先看效果
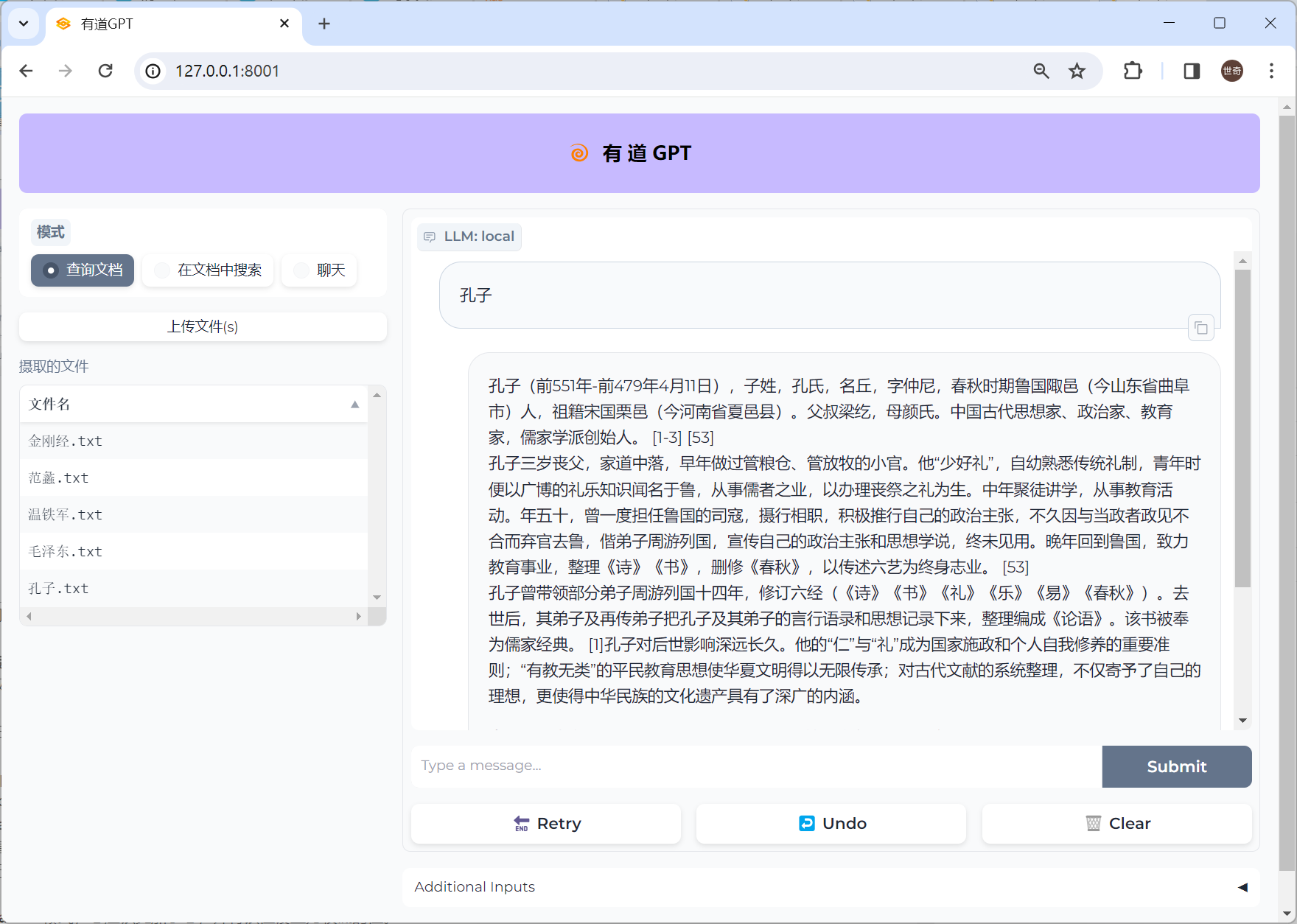
他可以从上传的文件中提取内容作为答案。
上传文件摄取速度
摄取速度取决于您正在摄取的文档数量以及每个文档的大小。为了加快摄取速度,您可以在配置中更改摄取模式。
存在以下摄取模式:
simple:历史行为,一次按顺序摄取一份文档
batch:使用批量读取、解析和嵌入多个文档(批量读取,然后批量解析,然后批量嵌入)
parallel:并行读取、解析和嵌入多个文档。这是本地设置最快的摄取模式。要更改摄取模式,您可以使用embedding.ingest_mode配置值。默认值为simple。
要配置用于并行或批量摄取的工作线程数量,您可以使用embedding.count_workers配置值。如果将此值设置得太高,可能会耗尽内存,因此设置此值时请务必小心。默认值为2。对于batch模式,您可以轻松地将此值设置为 CPU 上可用的线程数,而不会耗尽内存。对于parallel模式,您应该更加小心,并将该值设置为较低的值。
对于想要对硬件施加更多压力的用户来说,以下配置应该足够了:
embedding:
ingest_mode: parallel
count_workers: 4
如果您的硬件足够强大,并且您正在加载大量文档,则可以增加工作人员的数量。建议您自己进行测试以找到适合您的硬件的最佳值。
支持的文件格式
privateGPT 默认支持所有包含明文的文件格式(例如,.txt文件.html等)。然而,这些基于文本的文件格式仅被视为文本文件,并且不以任何其他方式进行预处理。
它还支持以下文件格式:
.hwp
.pdf
.docx
.pptx
.ppt
.pptm
.jpg
.png
.jpeg
.mp3
.mp4
.csv
.epub
.md
.mbox
.ipynb
.json
请注意以下细微差别:虽然privateGPT支持这些文件格式,但可能需要在 python 虚拟环境中安装额外的依赖项。例如,如果您尝试提取.epub文件,privateGPT可能会失败,而是会显示一条解释性错误,要求您下载安装此文件格式所需的依赖项。
其他文件格式也可能有效,但它们将被视为纯文本文件(换句话说,它们将作为.txt文件被摄取)。
重置本地文档数据库
在本地设置中运行时,您只需删除local_data文件夹的所有内容(.gitignore 除外)即可删除所有摄取的文档