作者 | Chris
导读
本文讲述为了提升产运侧数据观察、分析、决策的效率,支持业务的快速迭代,移动生态数据研发部对数仓建模与BI工具完成升级,采用宽表建模与TDA平台相结合的方案,一站式自助解决数据应用需求。在此过程中,数据交付模式发生了变革,从研发定制化开发到产运自助化获取开始转变,业务侧数据获取更加方便、快捷、准确。
全文3540字,预计阅读时间9分钟。
01 背景与目标
1.1 背景
大数据时代,基于海量数据分析、挖掘高价值信息,用于指导、驱动业务快速发展,是数据建设的基础能力及价值体现。
数据驱动业务,一方面需要我们构建全面、准确、及时、易用的数据仓库,另一方面也需要建设统一的数据可视化平台,集成adhoc查询、数据分析、数据报表等应用能力,让业务高效、便捷、准确的获取数据,赋能业务增长。
业界内通常采用分层模型构建数仓,从ODS>DWD>DWS>ADS逐层建模,通过定制化的开发ADS层来满足业务侧需求。该模式下,复杂多变的业务场景都需要数据研发进行参与,数据获取时间依赖开发侧排期,定制化的结果不够灵活需要频繁迭代,ADS层占用数据研发的时间占比较高。随着业务发展越来越快,数据需求大量增加,所需的人力成本增加、交付效率降低。因此,需要探索新的数据开发交付模式,完成从研发定制化开发到产运自助化获取的转变。
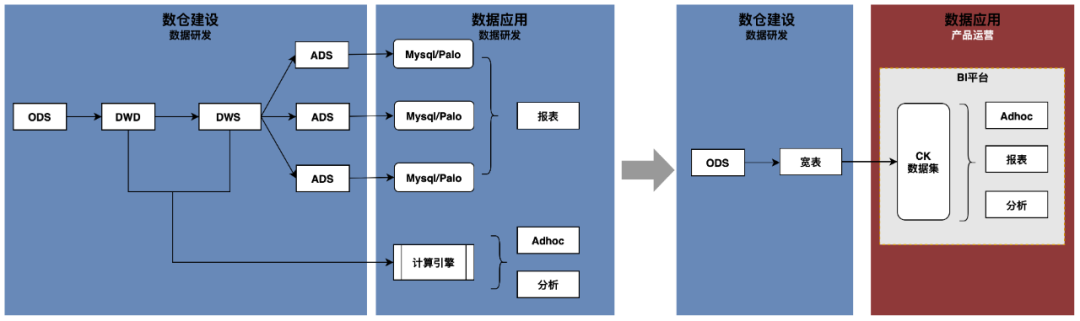
考虑到数据应用的人群从研发到产运的转变,数据的使用门槛需要进一步降低,对数仓与数据可视化平台的使用体验有更高要求。
1.2 目标
数仓的使用体验表现在直接交互的宽表层,理想的宽表应满足以下几点:
1、全面:覆盖场景足够丰富,业务需求皆可满足
2、准确:逻辑统一收敛,口径简单清晰,业务使用无歧义
3、及时:解决上游时效差异化带来的木桶效应,字段分批产出
4、易用:需求场景通过单张宽表即可获取,避免多表关联
数据平台需要考虑用户差异化的SQL能力、分析习惯、分析方法,在数据可视化、数据计算性能等方面满足用户体验:
1、可视化:拖拽式搭建,算子及样式丰富
2、计算性能:秒级查询耗时
基于上述想法,探索宽表建模替代分层建模,并引入TDA平台,通过数仓模型与数据可视化平台的结合,支持产运自助化获取所需数据。
02 宽表建模
内容生态B端业务场景复杂,来自流量日志、业务数据及集群数据的ODS层表300+张,为了平衡数据时效性及易用性,构建了500+张DWD、DWS及ADS表,存在表血缘关系复杂、中间表冗余、数据口径不一致、SQL复杂度高等问题。
为了解决上述问题,提出宽表建模方案:根据产品功能和业务场景划分主题,明确主题最细粒度及所有的业务过程,基于ODS表直接构建宽表层,宽表覆盖业务所需全部字段,支持即席分析、报表查询等所有数据应用场景。
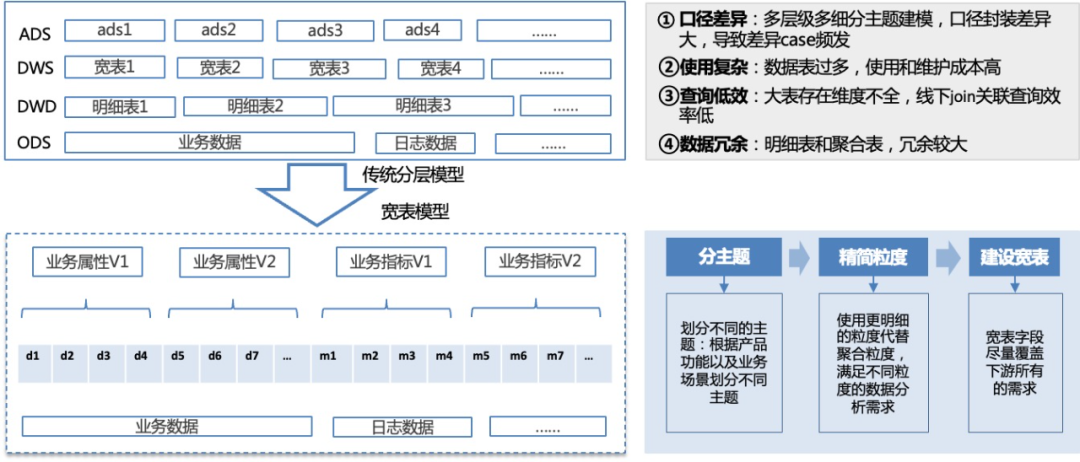
△数仓建模演进思路
2.1 技术方案
由于宽表本身上游数据源多、数据量大,当多个上游数据就绪时间不尽相同时,宽表的产出时效会出现木桶效应。此外为了尽可能覆盖全部业务需求,封装了大量的处理逻辑及关联计算,代码更加复杂,维护成本与回溯成本非常高。为了解决上述问题,探索并实现了宽表建模多版本方案。根据数据的时效差异,将宽表拆分为多个计算任务,每个任务产出宽表的部分字段,并根据配置进行数据合并,最终产出完整的宽表。
同一版本受上游数据源影响在不同日期的产出时效不可控,为了提升宽表整体的时效,需要各版本数据产出后尽快合并至宽表,且合并后,需要为下游提供依赖检查机制,感知该版本字段已产出。
2.1.1 多版本合并
为了保障各版本数据产出后尽快合并至宽表,且避免同分区有两个合并任务同时运行,造成数据错乱问题,引入了分布式锁服务,通过抢占锁是否成功来决定是否需要合并。整体流程图如下:
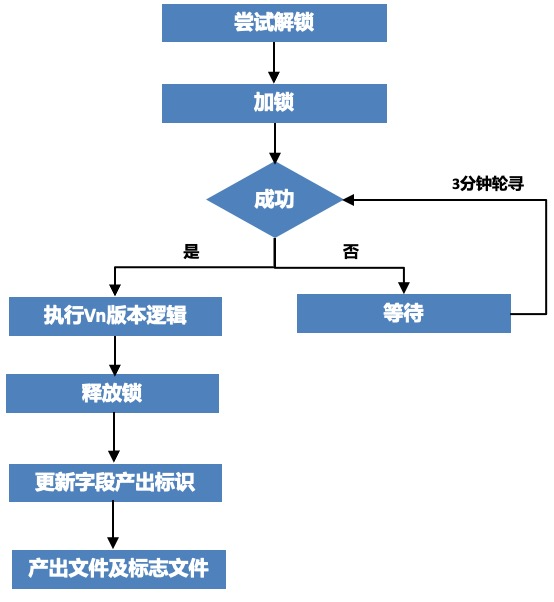
△多版本合并流程
加锁的维度是表名和日期分区,是否加锁成功基于锁状态、任务状态及过期时间进行判定:
1、锁未占用,说明当前无其他合并任务,该任务加锁成功
2、锁占用,任务状态异常,说明当前合并任务失败,该任务强制解锁并加锁成功
3、锁占用,任务状态Accept,且锁占用时间超过过期时间,Kill正在运行的任务后,该任务强制解锁并加锁成功
在多版本合并方案中,为了提升宽表合并任务的通用性,抽取了公共的合并逻辑,基于配置文件,将分版本数据产出后的文件合并至宽表中。配置文件涵盖多组文件地址、关联条件、关联类型及字段信息。每一个文件地址由独立任务生成,负责该数据源相关逻辑下沉,数据口径的变更只需更改对应的任务,维护成本较低。
2.1.2 下游依赖
多版本宽表中的字段基于时效差异分版本产出,因此需要提供依赖检查机制,使下游能及时使用就绪字段,满足高时效的数据应用场景。方案中提供了三种不同的依赖检查方式:
1、任务组依赖:通过调度平台的任务名进行依赖检查,支持厂内的pingo,tds调度平台
2、AFS文件依赖:某一版本合并到宽表后,会产出该版本任务成功的AFS标识文件,可同于下游进行依赖检查
3、字段产出探测服务:对于数据应用平台(如:一脉、TDA等),平台无法通过任务组及AFS文件依赖识别查询的字段是否产出。针对这些场景,提供字段探测服务,在某一版本合并到宽表后,会更新探测服务中该版本相关字段的产出标识,数据应用平台通过API接口调用判定本次查询的字段在查询时间范围内是否就绪,保障数据的可用性
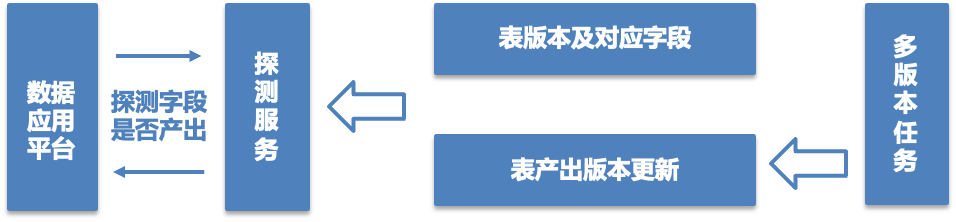
△字段探测服务
2.2 宽表优点
-
成本方面:经典分层数仓层与层之间冗余严重,采用宽表建模后避免了构建繁多的DWD、DWS层表,一个主题仅有一到两个宽表,数仓中表的数量减少60%,存储下降30%。此外,表的精简带来数据任务的减少,数据查询也由多个DWD、DWS表的关联优化至一张宽表,避免了大量的shuffle运算,即席查询耗时由分钟级缩短至秒级,计算资源节省20%。
-
质量方面:宽表的字段非常丰富,达到上千个,尽可能覆盖主题所有的业务场景,因此应用层的数据完全可以收敛至宽表层,消除了分层数仓中因表的冗余及逻辑下沉不彻底造成的口径不一致问题,与产品侧基于宽表层管理指标口径,沟通更流畅,数据准确性更高。
-
效率方面:宽表模型易用性非常好,复杂需求通过单张宽表即可满足,具备基础的SQL能力即可获取所有数据,业务使用体验非常好。
03 可视化平台
常见的数据需求分为三类:临时提数、报表开发、数据分析。对于临时提数场景,宽表模型对业务覆盖的全面性及数据获取的易用性,可以支持产运侧通过简单的SQL拼写获取数据;对于报表开发场景,仍需要数据研发构建ADS层应用表,并同步至OLAP存储,利用Sugar等报表平台进行配置;对于数据分析场景,产运侧可基于宽表获取分析数据,但需要保存灵活多变的分析结果,并进行可视化展示,体验较差。
宽表模型极大简化了数据查询的复杂度,为自助化获取数据提供了基础能力,报表及数据分析所要求的数据可视化能力成为了产运自助化获取数据的阻力。对此,引入TDA数据可视化平台,支持数据分析及仪表盘拖拽式搭建,数据处理和分析能力丰富,一站式解决数据应用需求。
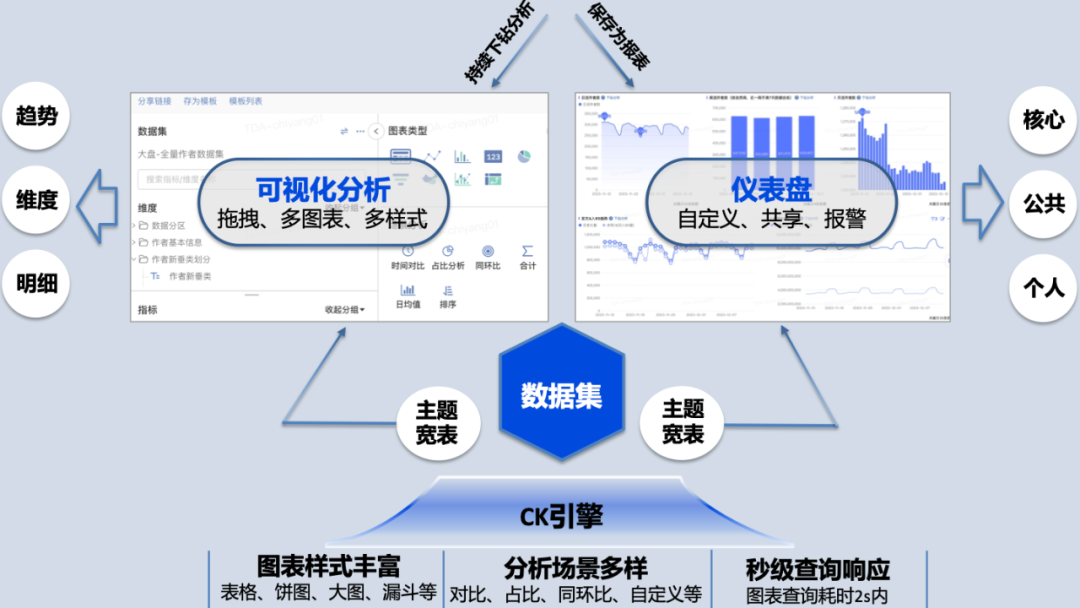
△自助化思路
该模式下,数据研发负责主题宽表的建设、同步及查询性能的优化,数据产品同学负责数据集的配置,运营同学基于数据集进行可视化分析及仪表盘配置,实现数据应用的自助化。
宽表建设:按照宽表建模思想构建主题宽表。
数据同步:数据从HDFS至ClickHouse同步,数仓宽表每个版本产出后启动同步任务,并将distinct查询场景的key在数据同步阶段进行shuffle。
性能优化:为了优化查询耗时,引入了缓存及自动上卷两个机制。缓存包含两种情况:用户首次查询,将查询结果进行缓存;基于用户查询历史记录,通过离线任务方式轮询来模拟用户查询,并将查询结果更新缓存。自动上卷则基于用户历史查询记录的特征,针对高频的维度进行projection聚合。目前,针对千万级数据查询场景,查询耗时秒级。
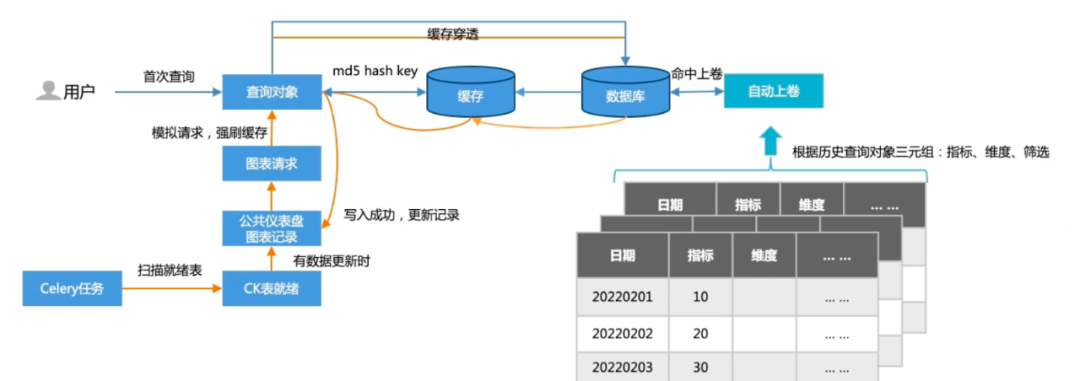
△缓存+自动上卷机制
04 总结
通过数仓宽表模型与数据可视化平台的结合,完成了数据需求从研发定制化开发到产运自助化获取的转变,数据分析的灵活性和效率大幅提升,降低了人力成本。
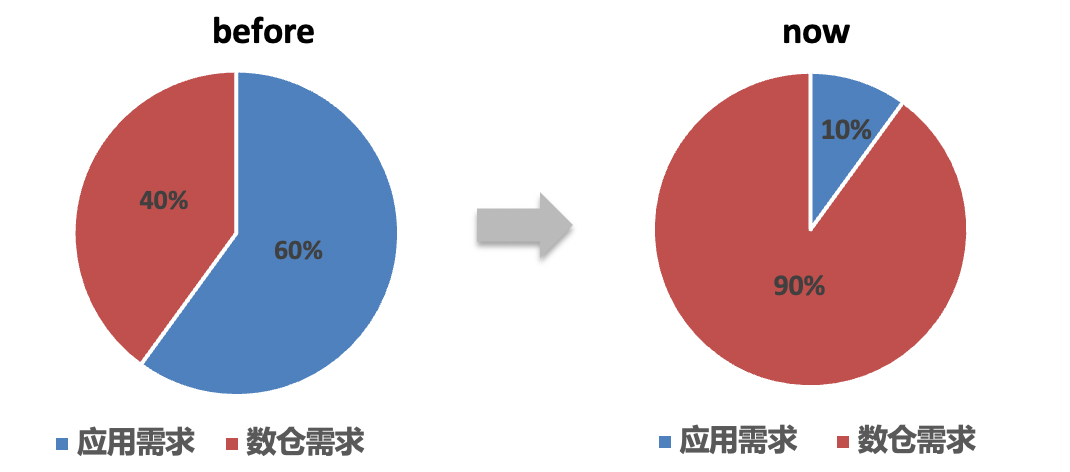
1、研发承接的需求量下降57%,其中数据应用需求占比由60%降低至10%。
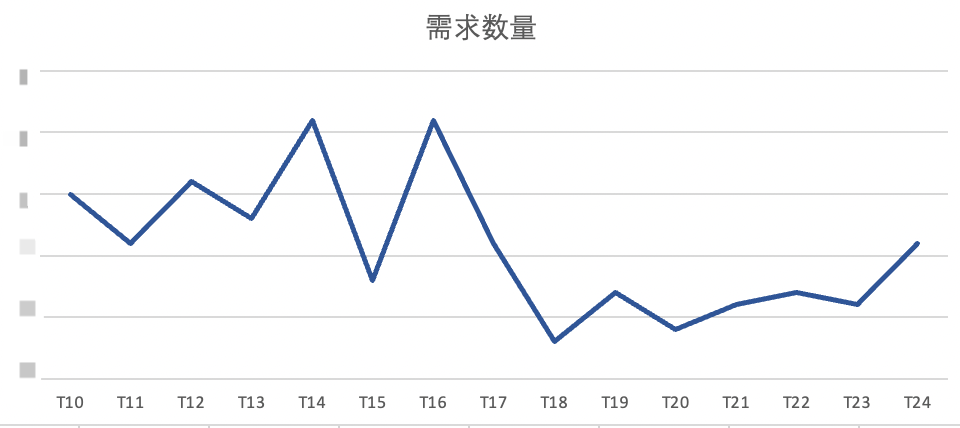
△需求数量
2、可视化分析场景每日PV 4000+,整体数据需求自助化率达到92%。
3、单次查询耗时从分钟级缩短至秒级。
4、报表开发周期由天级缩短至小时级。
——END——
推荐阅读
百度搜索exgraph图执行引擎设计与实践
百度搜索&金融:构建高时效、高可用的分布式数据传输系统
“踩坑”经验分享:Swift语言落地实践
移动端防截屏录屏技术在百度账户系统实践
AI Native工程化:百度App AI互动技术实践