总结
14-数值稳定性(梯度爆炸、梯度消失)
尤其是对于深度神经网络(即神经网络层数很多),最终的梯度就是每层进行累乘

理论
t:为第t层
y:不是之前的预测值,而是包括了损失函数L
所有的h都是向量(向量关于向量的导数 是矩阵)


(博客):
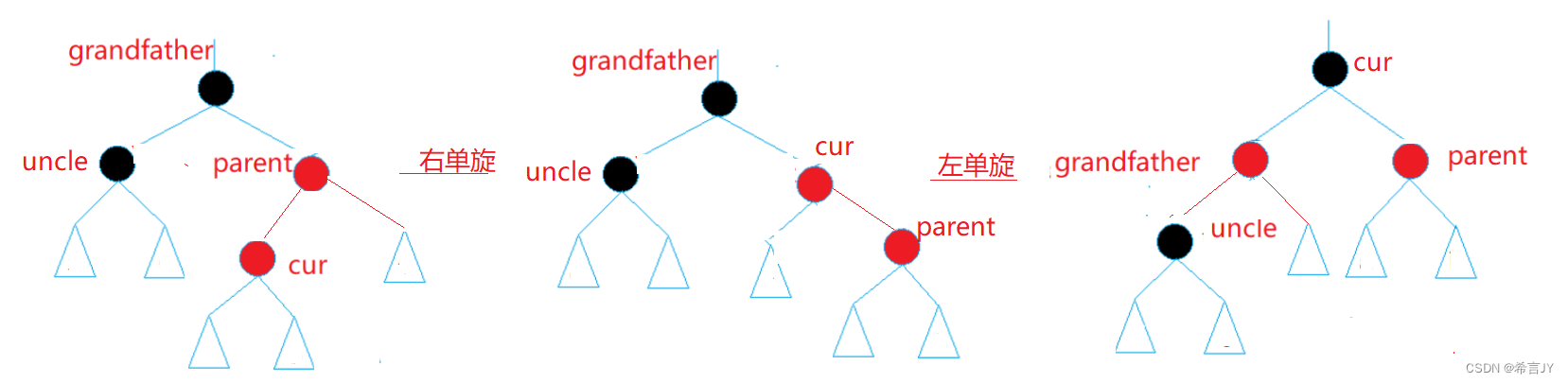
① MLP:多层感知机。
② 对角矩阵(diagonal matrix)是一个主对角线之外的元素皆为0的矩阵,常写为diag(a1, a2, …, an)。
③ diag * W 把diag和W分开看。这就是个链式求导,diag是n维度的relu向量對n维度relu的输入的求导,向量对自身求导就是对角矩阵。
(可以看邱锡鹏的书讲的很清楚,这里是按分母布局计算的)

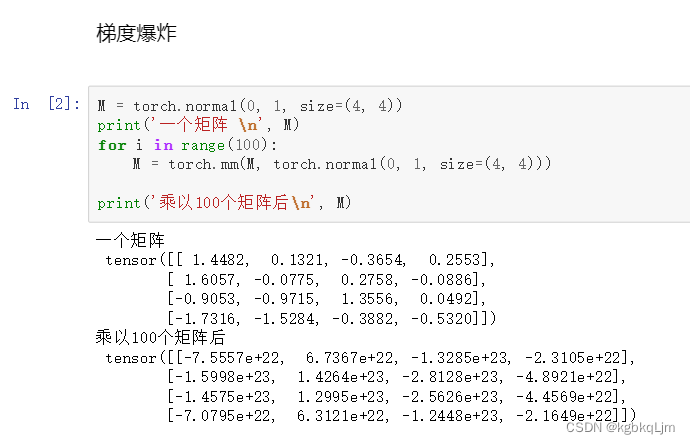
梯度爆炸
【当使用ReLU作为激活函数时】
① 当W元素值大于1时,层数很深时,连乘会导致梯度爆炸。
relu的时候,这里其实 diag() 里面是 只有0或1,和单位阵类似,在乘上 权重矩阵,所以最终的值,来自于前层的权重矩阵,爆炸或消失,就看前层矩阵权重的大小了

【梯度爆炸导致的问题】
(1)计算的值超出值域
infinity:无穷大
我们使用GPU时一般用 16位浮点数(区间为 6e-5 ~ 6e4)
(2)对学习率敏感的问题:
lr大,更新权重变得更大,梯度就更大,从而权重更更大,越来越爆炸

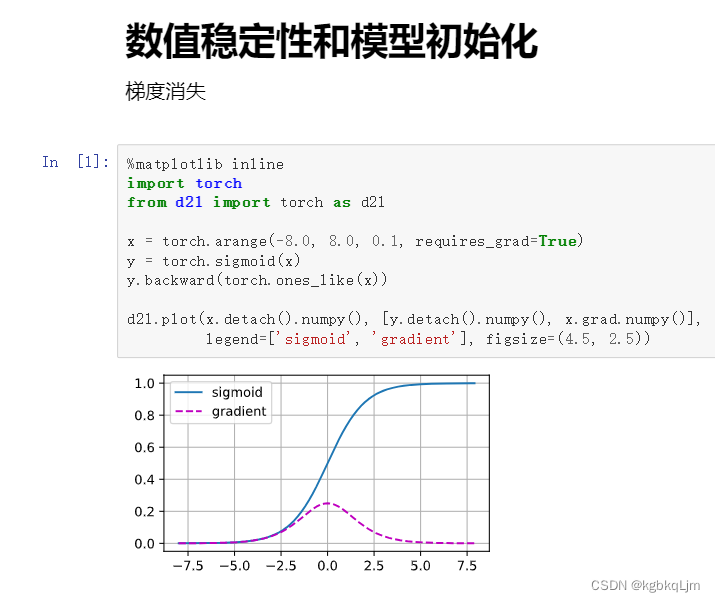
梯度消失
① 蓝色为原sigmoid函数,黄色为梯度函数即sigmoid的导函数。
横轴为 激活函数的输入x
下图存在的问题是当 输入稍微大一点(如是6时),梯度就变得很小 甚至接近于0了
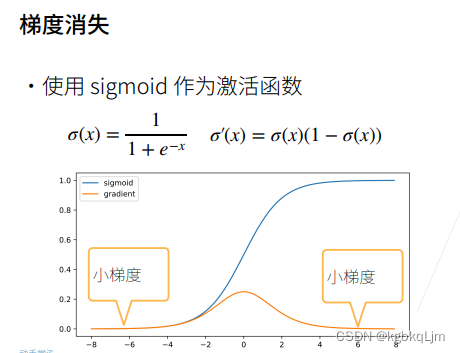
② 当激活函数的输入稍微大一点时,它的导数就变为接近0,连续n个接近0的数相乘,最后的梯度就接近0,梯度就消失了。

【梯度消失导致的问题】
(1)对于梯度是一个很小的数尤其是16位浮点数时很小的数,基本可以将其当作0
(3)梯度反向传播时 是从顶部开始向底部传播的(感觉顶部就是靠近输出层的那侧),顶部的梯度可能还ok, 随着网络加深、小数乘法次数越来越多,到达底部(即靠近输入层)时 梯度就很小很小,这就意味着 这个神经网络和一个很浅的神经网络是没有本质区别的(因此 ResNet就出现了)

代码
14-模型初始化和激活函数
具体来说,使每一层的输出和梯度都是均值为0、方差为固定数的随机变量,在这个目标下:
权重初始化可以使用Xavier,激活函数选择relu、tanh或经 变换后的sigmoid

概述
【目标】让梯度值在合理范围内
【目标的实现方式】(本节讲方式三,一、二后面讲)
(1)让乘法变加法:
CNN中用的多的是 ResNet
RNN中用的多的是LSTM(带时序的)
(2)归一化(不管原梯度多大,都将其拉到 均值为0方差为1的范围内)
或 设定阈值(如梯度大于5,则置为5,小于-5,则置为-5)
(3)合理的权重初始化和激活函数(即 合理选择w和sigma)

权重和激活函数的合理化的具体实现
权重初始化(暂时假设没有激活函数)
【本节最终结果】基于Xavier可以折中的视线本节的目标(目标如下)
【目标】我们希望设计的神经网络满足下面的特点、性质:
让每一层的输出和梯度都符合同一种分布或同一个区间内:如第一层的输出 看成均值为0方差为1的随机变量,那么第二层、…、第n层 也让其为这种分布。
如一层输出的特征向量是100维的(即 有100个元素),则 将其看成100个随机变量
【正向】E[hit]:t为第t层,i为该层的第i个元素。即 对所有的t和i ,正向的输出 期望(即E)为0,方差为a(一个常数)。
【反向】与正向同理

【如何实现才能 满足上面的特点呢】
1.如何通过权重合理的初始化来得到上述性质
分析与引言:在训练开始时更容易出现数值不稳定问题:
例如,远离最优解时 更容易出现数值不稳定的地方(即梯度大),在最优解附近时,梯度又相对较小

举例:
一、首先看要实现的目标中的 正向的均值
【两个假设】
① 假设权重wti,j是独立的同分布(即下图 iid),那么wti,j的均值就为0、方差为γt(同理t为层数)(如黄框)。
wti,j:第t层的第i行第j列的权重
γt:权重wti,j的方差
② 假设第t层的输入hit-1与第t层的权重wti,j是相互独立的(即当前层的输入和当前层的权重是独立的)(如蓝框)。
nt:当前第t层的输出的维度
nt-1:当前第t层的输入的维度


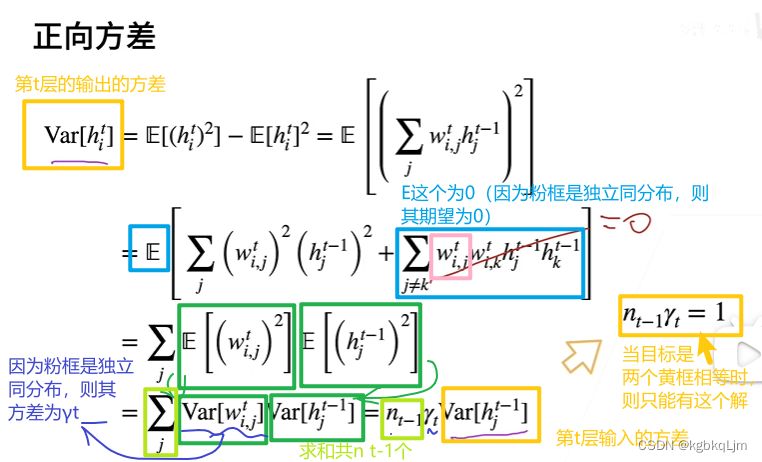
二、下面看要实现的目标中的 正向的方差:
【方差公式】方差等于平方的期望减去期望的平方:方差D(X)=E(X^ 2)-E(X)^2
(红框)对于和的平方 等价于 每一项的平方+不相等的交叉项的乘积和
(蓝框)第二行的加好后面的累加可以划掉的原因是 因为 之前假设了wti,j是独立的同分布(即 iid),那么wti,j的均值就为0,即E(wti,j)=0,即 E(第二行第二项)=0
(绿框、第三行到第四行)方差 = 平方的期望 - 期望的平方 现在期望的平方等于0
nt-1:当前第t层的输入的维度
三、下面看下反向的均值和方差:
注:(AB)转置=B转置xA转置
下图内容和正向的类似,老师就没细推

【Xavier初始化】基于该方式对某层权重初始化时,该层权重的初始化会根据该层的输入维度、输出维度来决定(如权重的方差),尤其是当 输入输出维度不一定、或网络变化比较大时,可以根据输入输出维度来适配权重,使得输出的方差和梯度都在恒定(合理)的范围内
上面得到的两个nγ的条件难以同时满足(如下图红框),除非 nt-1=nt 即第t层的输入维度=输出维度,但很难
基于Xavier(权重初始化的一种方法,即权重初始化时的方差是由输入维度和输出维度决定的):既然不能同时满足,那就取个折中。即 给定当前第t层的输入维度nt-1和输出维度nt的大小,那么就可以由这俩得到当前第t层的权重的方差γt,那么,对于当前第t层的权重初始化时 所选择的分布有如下(分布情况都由输入输出维度计算得到):
如果用正态分布,则
如果用均匀分布,则

激活函数选择(通过选择激活函数,令数值稳定)

个人感觉本节的内容是在上节内容的假设的基础上,即 包括有 E[wi,jt]=0(可解释下图绿框)
假设激活函数是线性的(只是为了简单理论分析,实际上不可能用线性的激活函数)
且如果想令E[hit]=0,则β=0,即激活函数是过原点的
其实下图中绿框=0并不太懂, 为什么 E[hi’]=0

那么如果想输出的方差=输入的方差,只有α=1
这就说明:为了使前向的输出为 均值为0、方差为固定值,则要求 线性激活函数的α=1、β=0,即为 输入x本身
反向部分同理:(不细讲)

最后,意味着激活函数 必须是f(x)=x
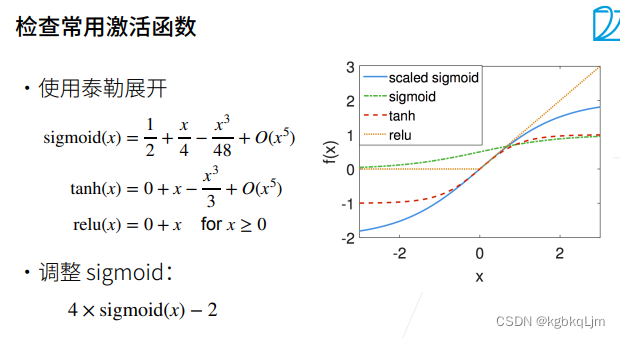
那么检查一下真正的激活函数(因为激活函数都是非线性的,而上面是以线性激活函数举例的)(如使用泰勒展开):
【此处同时从 数据稳定性的角度解释了 为什么relu的效果好】
可以发现下图中tanh和relu在原点处基本都是f(x)=x,虽然sigmoid不过原点,但是 经过调整后的sigmoid(如下图中蓝线,即 乘四再减二后)也是过原点且在原点处近似为f(x)=x(即 经过调整后的sigmoid函数也能解决以前原sigmoid存在的问题)
为何只关注在0点附近的表现是否能满足f(x)=x的要求:因为一般神经网络的权重w的取值都是在0附近的
14-QA

inf就是太大了,即一般是lr太大或 权重初始化时太大了
nan一般是 除0了
解决:
合理初始化权重(权重的初始 一般均值为0,方差小一点,当能出现正确的值之后 再慢慢调大权重(的方差)使得训练有进展)
选择合适的激活函数、
选择合适大小的lr(一般是把lr一直往小调 直到inf、nan不出现)
2.不是单独的relu来拟合,而是relu+学习到的权重w 共同作用(只是基于relu提供非线性的特性)
一般是 数值稳定性出现了问题:可尝试调小lr
后面会讲各种方法 增大数值稳定性
4.一般来说nan就是梯度太大造成的
虽然说深度学习相对于传统的机器学习如SVM等,对数学要求不高 即用神经网络 只要其可导即可,但是 学好数学还是很有必要的
代码决定下限,数学决定上限
数学能力(理解能力)和代码能力(写代码、调参、解决问题的能力,调东西快)
以电脑为例:数学能力为内存,代码能力为CPU
CPU决定你单位时间能运行多少东西、完成多少任务
内存决定你能跑多复杂的任务(数学不好的时候,能做的东西就变少)

6.32就会变好,64位就更好了,传统的高性能计算都用64位的、32位是大家常用的
fp16用的越来越少,现在越来越多用bfloat
7.梯度消失产生的原因有很多种,sigmoid只是其中的一种可能
用ReLU替换 可以降低 产生梯度消失的概率,但不确保一定能完全解决
爆炸的产生和激活函数无关,一般都是由每层的输出太大 然后多个层累乘引起的

9.后面讲
- 相当于100个1.5相乘或100个1.5相加
11.后面讲BN

课程中只是说 在正态分布的假设条件下更容易 推导出、实现出 输出值在合理的范围内, 实际上什么分布都行
13.Xavier是比较好用的
14.两回事,后面讲
15.可以自己搜一下,有
16.为了简单

18.是我们的一个初始化
19.正态分布做推导比较容易
20.这里不讲了

21.没有。数值是一个区间,将其拉到什么范围都没关系,这个区间是使得硬件处理起来比较容易,从数学上来说 无论在什么区间都不会影响模型的效果
22.只是说 做了这个变换后, 变换后的sigmoid函数在 0点处近似于 f(x)=x函数
23.后面看看有没有时间
24.就ReLU 简单点

25.权重是在 每次迭代 即每个batch (即每个iterator),
一个epoch是指完整扫完一次数据, 此时已经更新很多次了
26.各种技术都是在缓解、减轻问题,但不是完全解决,用ResNet只是会让数值稳定性更好一点
【整个深度学习的进展都是在 让数值更加稳定】
没听懂,多模态问题?
28.模型的设计是一个很大的问题,后面碰到再讲
29.可以这么理解, 限制均值和方差 可以 降低 极大值、极小值数据出现的概率
15-实战:Kaggle房价预测和课程竞赛:加州2020年房价预测
实战
1.先定义一些函数方法 以从网上下载一些数据(跳过)
2.使用pandas读取并处理数据

import hashlib
import os
import tarfile
import zipfile
import requests
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
%matplotlib inlineDATA_HUB = dict()
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'def download(name, cache_dir=os.path.join('.', '01_data/02_DataSet_Kaggle_House')):"""下载一个DATA_HUB中的文件,返回本地文件名"""assert name in DATA_HUB, f"{name} 不存在于 {DATA_HUB}."url , sha1_hash = DATA_HUB[name]os.makedirs(cache_dir, exist_ok=True)fname = os.path.join(cache_dir, url.split('/')[-1])if os.path.exists(fname):sha1 = hashlib.sha1()with open(fname,'rb') as f:while True:data = f.read(1048576)if not data:breaksha1.update(data)if sha1.hexdigest() == sha1_hash:return fnameprint(f'正在从{url}下载{fname}...')r = requests.get(url,stream=True,verify=True)with open(fname,'wb') as f:f.write(r.content)return fnamedef download_extract(name, folder=None):"""下载并解压zip/tar文件"""fname = download(name)base_dir = os.path.dirname(fname)data_dir, ext = os.path.splitext(fname)if ext == '.zip':fp = zipfile.ZipFile(fname, 'r')elif ext in ('.tar', '.gz'):fp = tarfile.open(fname, 'r')else:assert False, '只有zip/tar文件可以被解压缩'fp,extractall(base_dir)return os.path.join(base_dir, folder) if folder else data_dirdef download_all():"""下载DATA_UHB中的所有文件"""for name in DATA_HUB:download(name)DATA_HUB['kaggle_house_train'] = (DATA_URL + 'kaggle_house_pred_train.csv','585e9cc9370b9160e7921475fbcd7d31219ce')
DATA_HUB['kaggle_house_test'] = (DATA_URL + 'kaggle_house_pred_test.csv', 'fal9780a7b011d9b009e8bff8e99922a8ee2eb90')
train_data = pd.read_csv(download('kaggle_house_train'))
test_data = pd.read_csv(download('kaggle_house_test'))
print(train_data.shape) # 1460个样本,80个te特征,1个标号label
print(test_data.shape) # 测试样本没有标号labelprint(train_data.iloc[0:4,[0,1,2,3,-3,-2,-1]]) # 前面四行的某些列特征

打印出前四行 前面四列+后面三列看一下
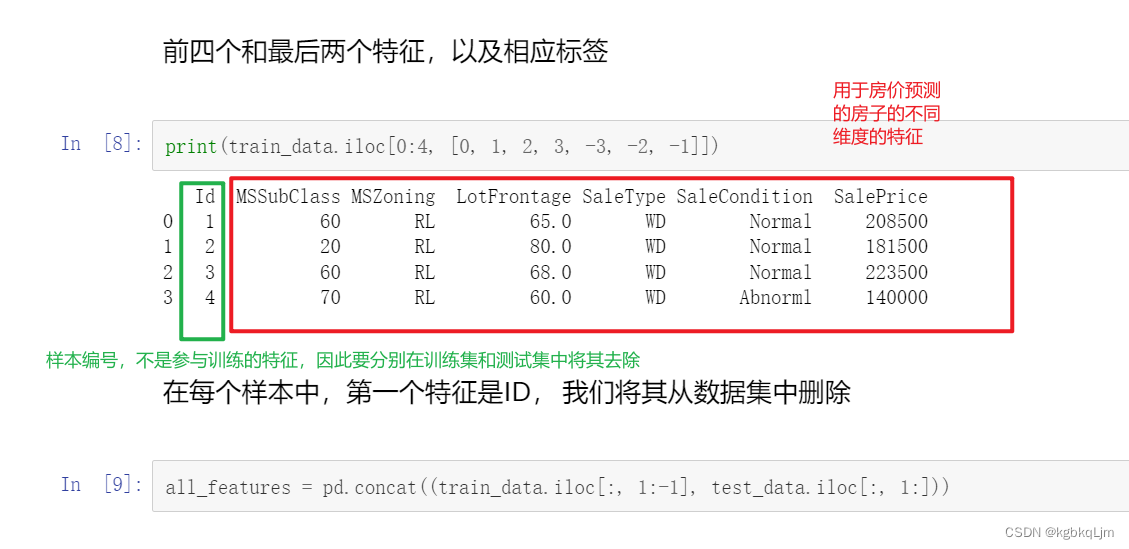
# 在每个样本中,第一个特征是ID,将其从数据集中删除
all_features = pd.concat((train_data.iloc[:,1:-1],test_data.iloc[:,1:]))
print(all_features.iloc[0:4,[0,1,2,3,-3,-2,-1]])

4.标准化处理数据之处理数值型特征元素
注:这里是将训练集和测试集的数据放在一起计算均值和方差(因为是比赛,肯定有单独的测试集。实际场景下可能需要在训练集上这么做 计算均值和方差 再应用到测试集上)

# 将所有缺失的值替换成相应特征的平均值
# 通过将特征重新缩放到零均值和单位方差来标准化数据
print(all_features.dtypes) # 可以知道每一列分别为什么类型特征
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index # 当值的类型不是object的话,就是一个数值
print(numeric_features)
# 注:这里是将训练集和测试集的数据放在一起计算均值和方差(因为是比赛,肯定有单独的测试集。实际场景下可能需要在训练集上这么做 计算均值和方差 再应用到测试集上)
all_features[numeric_features] = all_features[numeric_features].apply(lambda x: (x - x.mean()) / (x.std())) # 对数值数据变为总体为均值为0,方差为1的分布的数据。
all_features[numeric_features] = all_features[numeric_features].fillna(0) # 将数值数据中not number的数据用0填充(因为均值是0,所以相当于将所有nan置为均值)

5.标准化处理数据之处理字符串型特征元素
对于字符串类型数据,使用one-hot:例如 如果某种特征具体有五种值,则 该种特征会产生五种特征, 然后 分别对应起来用 0或1表示
基于pandas中的get_dummies方法来实现这个效果,同时也处理了 unknow的元素
此时因为 对 字符串型特征元素(即离散值)进行one-hot编码后, 特征维度增加到了331

6.将数据转成pytorch中的tensor
之前是将训练和测试集数据一起处理了,此处将二者分开
[:n_train]表示[0,n_train),[n_train:]表示[n_train,n_train+n_test))
python中默认是float64,此处转为float32


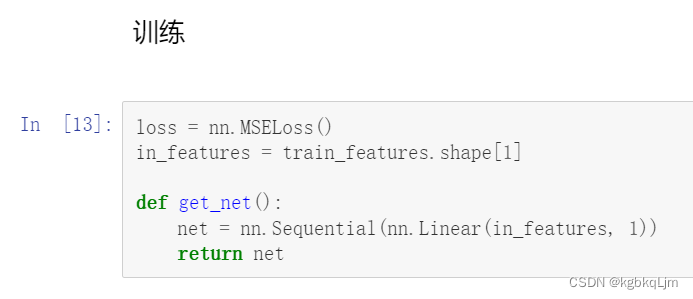
7.训练:用单层线性回归模型
8.使用相对误差:(使用log)
此处没有像之前那样 直接用 真实值和预测值的误差作为 误差,但此处考虑到房价的变化范围可能很大(如 10w-100w),如果直接用 绝对误差,则 房价大的误差的权重可能会大,不合理

def log_rmse(net, features, labels):clipped_preds = torch.clamp(net(features),1,float('inf')) # 把模型输出的值限制在1和inf之间,inf代表无穷大(infinity的缩写) rmse = torch.sqrt(loss(torch.log(clipped_preds),torch.log(labels))) # 预测做log,label做log,然后丢到MSE损失函数里return rmse.item()
此处使用的是adam(可认为是比较平滑的SGD,其对lr没有那么敏感)


# K折交叉验证
def get_k_fold_data(k,i,X,y): # 给定k折,给定第i折,X、y分别为输入的特征和对应的标签label。最终返回相应的训练集、测试集assert k > 1fold_size = X.shape[0] // k # 每一折的大小为样本数除以k。注:// 是整除X_train, y_train = None, Nonefor j in range(k): # 每一折idx = slice(j * fold_size, (j+1)*fold_size) # 每一折的切片索引间隔 X_part, y_part = X[idx,:], y[idx] # 把每一折对应部分取出来if j == i: # i表示第几折,把它作为验证集X_valid, y_valid = X_part, y_partelif X_train is None: # 第一次看到X_train,则把它存起来 X_train, y_train = X_part, y_partelse: # 后面再看到,除了第i外,其余折也作为训练数据集,用torch.cat将原先的合并 X_train = torch.cat([X_train, X_part],0)y_train = torch.cat([y_train, y_part],0)return X_train, y_train, X_valid, y_valid # 返回训练集和验证集

# 当给定各种超参数(num_epochs, learning_rate, weight_decay,batch_size)后,返回每一则的 训练loss和验证loss的平均值
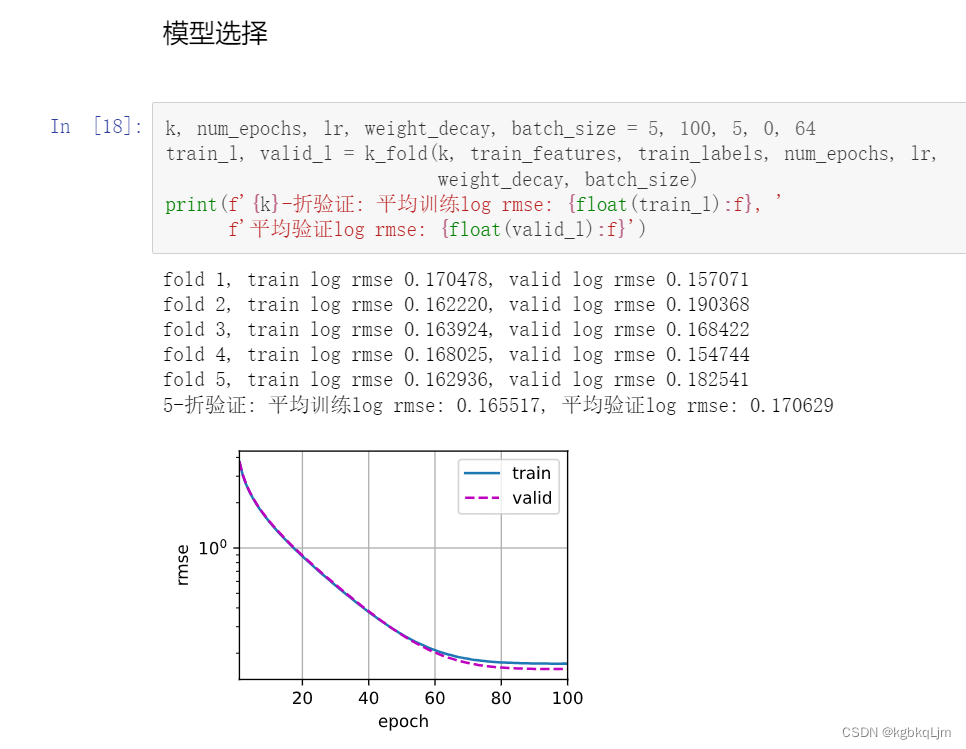
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,batch_size):train_l_sum, valid_l_sum = 0, 0for i in range(k):data = get_k_fold_data(k, i, X_train, y_train) # 把第i折对应分开的数据集、验证集拿出来 net = get_net()# *是解码,变成前面返回的四个数据train_ls, valid_ls = train(net, *data, num_epochs, learning_rate, weight_decay, batch_size) # 训练集、验证集丢进train函数 train_l_sum += train_ls[-1]valid_l_sum += valid_ls[-1]if i == 0:d2l.plot(list(range(1, num_epochs + 1)), [train_ls,valid_ls],xlabel='epoch',ylabel='rmse',xlim=[1,num_epochs],legend=['train','valid'],yscale='log')print(f'fold{i+1},train log rmse {float(train_ls[-1]):f},'f'valid log rmse {float (valid_ls[-1]):f}')return train_l_sum / k, valid_l_sum / k # 求和做平均
可以看到5则中每一则的情况以及最后平均的结果
(看出没有过拟合,即train和test效果差不多)
同学们要做的就是 设计并使用不同的神经网络(后面会讲)以及不断调超参数 ,看验证集的 相对误差rms 选择其中最好的超参数
当选择好最好的超参数后,再在 完整的训练集上训练一次,再测试一下
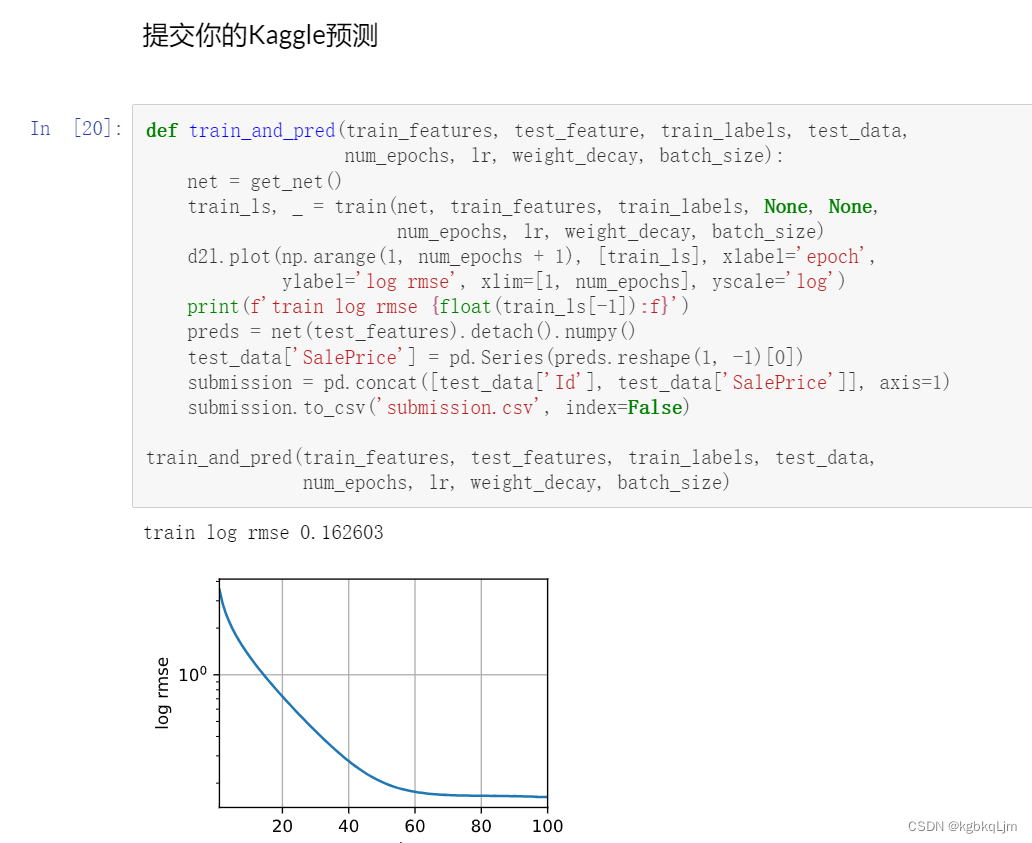
def train_and_pred(train_features, test_feature, train_labels, test_data, num_epochs, lr, weight_decay, batch_size):net = get_net()train_ls, _ = train(net, train_features, train_labels, None, None, num_epochs, lr, weight_decay, batch_size) d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',ylabel = 'log rmse', xlim=[1,num_epochs], yscale='log')print(f'train log rmse {float(train_ls[-1]):f}')preds = net(test_features).detach().numpy()test_data['SalePrice'] = pd.Series(preds.reshape(1,-1)[0])submission = pd.concat([test_data['Id'],test_data['SalePrice']],axis=1)submission.to_csv('submission.cvs',index = False)train_and_pred(train_features, test_features, train_labels, test_data,num_epochs, lr, weight_decay, batch_size)
课程竞赛

简单看了下数据,即 都有什么特征:
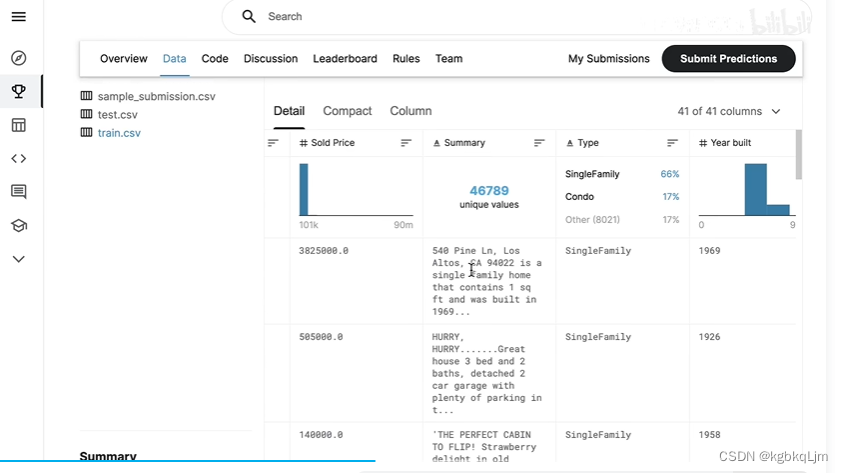
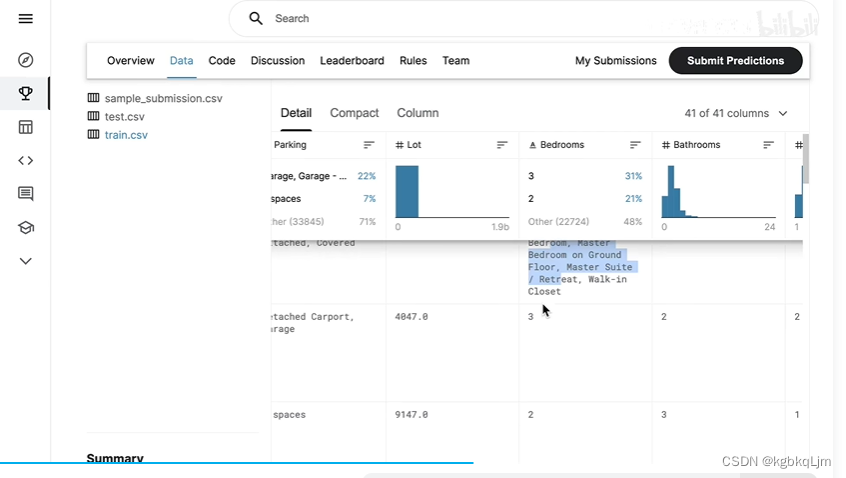
卫生间、学区房、政府估值、上次卖的价格
QA

30.加不加都没关系,因为在输入层加个BN(batch normal),后面会讲
31.特征维度减不减都没事
32.剪不剪都行
33.很基础的问题,回看之前的内容
不行,网络本身也是个超参数。
但可以随机抽取少量数据来调 得到一个大概的理想的范围,再在真实数据上微调