写在前面,AnomalyGPT训练试跑遇到的坑大部分好解决,只有在保存模型失败的地方卡了一天才解决,本来是个小问题,昨天没解决的时候尝试放弃在单卡的4090上训练,但换一台机器又遇到了新的问题,最后决定还是回来踏踏实实填坑了。
准备数据:(根据官方的提示直接准备就好)
Prerequisites: Before training the model, making sure the environment is properly installed and the checkpoints of ImageBind, Vicuna and PandaGPT are downloaded.
AnomalyGPT训练配置:
一张4090 24g显存,33g内存,batchsize8,cuda12.2 ,torch2.1.2(安装环境的时候也可以把requirements.txt的版本号都去掉,默认都装最新的)
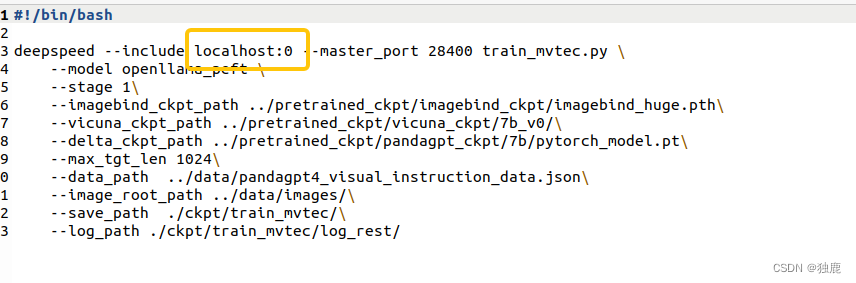
问题1:报错localhost
raise ValueError(f"No slot '{slot}' specified on host '{hostname}'")
ValueError: No slot '1' specified on host 'localhost'
解决办法:原因是我电脑只有一张显卡,默认配置是两张,在脚本AnomalyGPT/code/scripts/train_mvtec.sh里改一下就好了;
问题2:scikit-image报没有安装
解决办法:安装一下
pip install scikit-image问题3:deepseed版本不对
解决办法:requirements.txt里默认deepseed版本为deepspeed==0.9.2,我电脑需要至少0.9.3的版本,重新安装一下
pip install deepspeed==0.9.3问题4:loraconfig找不到
解决办法:AnomalyGPT/code/model/openllama.py中加
from peft import LoraConfig, TaskType, get_peft_model问题5:被kill
解决办法:cpu不够的时候不要开浏览器,不用开vscode等一切可能抢cpu的程序或应用,就小心翼翼开个terminal在里面进行训练。
问题6:NameError: name 'LlamaTokenizer' is not defined
解决办法:AnomalyGPT/code/model/openllama.py中加
from transformers import LlamaTokenizer正常训练起来的样子:

问题7:保存模型的时候报错TypeError: cannot pickle 'torch._C._distributed_c10d.ProcessGroup' object

解决办法:保存出错是因为我cpu内存小,所以加载预训练的时候将模型参数加载到了gpu上(具体操作参考上一篇web_demo.py试跑),保存的时候需要参数在cpu上才行(为什么这样?后面看一下细节再解答)。
正常训练跑成功及模型保存成功的样子:

参考文献:
GitHub - CASIA-IVA-Lab/AnomalyGPT: The first LVLM based IAD method!
工业异常检测AnomalyGPT-Demo试跑-CSDN博客