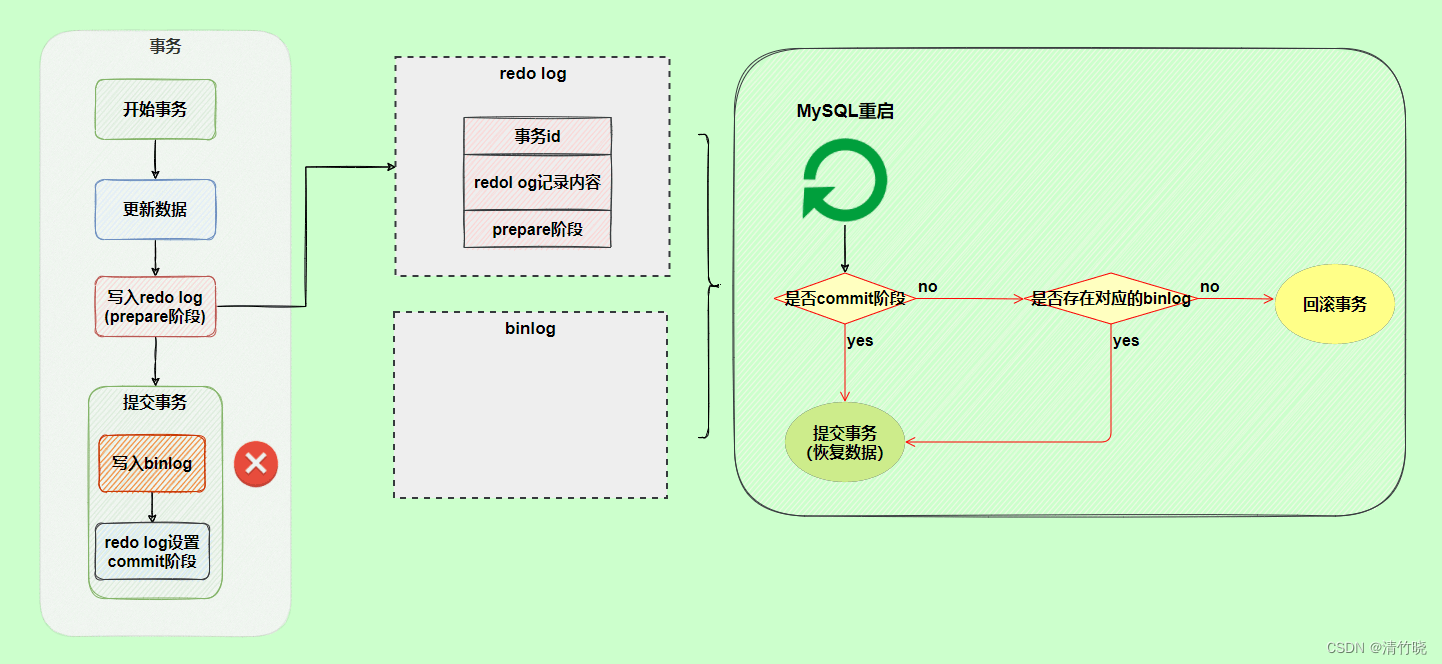
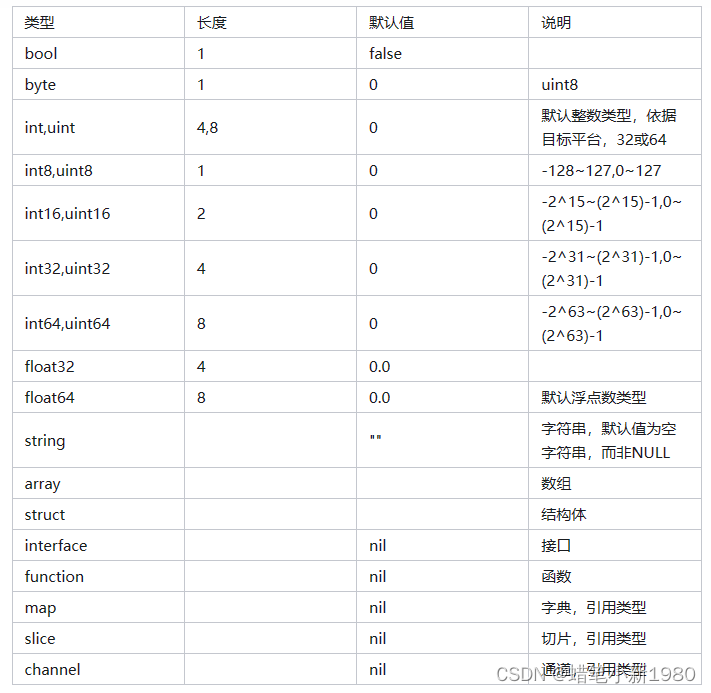
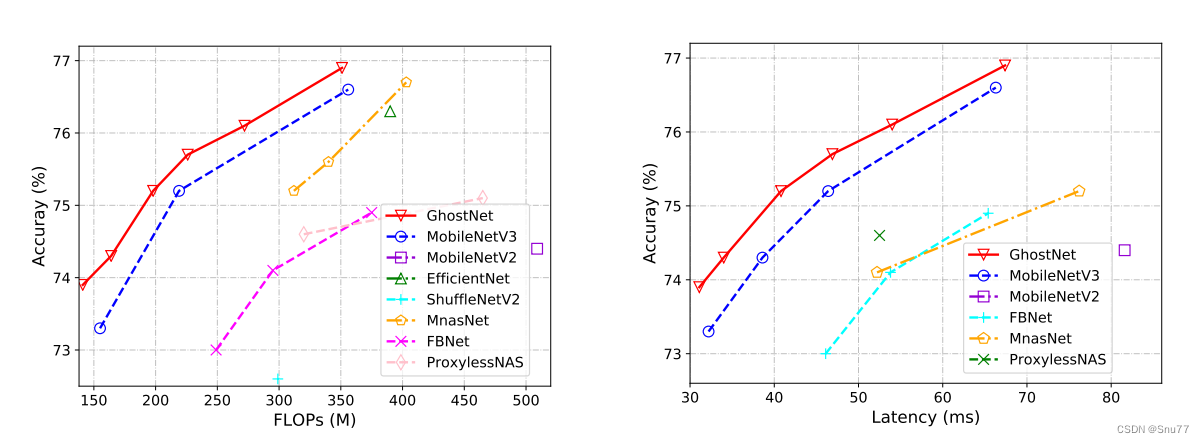
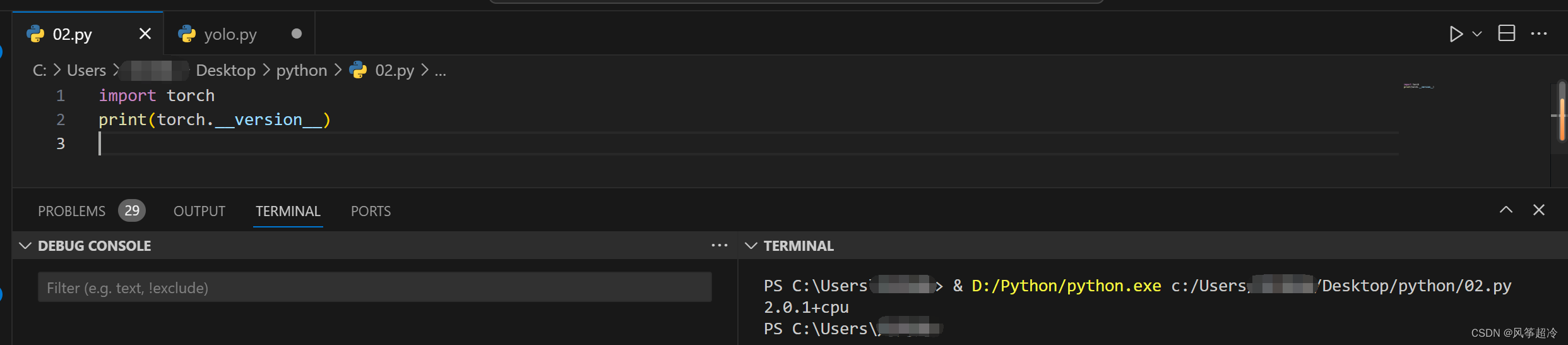
在大数据领域,将数据从关系型数据库(如Oracle)导入到Hadoop生态系统是一项常见的任务。Sqoop是一个强大的工具,可以帮助轻松完成这项任务。本文将提供详细的指南,以及丰富的示例代码,帮助了解如何使用Sqoop从Oracle数据库导入数据到Hadoop集群中。
什么是Sqoop?
Sqoop是一个用于在Hadoop生态系统(如HDFS和Hive)与关系型数据库之间传输数据的工具。它使数据工程师能够方便地将结构化数据从关系型数据库导入到Hadoop中,以便进行更多的数据分析和处理。
Sqoop支持多种关系型数据库,包括Oracle、MySQL、SQL Server等。
步骤1:安装和配置Sqoop
要开始使用Sqoop,首先需要在Hadoop集群上安装和配置Sqoop。确保已经完成了以下步骤:
-
下载和安装Sqoop:可以从Sqoop官方网站下载最新版本的Sqoop,并按照安装指南进行安装。
-
配置数据库驱动程序:Sqoop需要数据库驱动程序来连接到Oracle数据库。将Oracle数据库驱动程序(通常是一个JAR文件)放入Sqoop的
lib目录中。 -
配置Sqoop连接:编辑Sqoop的配置文件(
sqoop-site.xml)并配置数据库连接信息,包括数据库URL、用户名和密码。
步骤2:使用Sqoop导入数据
一旦Sqoop安装和配置完成,就可以使用Sqoop来导入数据了。
以下是一个详细的示例,演示了如何从Oracle数据库导入数据:
sqoop import \--connect jdbc:oracle:thin:@//localhost:1521/yourdb \--username yourusername \--password yourpassword \--table yourtable \--target-dir /user/hadoop/yourtable_data
解释一下这个示例的各个部分:
-
--connect:指定数据库连接URL,包括数据库类型(jdbc:oracle:thin)、主机名和端口号以及数据库实例名。 -
--username:指定连接数据库的用户名。 -
--password:指定连接数据库的密码。 -
--table:指定要导入的Oracle数据库中的表名。 -
--target-dir:指定将数据导入到Hadoop中的目标目录。
步骤3:配置和高级选项
Sqoop提供了许多配置选项和高级选项,以满足不同的需求。
以下是一些常见的配置选项:
-
--columns:指定要导入的列,以逗号分隔。 -
--split-by:指定用于拆分数据的列,以加速导入过程。 -
--where:使用SQL查询条件来筛选要导入的数据。 -
--as-parquetfile:将数据导入为Parquet文件,以提高性能和压缩效率。 -
--incremental:启用增量导入模式,以仅导入新数据。
示例:将数据从Oracle导入到Hive
除了将数据导入到Hadoop文件系统(HDFS)中,Sqoop还可以将数据导入到Hive表中,以便进一步的数据分析。
以下是一个示例,演示了如何将数据从Oracle导入到Hive表:
sqoop import \--connect jdbc:oracle:thin:@//localhost:1521/yourdb \--username yourusername \--password yourpassword \--table yourtable \--hive-import \--hive-table yourhive table \--target-dir /user/hadoop/yourtable_data
在这个示例中,使用了--hive-import选项来指示Sqoop将数据导入到Hive表中,并使用了--hive-table选项来指定目标Hive表的名称。
总结
使用Sqoop从Oracle数据库导入数据是在大数据环境中进行数据分析的关键步骤之一。本文提供了一个详细的指南,包括安装和配置Sqoop、使用Sqoop导入数据的步骤以及一些常见的配置选项。希望这些示例代码和详细内容有助于大家更好地了解和应用Sqoop,以实现无缝的数据导入操作。