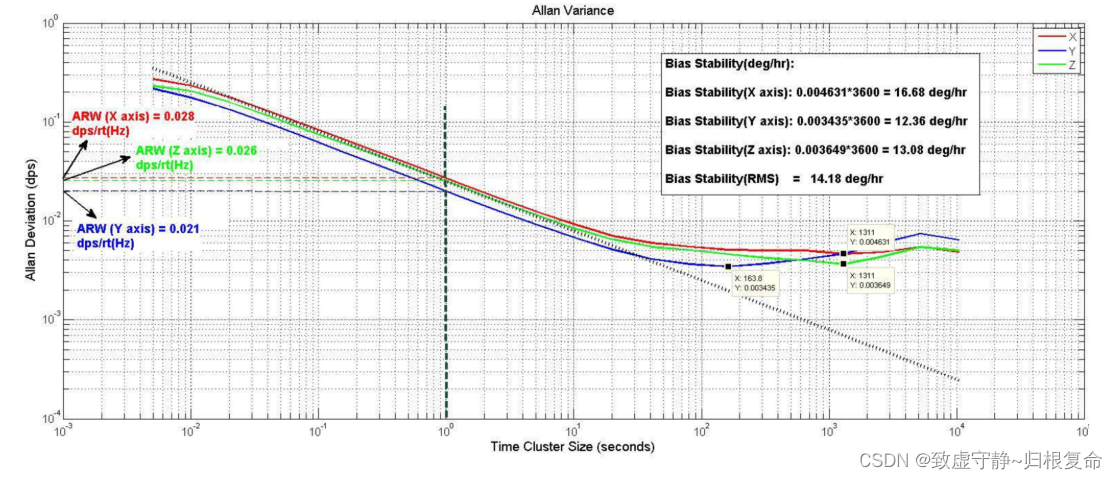
清华、小米、华为、 vivo、理想等多机构联合综述,首提个人LLM智能体、划分5级智能水平
https://mp.weixin.qq.com/s/JYB4BzsXhWF8pEUUkvn_GQ
想必这些唤醒词中至少有一个曾被你的嘴发出并成功呼唤出了一个能给你导航、讲笑话、添加日程、设置闹钟、拨打电话的智能个人助理(IPA)。可以说 IPA 已经成了现代智能手机不可或缺的标配,近期的一篇综述论文更是认为「个人 LLM 智能体会成为 AI 时代个人计算的主要软件范式」。这篇个人 LLM 智能体综述论文来自国内多所高校和企业研究所,包括清华大学、小米、华为、欢太、vivo、云米、理想汽车、北京邮电大学、苏州大学。文中不仅梳理了个人 LLM 智能体所需的能力、效率和安全问题,还收集并整理了领域专家的见解,另外还开创性地提出了个人 LLM 智能体的 5 级智能水平分级法。该团队也在 GitHub 上创建了一个文献库,发布了相关文献,同时也可供 IPA 社区共同维护,更新最新研发进展。
英伟达新对话QA模型准确度超GPT-4,却遭吐槽:无权重代码意义不大

https://mp.weixin.qq.com/s/uLVVfQNau_SLUPptCDQNmw
一年多来,ChatGPT 及后续产品引发了生产和研究社区中构建问答(QA)模型的范式转变。尤其是在实际应用中,QA 模型在以下情况成为首选。近日,在英伟达的一篇论文中,研究者提出了一个具有 GPT-4 级别准确度的白箱对话 QA 模型 ChatQA 70B。他们采用了两阶段指令调优方法以及用于对话 QA 的 RAG 增强检索器、严格的数据管理过程。
罗氏制药和GRCEH团队开发可解释机器学习方法,用于分析治疗性抗体的免疫突触和功能表征
https://mp.weixin.qq.com/s/upntqHl93p_uhFsMaHBjbg
治疗性抗体广泛用于治疗严重疾病。它们中的大多数会改变免疫细胞并在免疫突触内发挥作用。指导体液免疫反应的重要细胞间相互作用。尽管生成并评估了许多抗体设计,但缺乏用于系统抗体表征和功能预测的高通量工具。德国环境健康研究中心(German Research Center for Environmental Health)和罗氏制药(Roche)的研究团队,开发了一个全面的开源框架 scifAI(单细胞成像流式细胞术 AI),用于对成像流式细胞术 (IFC) 数据进行预处理、特征工程和可解释的预测机器学习。
一张照片,为深度学习巨头们定制人像图片

https://mp.weixin.qq.com/s/7d8En7idif4UFSGo_6MFsg
主题驱动的文本到图像生成,通常需要在多张包含该主题(如人物、风格)的数据集上进行训练,这类方法中的代表工作包括 DreamBooth、Textual Inversion、LoRAs 等,但这类方案因为需要更新整个网络或较长时间的定制化训练,往往无法很有效地兼容社区已有的模型,并无法在真实场景中快速且低成本应用。而目前基于单张图片特征进行嵌入的方法(FaceStudio、PhotoMaker、IP-Adapter),要么需要对文生图模型的全参数训练或 PEFT 微调,影响原本模型的泛化性能,缺乏与社区预训练模型的兼容性,要么无法保持高保真度。为了解决这些问题,来自 InstantX 团队的研究人员提出了 InstantID,该模型不训练文生图模型的 UNet 部分,仅训练可插拔模块,在推理过程中无需 test-time tuning,在几乎不影响文本控制能力的情况下,实现高保真 ID 保持。
AI看视频自动找“高能时刻”|字节&中科院自动化所@AAAI 2024

https://mp.weixin.qq.com/s/dFxGrYZbq0uxRs0QwLM8AQ
字节跳动联合中科院自动化研究所提出新方法,用AI快速检测出视频中的高光片段,对输入视频的长度以及期望提取的高光长度都具有极高的灵活性,相关论文已被AAAI 2024收录。
大模型自我奖励:Meta让Llama2自己给自己微调,性能超越了GPT-4

https://mp.weixin.qq.com/s/tBVosNn07shQZxfvtSlaOw
大模型领域中,微调是改进模型性能的重要一步。随着开源大模型逐渐变多,人们总结出了很多种微调方式,其中一些取得了很好的效果。最近,来自 Meta、纽约大学的研究者用「自我奖励方法」,让大模型自己生成自己的微调数据,给人带来了一点新的震撼。在新方法中,作者对 Llama 2 70B 进行了三个迭代的微调,生成的模型在 AlpacaEval 2.0 排行榜上优于一众现有重要大模型,包括 Claude 2、Gemini Pro 和 GPT-4。
奥特曼筹数十亿美元建全球晶圆厂网络,自造AI芯片

https://mp.weixin.qq.com/s/VoPLuWtOQmJE4hoGNvC5QA
据彭博社消息,OpenAI CEO 萨姆・奥特曼(Sam Altman)近日再次为一家人工智能芯片企业筹集了数十亿美元的资金,希望建立一个范围覆盖全球的晶圆厂「企业网络(network of factories)」,并计划与未具名的顶级芯片制造商合作。
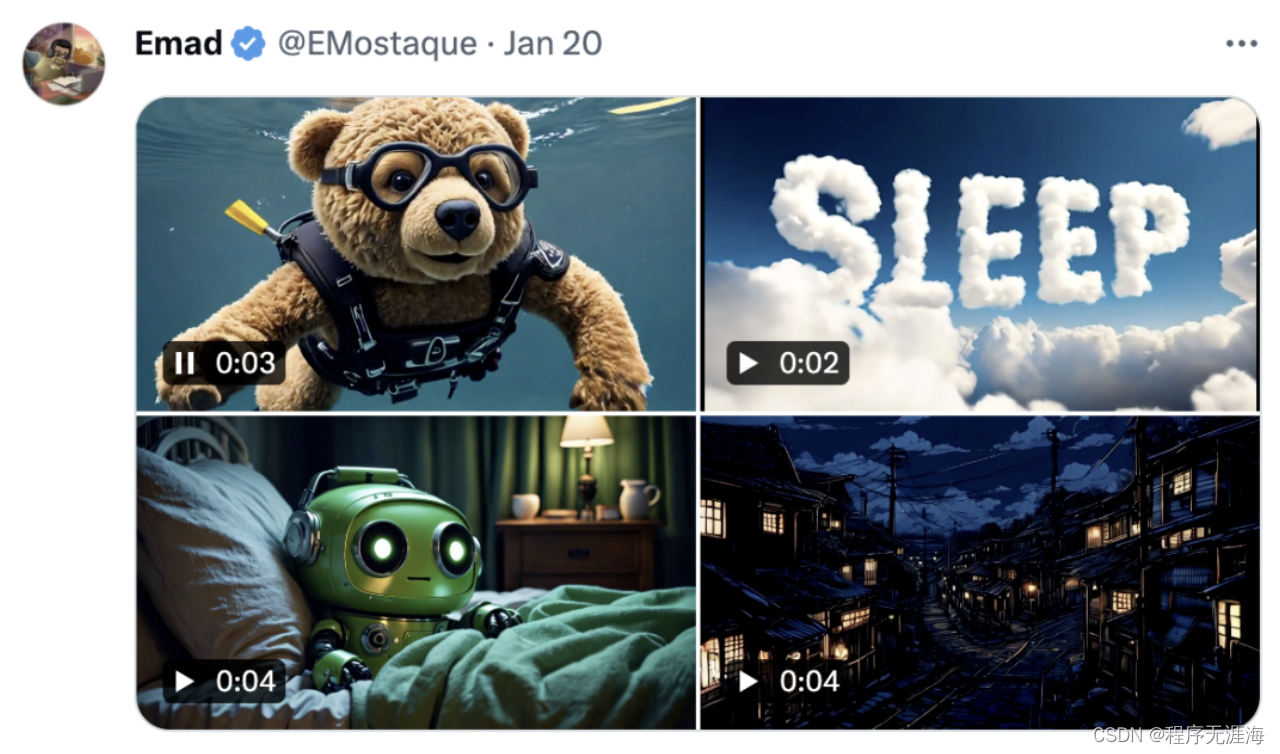
Stability AI杀回来了:视频生成新Demo效果惊人,网友:一致性超群
https://mp.weixin.qq.com/s/Xt3CZ_F3r0_iMG0YjE2GyA
Stable Diffusion要王者归来了?Stability AI CEO Emad Mostaque最新推文,四段视频引人无数遐想。不少网友怀疑,这是Stable Video Diffusion新版本的演示Demo。因为从效果上看,不管是画面清晰度、一致性还是流畅度都十分惊人。
两位 DeepMind 员工离职创立 AI 模型首轮或融 2 亿美金,Flexport 又拿了2.6亿美金

https://mp.weixin.qq.com/s/n_GBvbAkkNa4sn8UdL6vCg
Flexport CEO Ryan Petersen 在 X 上宣称,已经从 Shopify 那里融了 2.6 亿美金的新一轮融资。比较有意思的是,此次融资是一个 uncapped convertible note,也就是一种无估值上限的可转换债券,一般用于早期创业项目的投资,是对创业公司非常有利的一种融资方式。此次在 Flexport 这么后期的公司里采用这种方式,估计是对 Flexport 过去一年面临的各种问题的一个支持,在过去一年,因为疫情其业务量出现大幅下降,导致公司面临一系列的问题,最后 Flexport 经历了两次 20% 的裁员。
Wolf分享datatrove,nanotron:两个用于大规模数据处理和大型模型训练的工具
https://x.com/Thom_Wolf/status/1748664223624781864?s=20
我们刚刚开源了两个用于大规模数据处理和大型模型训练的工具:
•datatrove – 所有关于Web规模数据处理的事务:去重、过滤、分词 – https://github.com/huggingface/datatrove
•nanotron – 所有关于三维并行性的事务:轻量级且快速的大型语言模型训练 – https://github.com/huggingface/nanotron
这两个都是极简的框架,代码行数在5-10千之间,依赖非常有限。
请享用!
•因为它们是站在开源软件巨人的肩膀上的
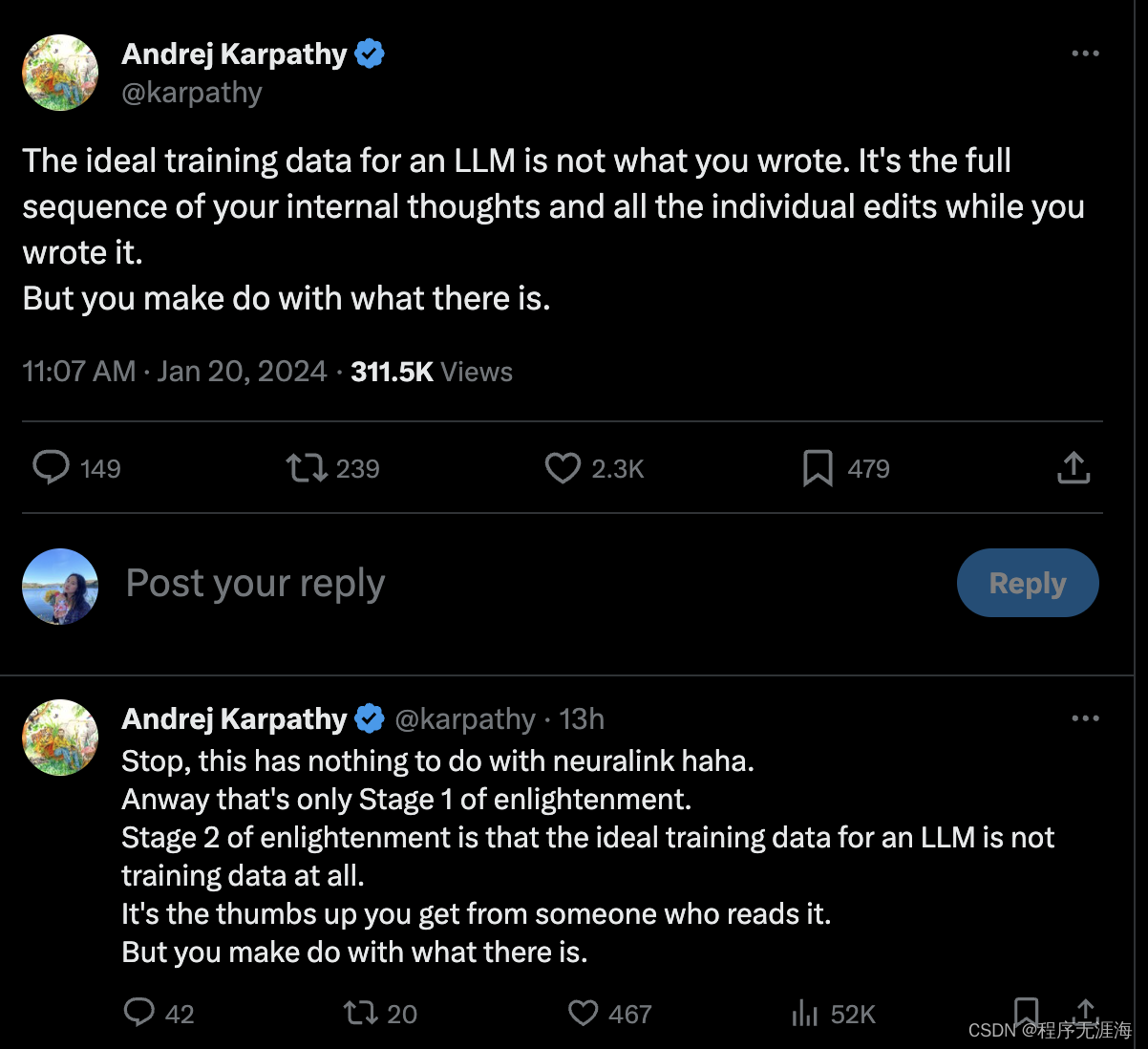
Karpathy:你所写的东西不是LLM理想的训练数据,而是写作时内心思维的完整序列和所有个别的编辑过程
https://x.com/karpathy/status/1748784260318990496?s=20
Karpathy:理想的大型语言模型(LLM)训练数据不是你所写的内容。而是你在写作时内心思维的完整序列和所有个别的编辑过程。
但你得用现有的资料将就。
停,这和神经连接没关系哈哈。
无论如何,这只是启蒙的第一阶段。
启蒙的第二阶段是,理想的大型语言模型训练数据根本就不是训练数据。
而是你从读者那里得到的点赞。
但你得用现有的资料将就。
https://x.com/DrJimFan/status/1748785642950291583?s=20
Jim Fan:这方面的一个近似是GitHub仓库的提交历史。不仅仅要在最终代码上训练,还要在所有的尝试和痕迹上进行训练。
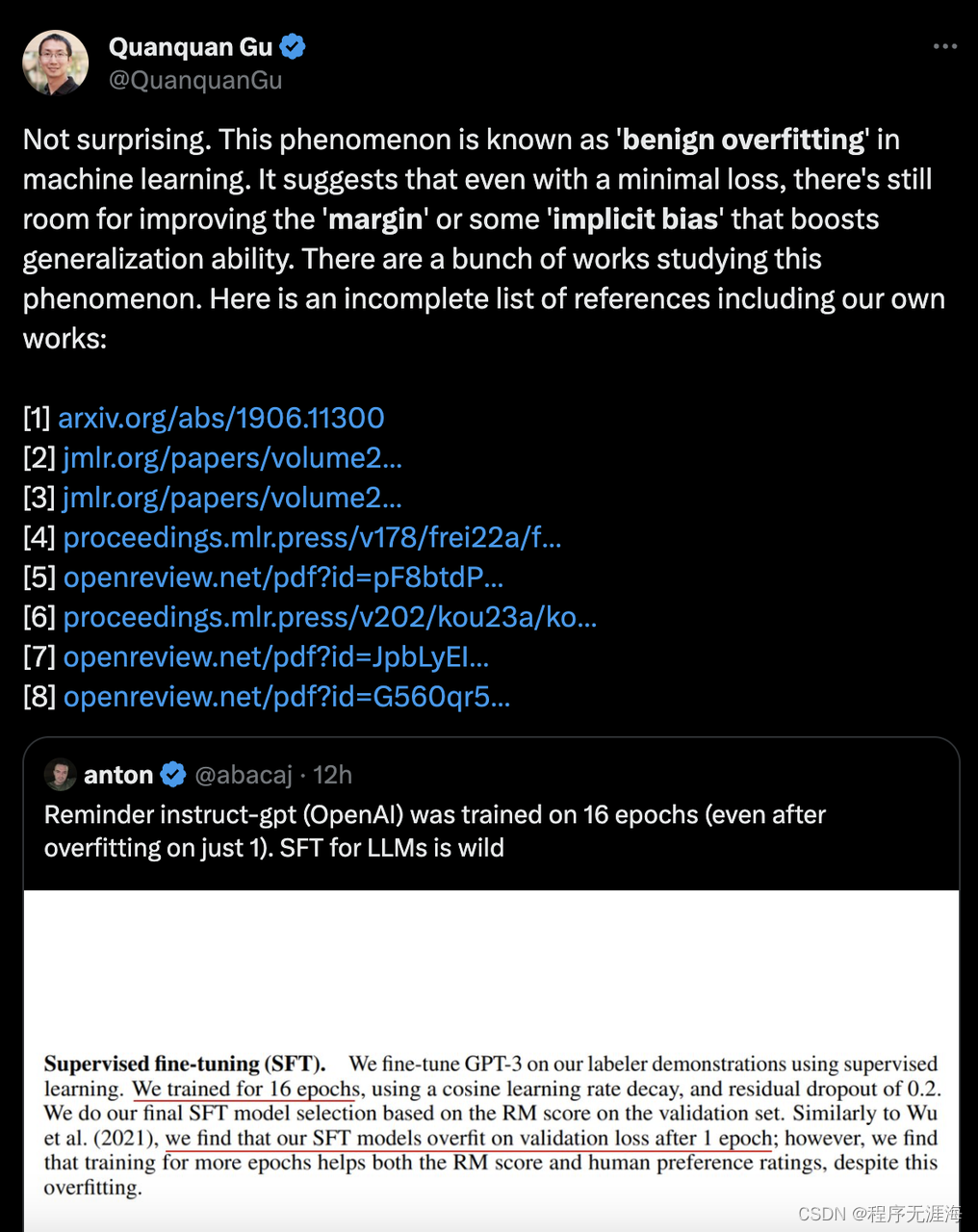
Gu科普instructGPT为什么过拟合后还继续训练:机器学习中被称为“良性过拟合”
https://x.com/QuanquanGu/status/1748846915528311202?s=20
Anton:提醒 instruct-GPT(由OpenAI训练)经过了16个时期的训练(即使在仅训练1个时期后已经过拟合)。用于大型语言模型的SFT是非常疯狂的。
Quanquan Gu回答:这并不奇怪。这种现象在机器学习中被称为“良性过拟合”。它表明,即使在最小损失的情况下,仍有改善“边际”或某些“隐含偏见”的空间,这些偏见可以提升泛化能力。有很多研究这种现象的作品。
Srivastav分享DataTrove:用于处理、过滤和去重大规模文本数据的库

https://x.com/reach_vb/status/1748850216323760609?s=20
Srivastav:介绍DataTrove 🤯
它的处理流程是平台无关的,可以在本地或在slurm集群上即开即用。
低内存使用量和多步骤设计使其非常适合大型工作负载,比如处理大型语言模型(LLM)的训练数据。✨
Percy Liang分享TED演讲:每个人都有自己独特的技能、知识和价值观,这定义了我们文明的文化,人工智能的目的,就是组织和增强这种文化

https://x.com/percyliang/status/1748781586756047343?s=20
我的TEDAI演讲,于2023年10月进行,现在已经可以在线观看:http://go.ted.com/percyliang。这是一个难以进行的演讲:1. 我记住了它——感觉更像是在进行钢琴独奏会而不是学术讲座。2. 我希望它能够超越时代,尽管人工智能变化迅速……三个月后仍然适用。以下是我所说的内容:
透明度:我们缺乏对当今最强大的基础模型的透明度。即使是评估,在没有一些对训练数据的了解的情况下也是无意义的。没有透明度,我们就失去了问责性。想想没有营养标签的食品或没有安全评级的汽车。
价值观:我们谈论将人工智能与人类价值观相一致,但我们谈论的是哪些价值观?我们如何设计一个更民主的过程来引出价值观?基础模型将成为我们理解世界的主要入口,价值观的确定方式至关重要。
归属:机器学习研究人员所说的数据,是艺术家们称之为画作,作家们称之为书籍,程序员们称之为软件的——都是人类劳动的结果。我们如何设计一种机制来补偿和激励这些创作者?
我们如何改变现状?维基百科(与大英百科全书相比)和Linux(与Windows相比)是开放式开发如何能够战胜封闭生态系统的鼓舞人心的例子。如何以负责任的方式为人工智能做到这一点,在我看来是目前最大的研究问题。
这个世界充满了不可思议的人——艺术家、音乐家、作家、科学家——每个人都有自己独特的技能、知识和价值观。整体上,这定义了我们文明的文化。我认为,人工智能的目的,就是组织和增强这种文化。
Talc AI

https://talc.ai/
Talc 使公司能够轻松、更快地推出可靠的 AI 应用程序。提供了一个运行数百个真实场景的暂存环境,让开发人员清楚地了解他们的 AI 如何满足业务需求。
Reading coach

https://coach.microsoft.com/
微软推出了 Reading Coach 是一款免费工具,可提供个性化、独立的阅读流利度练习。使用人工智能和内置的流利度检测功能,使用学习者难以理解的单词来个性化阅读内容,同时带给用户舒服的阅读体验。
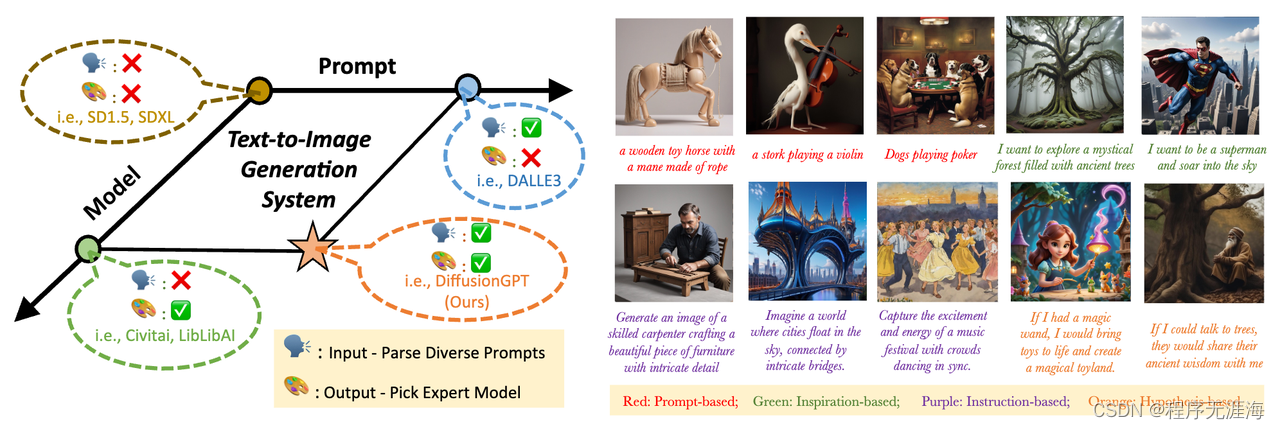
DiffusionGPT
https://diffusiongpt.github.io/
字节团队和中山大学推出了 DiffusionGPT,它利用大型语言模型 (LLM) 来提供一个统一的生成系统,能够无缝适应各种类型的提示并集成领域专家模型。DiffusionGPT 基于先验知识为各种生成模型构建特定领域的树。当提供输入时,它会 LLM 解析提示并采用思维树来指导选择合适的模型,从而放宽输入约束并确保跨不同领域的卓越性能。此外,还引入了优势数据库,其中思想树通过人类反馈进行了丰富,使模型选择过程与人类偏好保持一致。
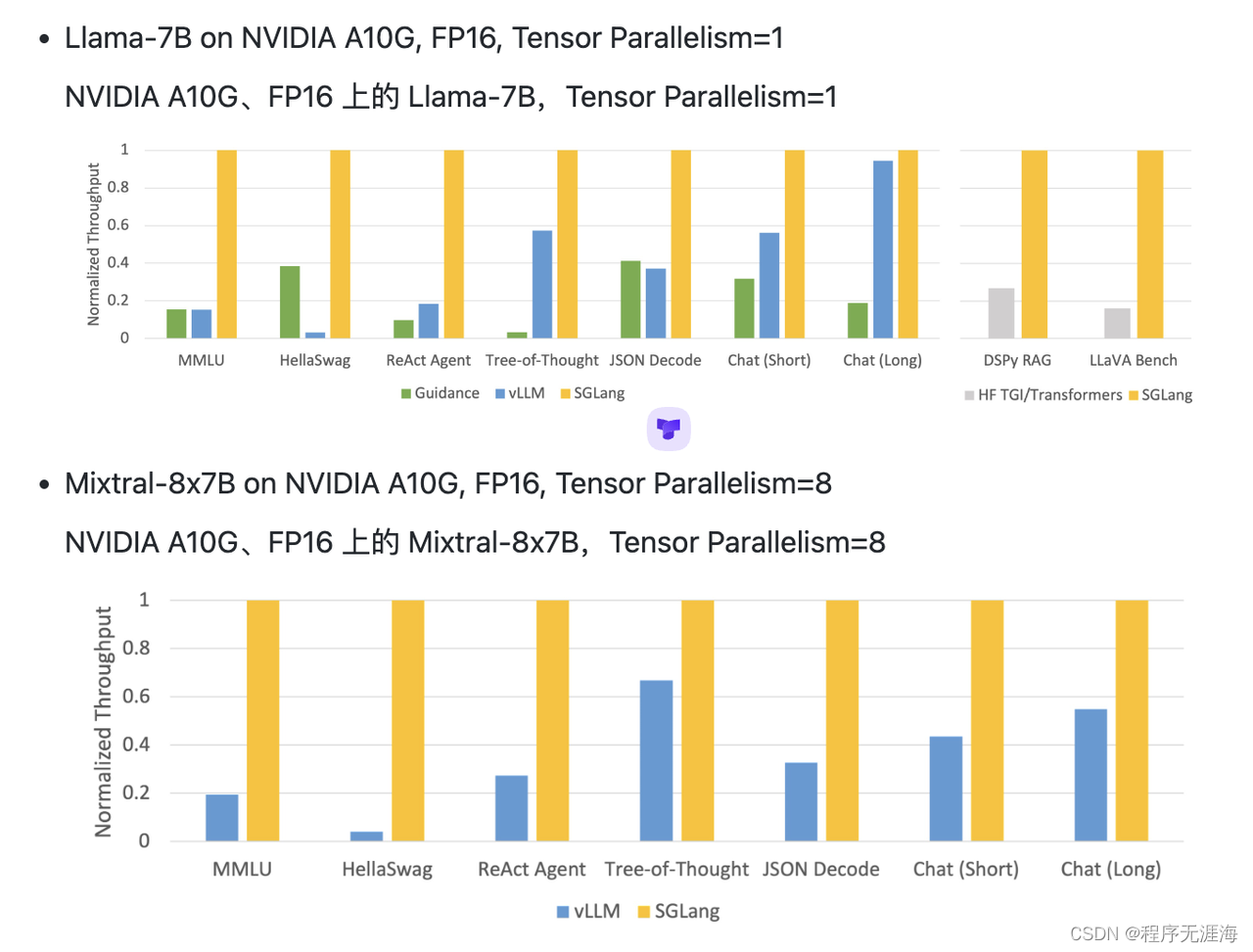
Sglang
https://github.com/sgl-project/sglang
SGLang 是一种专为大型语言模型设计的结构化生成语言 (LLMs)。它通过共同设计前端语言和运行时系统,使您的交互 LLMs 更快、更可控。
投融周报
https://mp.weixin.qq.com/s/WMF_g4U7sq3eT6IyHkCrwg
本文总结了最近一周内的重点融资事件。在新消费领域,文化艺术相关平台获得投资,其中术策展平台世芥树和艺术品收藏交流平台获得数千万元人民币融资。硬科技领域的半导体公司,如芯爱科技和芯德半导体获得巨额融资。大健康领域中,内窥镜企业星辰海医疗和医疗器械生产商益腾医疗分别完成数千万元人民币的融资。互联网赛道上,企业信息安全公司雪诺科技和神州慧安完成了显著的融资活动。其他领域的创业公司也获得了投资,显示了市场对多个行业和创新科技的持续关注和投资意愿。
使用SPIN技术对LLM进行自我博弈微调训练
https://zhuanlan.zhihu.com/p/678451928?utm_medium=social&utm_oi=56635854684160&utm_psn=1731545128341274624&utm_source=wechat_session&s_r=0
该文介绍了SPIN技术,这是一种用于大型语言模型(LLM)自我博弈微调的新方法。SPIN从AlphaGo Zero和AlphaZero中自我对弈的成功机制中汲取灵感,可让LLM通过自我游戏学习,省去了对专业注释者的依赖。通过自我博弈,LLM可以在对抗或合作环境中提升性能,并与其他学习技术相结合。SPIN主模型通过辨别由自己和人类生成的响应来训练。在每次迭代中,主模型识别和区分能力的提升都会更新对手模型的参数。SPIN算法在微调预训练模型时表现出了显著的性能提升。
如何看待1.17Nature论文《无需人类示例即可解决奥赛几何问题》发布AlphaGeometry?
https://www.zhihu.com/question/640017394/answer/3366559512?utm_medium=social&utm_oi=56635854684160&utm_psn=1732231771289346048&utm_source=wechat_timeline&utm_id=0
文章讨论了Nature论文《无需人类示例即可解决奥赛几何问题》发布的AlphaGeometry。这项研究通过合成数据技巧和大语言模型来解决加辅助线的几何证明问题,一个长期难点。合成数据包括随机几何图形的可能命题和必需的几何对象集。AlphaGeometry用1.51亿参数模型合成了5亿个几何证明,并能在有限的时间内解决复杂几何题目。该研究展示了LLM暴力美学在复杂问题解决上的潜力。尽管方法可能难以推广到非几何数学领域,但为数学问题解决提供了新思路。
记一则 HF Transformers 中的 RoPE 实现 bug
https://zhuanlan.zhihu.com/p/678963442?utm_medium=social&utm_oi=56635854684160&utm_psn=1732326690599202816&utm_source=wechat_timeline&utm_id=0
该文章讨论了HuggingFace Transformers库中的RoPE(Rotary Positional Embedding)实现bug问题。作者在使用HfDeepSpeedConfig进行大模型的ZeRO3分片加载时,观察到训练过程中的Loss不稳定,导致性能下降。后续调查发现,这一问题源于RoPE embedding在GPU初始化时的精度误差。通过比较启用与不启用HfDeepSpeedConfig的模型输出,明显看出其精度误差。社区成员stas00进一步确认了Bug真正原因,并提出了一个能够复现问题的最小示例。为了解决这一问题,自己Hack了LLaMA2模型的代码,但指出官方库中尚无正式修复。作者建议考虑将RoPE embedding加入模型离线权重中,避免模型加载时的初始化导致的问题。
Large Language Models Play StarCraft II: Benchmarks and A Chain of Summarization Approach
https://zhuanlan.zhihu.com/p/678707465?utm_medium=social&utm_oi=56635854684160&utm_psn=1731690671923310593&utm_source=wechat_session&s_r=0
本文探索了使用大型语言模型(LLM)来解决《星际争霸II》这一复杂任务的可能性,以实现长期任务规划和策略可解释性。研究者开发了TextStarCraft II接口,通过文本形式允许LLM与《星际争霸II》交互,并提出“Chain of Summarization”(CoS)方法来对游戏观察进行总结,并生成策略决策。使用CoS,LLM能够有效处理和分析游戏中的复杂信息,并减少交互时间,提高决策速度。实验表明,使用CoS的LLM-Agent能够击败困难等级5的内置AI。这项研究为使用文本与游戏交互和提高LLM的推导能力与决策速度提供了新的方法。
MuZero Unplugged
https://zhuanlan.zhihu.com/p/678489535?utm_medium=social&utm_oi=56635854684160&utm_psn=1731470411819397121&utm_source=wechat_session&s_r=0
本文介绍了MuZero Unplugged算法,它是基于模型的强化学习领域的新研究,旨在高效地从有限数据中学习。Reanalyse技术被提出并应用于MuZero算法,以改善现有数据点的策略和价值更新目标。MuZero Unplugged算法无需特殊调整即适用于在线和离线强化学习,并在各种基准测试中显示了其优越性能。论文还探讨了不同动作选择方法和训练损失函数对算法性能的影响,并与其他离线方法进行了比较。研究结果表明,结合MCTS动作选择和Reanalyse损失的MuZero Unplugged在多种设置下表现最佳。
探索多模态大型语言模型(MLLMs)的推理能力:关于多模态推理新趋势的综合调查
https://arxiv.org/abs/2401.06805
这篇综述论文全面回顾了多模态大型语言模型(MLLMs)的评估协议,分类并展示了MLLMs的前沿,介绍了最新的多模态推理密集任务应用趋势,并讨论了当前实践和未来方向。这项研究为多模态推理这一重要话题建立了坚实的基础,并提供了深入的见解
机器学习科研的十年
https://zhuanlan.zhihu.com/p/74249758?wechatShare=2&s_r=0
文章回顾了作者十年的机器学习研究历程,突出了深度学习、推荐系统、XGBoost、MXNet框架、知识迁移、GAN、内存优化算法以及TVM项目等关键技术的发展。作者通过不断探索和跨领域合作,实现了从研究新手到领域专家的转变,体现了科研中的不确定性、挑战与成长。
知识链:通过动态适应多源知识来构建大型语言模型
https://arxiv.org/abs/2305.13269
“知识链”(CoK)是一种新型框架,通过动态整合各种来源的信息来增强大型语言模型。它由推理准备、动态知识适应和答案整合三个阶段组成。如果初步答案之间没有明确的一致性,CoK会从相关领域适应知识来纠正推理。它利用无结构和有结构(如Wikidata和表格)的数据源。该框架包括一个自适应查询生成器,能够生成多种查询语言的查询。CoK在不同领域的知识密集任务上表现出一致的性能提升。
大型语言模型的检索增强生成:综述
https://arxiv.org/abs/2312.10997
这篇综述论文探讨了大型语言模型(LLMs)在处理知识密集型任务时的局限性,并提出了检索增强生成(RAG)作为一种解决策略。通过结合外部数据库的知识,RAG旨在提高模型的准确性和可靠性,并使其能够持续更新知识。文章详细分析了RAG的发展,从基础到高级和模块化的RAG,并探讨了这一领域的最新进展、挑战和未来发展方向。
关于代码如何赋能大型语言模型成为智能代理的综述
https://arxiv.org/abs/2401.00812
文章对近年来出现的以代码为中心的大型语言模型(LLM)进行了综合分析,探讨了代码对于LLM推理能力的潜在影响,以及通过代码预训练的LLM作为智能代理在决策过程中的优势。文章详细解释了代码语料库对于增强LLM推理和决策功能的关键作用,并对如何将这些模型应用于具体任务进行了讨论,展示了LLM在理解和执行任务方面的新境界。
被OpenAI、Mistral AI带火的MoE是怎么回事?一文贯通专家混合架构部署
https://mp.weixin.qq.com/s/LZ5BUYjNM6gwX4whoEZNYg
专家混合 (MoE) 是 LLM 中常用的一种技术,旨在提高其效率和准确性。这种方法的工作原理是将复杂的任务划分为更小、更易于管理的子任务,每个子任务都由专门的迷你模型或「专家」处理。
早些时候,有人爆料 GPT-4 是采用了由 8 个专家模型组成的集成系统。近日,Mistral AI 发布的 Mixtral 8x7B 同样采用这种架构,实现了非常不错的性能。OpenAI 和 Mistral AI 的两波推力,让 MoE 一时间成为开放人工智能社区最热门的话题 。本文将介绍 MoE 的构建模块、训练方法以及在使用它们进行推理时需要考虑的权衡因素。









![[MySQL]基础的增删改查](https://img-blog.csdnimg.cn/direct/d22f8da3fb03494e90ac850b3b439739.png)