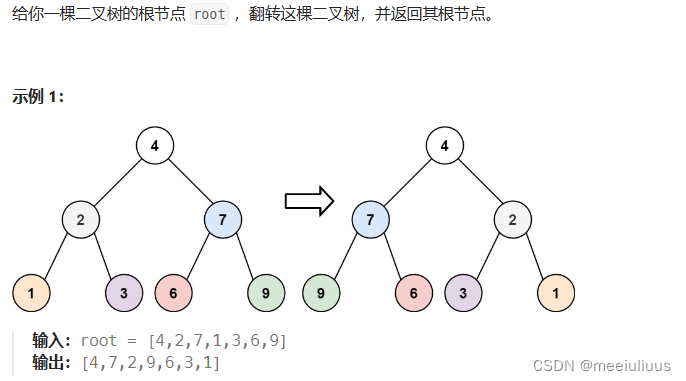
Playwright框架:
背景介绍:
Playwright 是微软开发的 Web应用 的 自动化测试框架 。selenium相对于Playwright慢很多,因为Playwright是异步实现的,但是selenium是同步的,就是后一个操作必须等待前一个操作。
selenium是由相应的厂商提供相应的驱动,python+驱动执行相当自动化操作,缺点是如果你得浏览器驱动和你得浏览器版本不对应,你得selenium就会报错,而且你需要时刻关注版本得问题。
Playwright 是基于 Node.js 语言开发的,而且不需要再重新下载一个浏览器驱动,相当于已经写好了,仅仅需要安装这个库即可。
pip install playwright -i https://pypi.tuna.tsinghua.edu.cn/simple/
playwright install
一次会下载三个浏览器,chromium、firefox、webkit,但是其实不用下那么多,下一个就好,推荐使用chromium,命令如下
playwright install chromium

所以,这个不会自动更新,因为我们使用固定的。
常用属性:
-
对象属性:
-
p = sync_playwright() 创建一个playwright 进程
-
browser = p.chromium.launch(headless=False) 创建一个浏览器对象,headless 表示无头
-
page = browser.new_page() 创建一个页面对象
-
-
动作连
- page.goto() 前往某个网站
- page.title() 获取标题
- page.locator(‘css选择器’) 定位
- page.fill(‘keyword’) # 输入某些值
- page.click() # 点击
-
等待时间
- page.wait_for_timeout(1000) , 单位是
毫秒,因为Playwright 框架是异步的,time.sleep() 在 Playwright 中式不推荐使用的,因为time.sleep() 可能破坏Playwright的相关处理逻辑。
- page.wait_for_timeout(1000) , 单位是
demo实战:
from playwright.sync_api import sync_playwright # 同步客户端库
import time
print(" 启动 playwright driver 进程-------")
p = sync_playwright().start()print("启动浏览器,返回 Browser 类型对象--------")
browser = p.chromium.launch(headless=False)print("创建新页面,返回 Page 类型对象,页面操作对象")
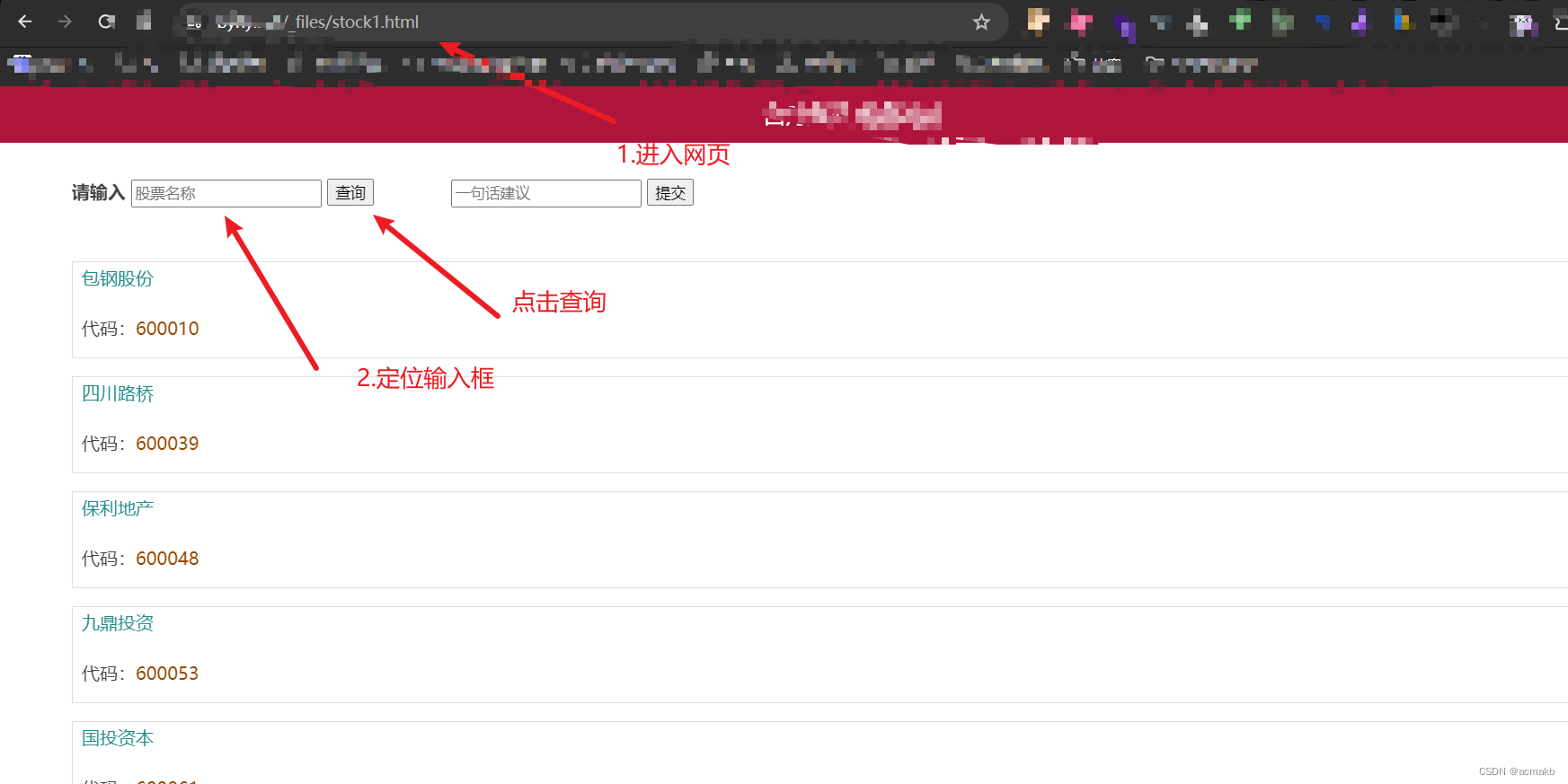
page = browser.new_page()# goto 前往某一个页面
page.goto("https://www.byhy.net/_files/stock1.html")
print(page.title()) # 打印网页标题栏
time.sleep(2)# 根据css选择器 找到选择框 输入内容
page.locator('#kw').fill('通讯') # 输入通讯
page.locator('#go').click() # 点击查询
# # page.locator('#kw').fill('通讯\n') 可以代替上面的两行
time.sleep(3)
# 打印所有搜索内容
lcs = page.locator(".result-item").all()
for lc in lcs:print(lc.inner_text())# 关闭浏览器
browser.close()
# 关闭 playwright driver 进程
p.stop()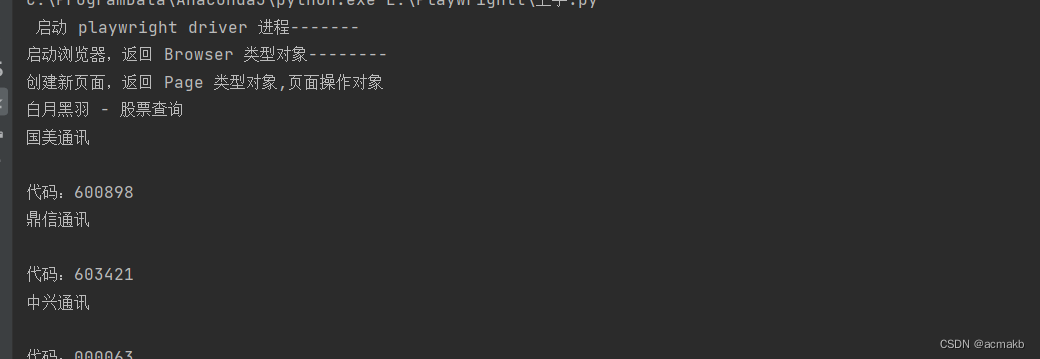
改进:
但是上面的写法非常荣誉,既要创建进行,又要创建各种对象,不利于开发和维护,可以使用 with as 会话管理从而自动管理进程,不需要手动调用 start() 和 stop()。
from playwright.sync_api import sync_playwrightwith sync_playwright() as p:browser = p.chromium.launch(headless=False)page = browser.new_page()page.goto("https://www.byhy.net/_files/stock1.html")print(page.title())page.locator('#kw').fill('通讯\n')page.locator('#go').click()# 打印所有搜索内容lcs = page.locator(".result-item").all()for lc in lcs:print(lc.inner_text())browser.close()
代码助手:
输入下面的指令后,会自动弹出两个框框,我们只需要点击点击,右侧就会生成代码,这样我们的工作量会大大减小。
playwright codegen

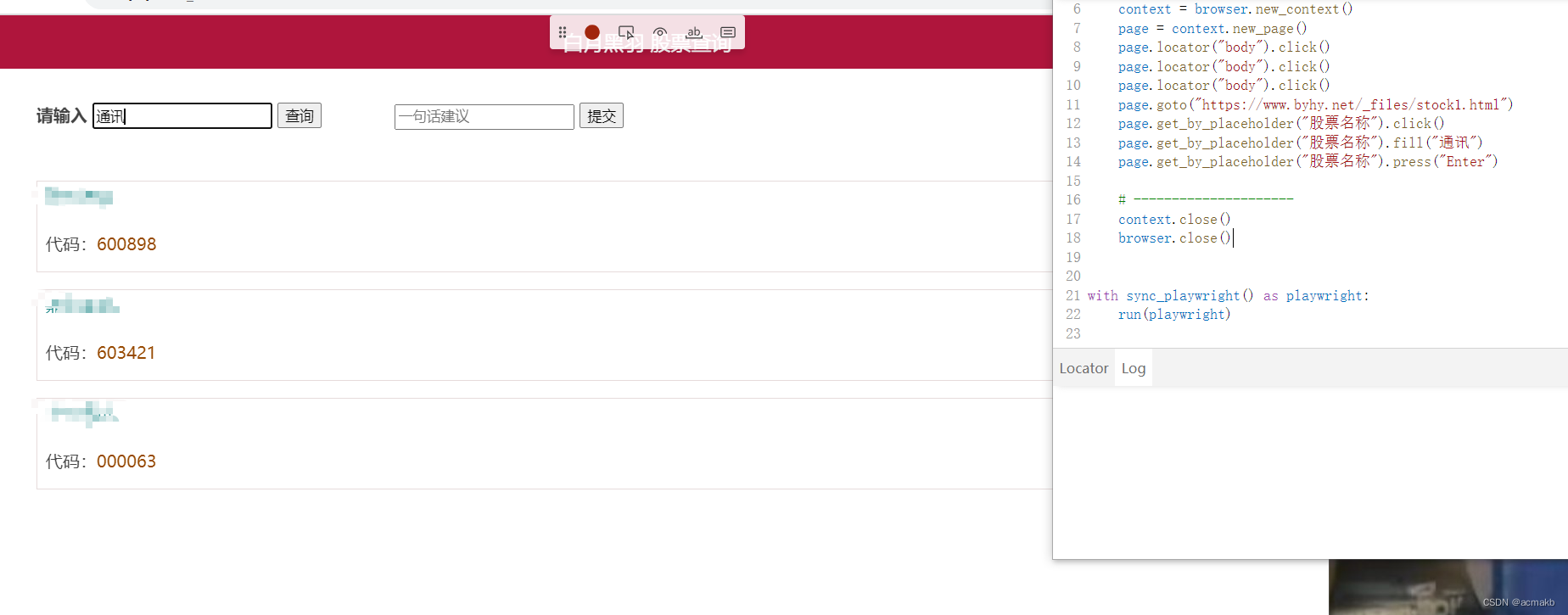
右侧是代码,但是不能获取元素,只能模拟动作连等等。
context = browser.new_context()page = context.new_page()page.locator("body").click()page.goto("https://www.byhy.net/_files/stock1.html")page.get_by_placeholder("股票名称").click()page.get_by_placeholder("股票名称").fill("通讯")page.get_by_placeholder("股票名称").press("Enter")# ---------------------context.close()browser.close()with sync_playwright() as playwright:run(playwright)
跟踪:
playwright同时提供了跟踪功能,就是把playwright 的轨迹信息从头到尾到 保存下来,包括 路径 截图等待。
from playwright.sync_api import sync_playwrightp = sync_playwright().start()
browser = p.chromium.launch(headless=False)# 创建 BrowserContext对象
context = browser.new_context()
# 启动跟踪功能 截图 资源
context.tracing.start(snapshots=True, sources=True, screenshots=True)page = context.new_page()
page.goto("https://www.byhy.net/_files/stock1.html")# 搜索名称中包含 通讯 的股票
page.locator('#kw').fill('通讯')
page.locator('#go').click()page.wait_for_timeout(1000) # 等待1秒lcs = page.locator(".result-item").all()
for lc in lcs:print(lc.inner_text())# 搜索名称中包含 软件 的股票
page.locator('#kw').fill('软件')
page.locator('#go').click()page.wait_for_timeout(1000) # 等待1秒lcs = page.locator(".result-item").all()
for lc in lcs:print(lc.inner_text())# 结束跟踪
context.tracing.stop(path="trace.zip")browser.close()
p.stop()
总结:
在本文中,我们详细介绍了Playwright框架,并与Selenium进行了比较。我们了解了安装配置流程,并通过实战项目展示了其强大的功能和灵活性。我们还探讨了常用属性、代码助手和跟踪功能,为读者提供了全面的指南。
通过比较Playwright和Selenium,我们可以看到Playwright在自动化测试领域的优势。其跨浏览器和跨平台的特性,以及对现代Web技术的全面支持,使其成为开发人员和测试人员的首选。无论是构建复杂的测试脚本还是进行简单的页面交互,Playwright都能提供强大而可靠的解决方案。
我们鼓励读者在实际项目中尝试使用Playwright框架,体验其简洁的API和出色的性能。无论您是开发人员、测试人员还是质量保证专家,Playwright都将成为您工作中的得力助手。
希 望本文能够为您提供有关Playwright框架的全面了解,并帮助您在自动化测试领域取得更好的成果。如果您有任何问题或反馈,请随时与我们联系。祝您愉快地使用Playwright!