终效果说明: 去做这个案例的话是因为看到那个博主的分享,最后通过努力,我基本实现了进行主题、关键词、更新时间的三个筛选条件去获取数据,并且遍历数据将其导出到一个CSV文件中,代码是很简单的,没有…
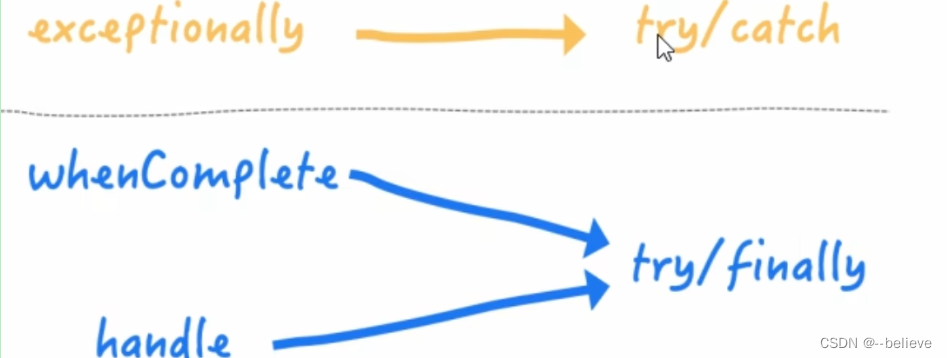
JUC之CompletableFuture
Future接口理论
Future接口定义了异步任务执行的一些方法,包括异步任务执行结果,异步任务执行是否中断,异步任务是否完毕等。
Future接口常用实现类FutureTask异步任务 FutureTask<String> futureTask new FutureTask<String>…

debian12部署Gitea服务之二——部署git-lfs
Debian安装gitlfs:
先更新下软件包版本
sudo apt update
安装
sudo apt install git-lfs
验证是否安装成功
git lfs version
cd到Gitea仓库目录下
cd /mnt/HuHDD/Git/Gitea/Repo/hu/testrepo.git
执行lfs的初始化命令
git lfs install客户机Windows端在官网下载并安装Git-Lfs
再…
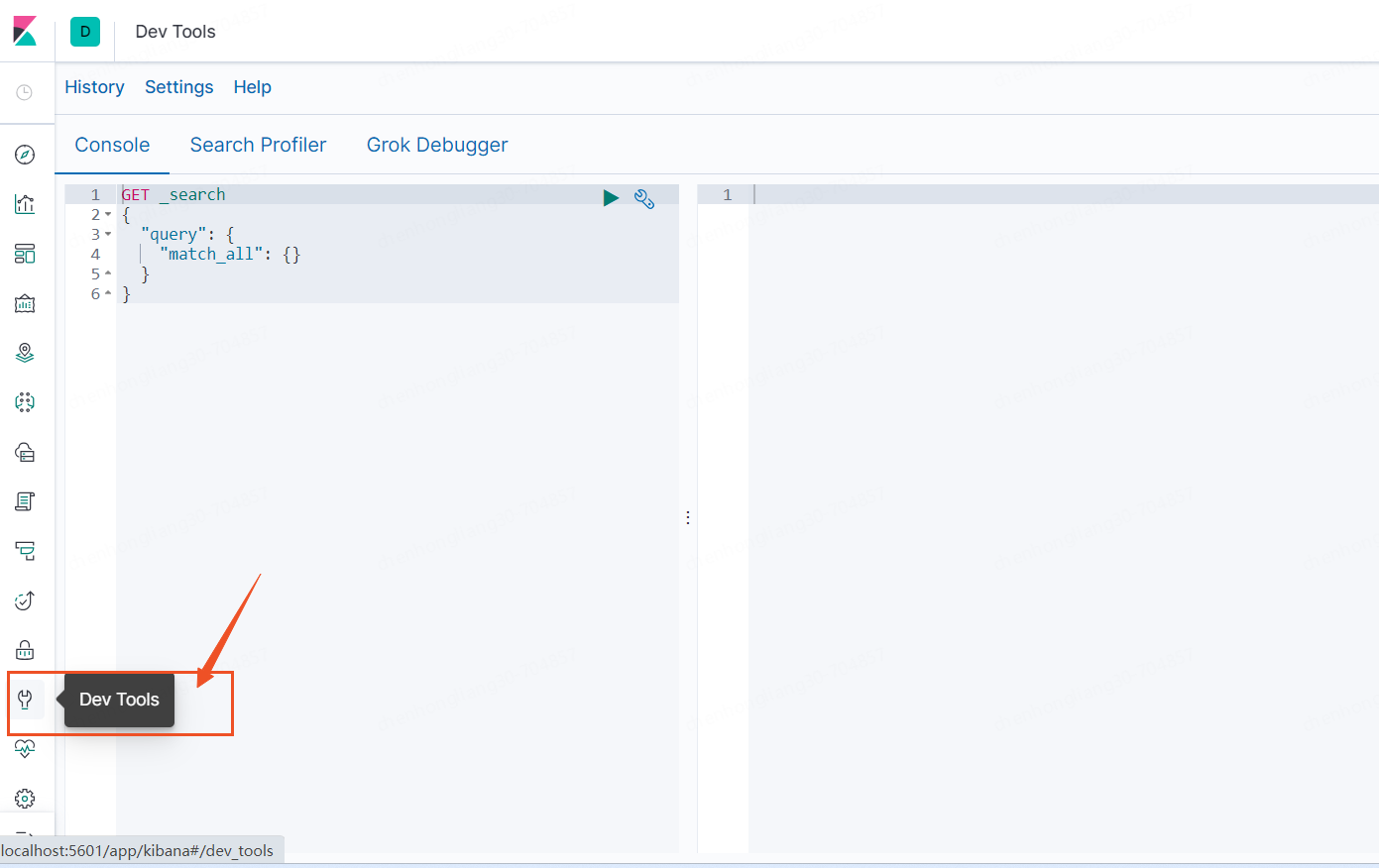
Elasticsearch windows开箱即用【记录】
一、准备工作
安装ES之前要在本机安装好JDK,对应的兼容性见官网链接:https://www.elastic.co/cn/support/matrix
ES官网链接:https://www.elastic.co/cn/,
我本机安装的是JDK8,测试使用的是7.3.0版本的ES和Kibana。
1、首先去…
iOS Universal Links(通用链接)详细教程
一:Universal Links是用来做什么的?
iOS9.0推出的用于应用之间跳转的一种机, 通过一个https的链接启动app。如果手机有安装需要启动的app,可实现无缝跳转。如果没有安装,会打开网页。
实现场景:微信链接无…
推荐文章
- 蔚来自动驾驶,从 2020 年开始讲起的故事
- 央视新闻曝光TR外汇平台诈骗案,涉案金额高达5亿元
- #P0564. 数组元素查找升级版
- #QT(串口助手-实现)
- #电子电器架构 —— 车载网关初入门
- #经典论文 异质山坡的物理模型 2 有效导水率
- (38)MATLAB分析带噪信号的频谱
- (iFlyCode、FREEGPT、Copilot、AIPlus、稳定高效)分享好用的ChatGPT
- (LdAiChat、Ai Loading、不墨AI助手、360AI搜索、TIG AI)分析好用的ChatGPT
- (二)正点原子STM32MP135移植——TF-A移植
- (高阶) Redis 7 第20讲 数据类型 源码篇
- (官网安装) 基于CentOS 7安装MangoDB和MangoDB Shell