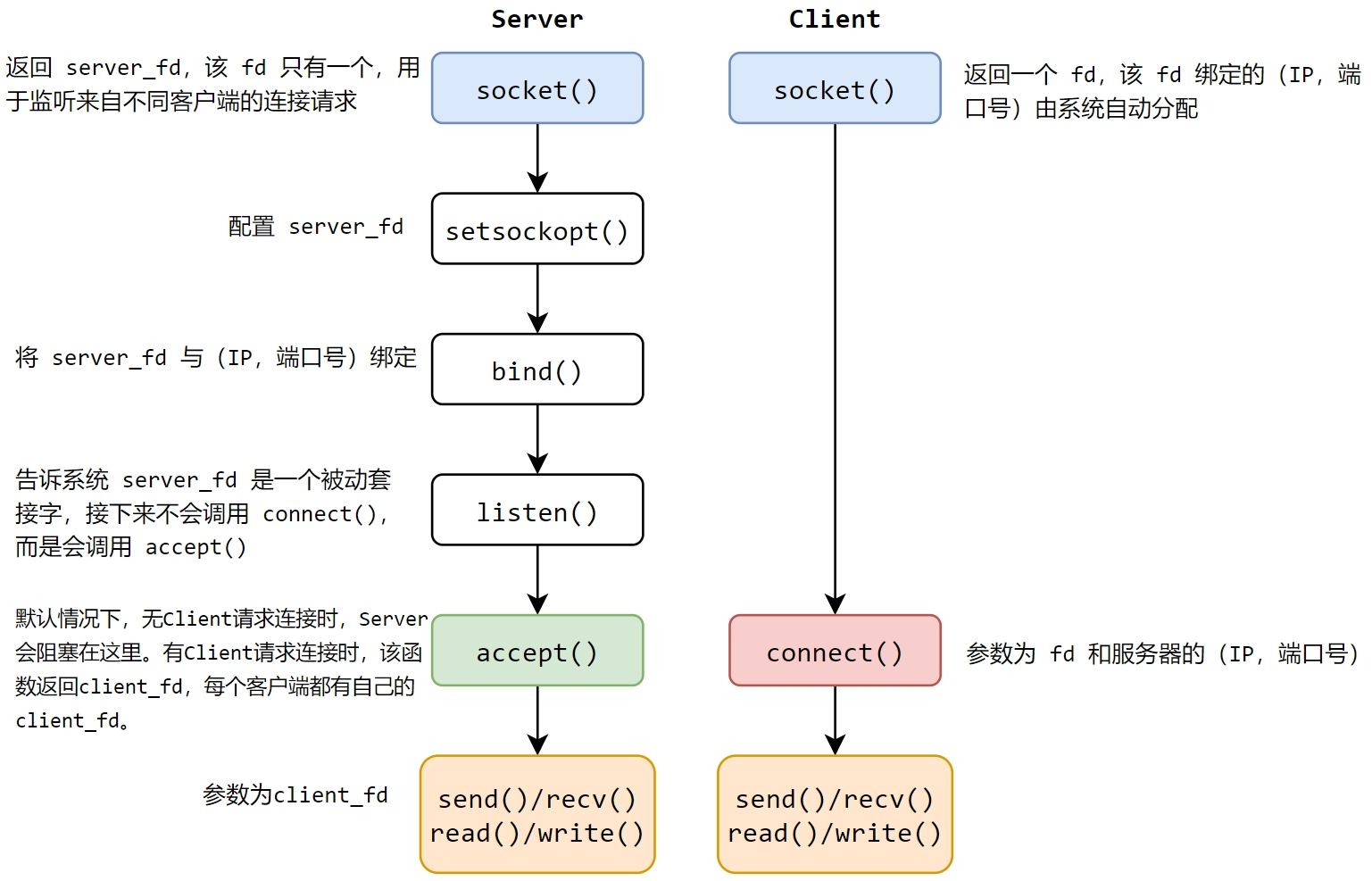
一、环境安装准备
#git拉取 bert-base-chinese 文件#创建 虚拟运行环境python -m venv myicrplatenv#刷新source myicrplatenv/bin/activate#python Django 集成nacospip install nacos-sdk-python#安装 Djangopip3 install Django==5.1#安装 pymysql settings.py 里面需要 # 强制用pymysql替代默认的MySQLdb pymysql.install_as_MySQLdb()pip install pymysql# 安装mongopip install djongo pymongopip install transformerspip install torch#安装Daphne: pip install daphne#项目通过 通过 daphne启动daphne icrplat.asgi:application二、构建项目及app模块
#创建app模块
python3 manage.py startapp cs
icrplat├── README.md
├── cs
│ ├── __init__.py
│ ├── __pycache__
│ ├── admin.py
│ ├── apps.py
│ ├── migrations
│ ├── models.py
│ ├── tests.py
│ └── views.py
├── icrplat
│ ├── __init__.py
│ ├── __pycache__
│ ├── asgi.py
│ ├── common
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── manage.py
├── myicrplatenv
│ ├── bin
│ ├── include
│ ├── lib
│ ├── pyvenv.cfg
│ └── share
├── nacos-data
│ └── snapshot
└── templates三、准备数据mongo

db.products.insertMany([{'name': '手机', 'description': '最新款智能手机,支持5G网络,高清摄像头'},{'name': '无线耳机', 'description': '降噪无线耳机,蓝牙连接,长续航'},{'name': '智能手表', 'description': '健康监测,运动记录,支持通知提醒'},{'name': '平板电脑', 'description': '轻薄便携,高性能处理器,适合办公和娱乐'},{'name': '笔记本电脑', 'description': '高性能笔记本,适合游戏和设计工作'},{'name': '相机', 'description': '专业级相机,支持4K视频拍摄'},{'name': '耳机', 'description': '高保真音质,舒适佩戴'},{'name': '充电宝', 'description': '大容量充电宝,支持快充'},{'name': '手机壳', 'description': '防摔手机壳,支持多种机型'},{'name': '路由器', 'description': '高速无线路由器,支持千兆网络'},])
四、相关代码
#################################settings.py#######################################from nacos import NacosClientfrom icrplat.common.config.nacos.NacosConfigWatcher import nacos_config_watcherimport pymysql# 强制用pymysql替代默认的MySQLdb
pymysql.install_as_MySQLdb()INSTALLED_APPS = ['django.contrib.admin','django.contrib.auth','django.contrib.contenttypes','django.contrib.sessions','django.contrib.messages','django.contrib.staticfiles','cs' #模块app 注入
]# Nacos 配置
NACOS_SERVER = "xx" # Nacos 服务器地址 ip 换成Nacos对应的IP地址
NACOS_NAMESPACE = "dev" # Nacos 命名空间
NACOS_GROUP = "MICRO_GROUP" # Nacos 分组
NACOS_DATA_ID = "aics_config_dev" # Nacos 配置 ID# 初始化 Nacos 客户端
nacos_client = NacosClient(NACOS_SERVER, namespace=NACOS_NAMESPACE)# 从 Nacos 获取 config配置
nacos_config = nacos_client.get_config(NACOS_DATA_ID, NACOS_GROUP)
# 将 JSON 字符串转换为字典
nacos_config = eval(nacos_config)
print(f"nacos_config: {nacos_config}")#解析 mysql 初始配置
mysql_config = nacos_config.get("mysql", {})
print(f"mysql_config: {mysql_config}")#解析 mongodb 初始配置
mongo_config = nacos_config.get("mongodb",{})
print(f"mongo_config: {mongo_config}")# 配置 MySQL 数据库
DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql','NAME': mysql_config.get("DATABASE_NAME"),'USER': mysql_config.get("DATABASE_USER"),'PASSWORD': mysql_config.get("DATABASE_PASSWORD"),'HOST': mysql_config.get("DATABASE_HOST"),'PORT': mysql_config.get("DATABASE_PORT", "8081"),'OPTIONS': {'charset': 'utf8mb4', # 支持更广泛的字符集},},'mongodb': { # MongoDB配置'ENGINE': 'djongo','NAME': mongo_config.get('DB_NAME'),'ENFORCE_SCHEMA': False,'CLIENT': {'host': mongo_config.get('DB_HOST'),'port': int(mongo_config.get('DB_PORT')),'username': mongo_config.get('DB_USERNAME'),'password': mongo_config.get('DB_PASSWORD'),'authSource': mongo_config.get('AUTH_DB_SOURCE'),}}
}
#使用多数据库,需要在 settings.py 中设置数据库路由。
DATABASE_ROUTERS = ['icrpPlat.dbconfig.routers.DatabaseRouter']print(f"更新前 Databases: {DATABASES}")def update_nacos_config(config):"""动态更新 MySQL 配置"""print("收到 Nacos 配置更新通知")print(f"收到更新后 config: {config}")# 使用 json.loads 解析 JSON 字符串 contentconfig_dict = json.loads(config['content'])#获取更新后的 mysql 配置mysql_config = config_dict.get("mysql", {})print(f"更新后 Databases: {mysql_config}")nacos_config_watcher.update_mysql_config(mysql_config)#获取更新后的 elasticsearch 配置mongo_config = config_dict.get("mongodb",{})print(f"更新后 mongodb: {mongo_config}")nacos_config_watcher.update_mongodb_config(mongo_config)# 监听 Nacos 配置变化
nacos_client.add_config_watcher(NACOS_DATA_ID, NACOS_GROUP, update_nacos_config)#########################nacos_config_watcher.py 方法##############################import threadingfrom django.conf import settingsclass NacosConfigWatcher:def __init__(self):# 创建一个锁对象 可以确保在同一时间只有一个线程能够访问某个共享资源,从而避免多线程环境下的数据竞争问题。self.lock = threading.Lock()"""更新myslq 配置with 语句主要用于上下文管理,通常用于处理资源的管理和释放。它的核心作用是确保在代码块执行完毕后,资源能够被正确地关闭或清理,避免资源泄漏。常见的场景包括文件操作、数据库连接、线程锁等。"""def update_mysql_config(self, mysql_config):with self.lock:settings.DATABASES['default'].update({'NAME': mysql_config.get("DATABASE_NAME"),'USER': mysql_config.get("DATABASE_USER"),'PASSWORD': mysql_config.get("DATABASE_PASSWORD"),'HOST': mysql_config.get("DATABASE_HOST"),'PORT': mysql_config.get("DATABASE_PORT", "3306"),})def update_mongodb_config(self, mongo_config):with self.lock:settings.DATABASES['mongodb'].update({'host': mongo_config.get('DB_HOST'),'port': int(mongo_config.get('DB_PORT')),'username': mongo_config.get('DB_USERNAME'),'password': mongo_config.get('DB_PASSWORD'),'authSource': mongo_config.get('AUTH_DB_SOURCE'),})#使用模块级别的单例 可以有多种实现单例的形式
nacos_config_watcher = NacosConfigWatcher()##################################urls.yml####################################
urlpatterns = [path('admin/', admin.site.urls),path('cs/handleUserRequest',cs_views.handleUserRequest, name='handleUserRequest'),path('cs/getProducts',cs_views.getProducts,name='get_product'),path('cs/getdata',cs_views.getdata,name='get_data')
]
####################################views.py################################
from django.shortcuts import renderimport json
import logging
import torch
from torch.nn.functional import cosine_similarity
from django.http import JsonResponse
from django.views.decorators.csrf import csrf_exemptfrom icrplat.common.enum.ResponeCodeEnum import ResponseCodeEnum
from icrplat.common.exception.BusinessException import BusinessException
from icrplat.common.utils.CommonResult import CommonResult
from cs.models import Productsfrom functools import lru_cachefrom icrplat.common.utils.TransformerUtils import TransformerUtils# import os
# os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"# Create your views here.
@csrf_exempt # 如果需要关闭CSRF验证,可以加上这个装饰器
def handleUserRequest(request):try:if request.method == 'POST':json_data = request.bodydata = json.loads(json_data)# 假设你需要处理的数据结构如下message = data.get('message')logging.info(f"data:{data}")else:raise BusinessException(ResponseCodeEnum.METHOD_ERROR.status_code, ResponseCodeEnum.METHOD_ERROR.status_message)return JsonResponse(CommonResult.success_data(None), json_dumps_params={'ensure_ascii': False})except BusinessException as e:return JsonResponse(CommonResult.error(e.code, e.message), json_dumps_params={'ensure_ascii': False})def getProducts(request):try:if request.method == 'GET':products_mongo = Products.objects.using('mongodb').all()else:raise BusinessException(ResponseCodeEnum.METHOD_ERROR.status_code,ResponseCodeEnum.METHOD_ERROR.status_message)# 将查询结果转化为字典或列表,确保可以被序列化为 JSON# products_data = [{'name': product.name, 'description': product.description} for product in products_mongo]# 使用列表推导式调用 to_dict 方法,将查询结果转化为字典#注意点: 需要通过实例来调用,而不是通过类直接调用products_data = [product.to_dict() for product in products_mongo]return JsonResponse(CommonResult.success_data(products_data), json_dumps_params={'ensure_ascii': False})except BusinessException as e:return JsonResponse(CommonResult.error(e.code, e.message), json_dumps_params={'ensure_ascii': False})@csrf_exempt
def getdata(request):try:if request.method == 'GET':description = request.GET.get("description")if not description:raise BusinessException(ResponseCodeEnum.PARAM_ERROR.status_code, "描述不能为空")products_mongo = Products.objects.using('mongodb').all()products_data = [product.to_dict() for product in products_mongo]# 生成商品嵌入向量product_embeddings = {product['name']: get_cached_bert_embeddings(product['description']) for product in products_data}# 生成用户查询的嵌入向量user_embeddings = get_cached_bert_embeddings(description)# 获取 计算相似度后的结果 商品product_embeddings 向量 用户user_embeddings 向量top_products = TransformerUtils.similarities(product_embeddings,user_embeddings)if not top_products:return JsonResponse({"message": "未找到相关商品"}, json_dumps_params={'ensure_ascii': False})result_with_description = {}for product_name, similarity in top_products.items():product_description = next((product['description'] for product in products_data if product['name'] == product_name),"暂无描述")result_with_description[product_name] = {"相似度": similarity,"描述": product_description}return JsonResponse(CommonResult.success_data(result_with_description), json_dumps_params={'ensure_ascii': False})else:raise BusinessException(ResponseCodeEnum.METHOD_ERROR.status_code,ResponseCodeEnum.METHOD_ERROR.status_message)except BusinessException as e:return JsonResponse(CommonResult.error(e.code, e.message), json_dumps_params={'ensure_ascii': False})"""在代码中使用 get_cached_bert_embeddings 替代 get_bert_embeddings,以减少重复计算。
"""
@lru_cache(maxsize=1000)
def get_cached_bert_embeddings(text):return TransformerUtils.get_bert_embeddings(text)#################################TransformerUtils.py##########################import loggingfrom transformers import BertTokenizer, BertModel
import torch
from torch.nn.functional import cosine_similarityimport osfrom transformers.utils.hub import TRANSFORMERS_CACHEclass TransformerUtils:"""这个函数的主要功能是通过 BERT 模型生成文本的嵌入向量。如果在加载模型或生成嵌入的过程中遇到任何问题,函数会返回一个默认的零向量,确保程序能够继续运行,而不会因为异常而中断。"""@staticmethoddef get_bert_embeddings(texts):# 输出 BERT 模型的默认缓存路径。通常,预训练模型和分词器会从缓存中加载,以减少重复下载的时间。logging.info(f"Default cache path: {TRANSFORMERS_CACHE}")""" 如果输入的 texts 为空或者不是字符串类型,函数会返回一个长度为 768 的零向量。BERT 模型的嵌入向量通常是 768 维的,所以这里返回一个零向量作为默认值。 0.0返回一个长度为 768 的列表,所有元素均为浮点数 0.0,例如:[0.0, 0.0, ..., 0.0] # 共768个元素 """if not texts or not isinstance(texts, str):return [0.0] * 768# 指定模型路径path = "/Users/jiajiamao/soft/python/space/bert-base-chinese"logging.info(f"模型路径指定 path:{path}")try:# 检查路径是否存在if not os.path.exists(path):logging.info(f"模型路径 不存在!")# 这里指定了 BERT 模型的路径,并检查该路径是否存在。如果路径不存在,会抛出一个 FileNotFoundError 异常raise FileNotFoundError(f"Model path {path} does not exist.")"""加载分词器:使用 BertTokenizer.from_pretrained 方法加载分词器。输入:"高性能" 转变成 [高,性,能]分词器的作用是将输入文本转换为模型能够理解的 token 序列。词向量转换(tokens) # 转为数字矩阵"""tokenizer = BertTokenizer.from_pretrained(path)logging.info(f"********************加载分词器:Tokenizer loaded successfully")"""加载模型:使用 BertModel.from_pretrained 方法加载 BERT 模型。加载成功后,model 变量将包含预训练的 BERT 模型。"""model = BertModel.from_pretrained(path)logging.info(f"********************加载模型:BertModel loaded successfully")# 确保加载成功if tokenizer is None:raise ValueError("Tokenizer failed to load.")if model is None:raise ValueError("Model failed to load.")"""# 原理实现步骤:# 1. 添加特殊标记 → [CLS] 我 在 学习 BERT 模型 [SEP]# 2. 分词 → ['降', '噪', '无', '线', '耳', '机', ',', '蓝', '牙', '连', '接', ',', '长', '续', '航']# 3. 转换为ID → [ 101, 7360, 1692, 3187, 5296, 5455, 3322, 8024, 5905, 4280, 6825, 2970,# 8024, 7270, 5330, 5661, 102] 方便输入模型"""inputs = tokenizer(texts, return_tensors='pt', max_length=512, truncation=True, padding=True)logging.info(f"********************tokenizer 分词:{tokenizer.tokenize(texts)}")logging.info(f"********************input:{inputs}")"""with torch.no_grad(): 表示在推理过程中不计算梯度,以提高效率。把分好词的句子变成一系列向量,每个词对应一个向量。每句话里的每个词都会得到一个最终的向量表示模型被调用时它会自动执行自注意力机制的计算。BERT由多个Transformer编码层堆叠而成,每一层都包含一个自注意力模块:# 每个词生成3个向量:Q(查询向量):用来询问其他词和它的关系。K(钥匙向量):用来衡量其他词和它的相关性。V(值向量):用来表示这个词的实际内容。# 计算"高"对每个词的关注度:attention_score = Q_高 ⋅ [K_高, K_性, K_能] # → 得到 [0.8, 0.1, 0.1](更关注自己)用“高”的查询向量(Q_高)去分别与“高”、“性”、“能”的钥匙向量(K_高, K_性, K_能)做点积运算。点积的结果就是注意力分数,比如这里得到 [0.8, 0.1, 0.1]。这表示“高”更关注自己(0.8),而对“性”和“能”的关注度较低。# 加权求和:用注意力分数对“高”、“性”、“能”的值向量(V_高, V_性, V_能)进行加权求和。比如,新的“高”的表示 = 0.8 * V_高 + 0.1 * V_性 + 0.1 * V_能。这个过程的意义在于,通过计算每个词对其他词的关注度,让模型能够更好地理解上下文关系。比如“高”这个词在这里更关注自己,所以它会更多地保留自己的信息,而稍微融入一点“性”和“能”的信息。"""with torch.no_grad():outputs = model(**inputs)"""1.从BERT的输出中提取最后一层的隐藏状态(last_hidden_state)。2.对所有词的向量做平均,得到整个句子的向量表示(mean(dim=1))。3.去掉多余的维度(squeeze())。4.把Tensor转换成NumPy数组(.numpy())。5.最后把数组转换成列表(.tolist())"""embeddings = outputs.last_hidden_state.mean(dim=1).squeeze().numpy().tolist()logging.info(f"********************原内容Text: {texts}")logging.info(f"********************BERT生成一个768维的向量: {embeddings[:10]}") # 只打印前10维,方便检查return embeddingsexcept Exception as e:print(f"Error in get_bert_embeddings: {e}")return [0.0] * 768 # 出现异常时返回默认值"""计算相似度通过分析用户的兴趣(用户向量)和商品的特点(商品向量),计算它们之间的匹配度。然后根据匹配度排序,筛选出最相关的前 5 个商品。最后,只保留那些匹配度足够高(大于阈值)的商品,确保推荐的内容对用户来说是有意义的。@:param product_embeddings 商品向量 @:param user_embeddings 用户向量"""@staticmethoddef similarities(product_embeddings,user_embeddings):#将用户向量转换为张量形式user_embeds_tensor = torch.tensor(user_embeddings, dtype=torch.float32).unsqueeze(0)# 计算相似度similarities = {}for product_name, embedding in product_embeddings.items():#将商品的向量转换为张量形式,并调整其维度以匹配用户向量的计算product_embeds_tensor = torch.tensor(embedding, dtype=torch.float32).unsqueeze(0)#计算用户向量与商品向量之间的余弦相似度,值范围为 [-1, 1],值越接近 1 表示相似度越高。similarity = cosine_similarity(user_embeds_tensor, product_embeds_tensor).item()#将结果存储在一个字典中,键为商品名称,值为相似度值similarities[product_name] = similarityprint(f"Product: {product_name}, Similarity: {similarity}")# 根据相似度排序(从高到低)sorted_products = sorted(similarities.items(), key=lambda item: item[1], reverse=True)print(f"Sorted Products: {sorted_products}")# 设置相似度阈值,并返回相似度最高的前5个商品(设置阈值并筛选商品)threshold = 0.6top_products = {k: v for k, v in sorted_products[:5] if v > threshold}return top_products###############################ResponseCodeEnum###############################from enum import Enum"""返回通用响应类
"""
class ResponseCodeEnum(Enum):###################################公共响应#############################SUCCESS = (200, "操作成功!")PARAMS_ERROR = (400, "参数解析失败,请核对参数!")UNAUTHORIZED = (401, "未认证(签名错误)")FORBIDDEN = (402, "请求错误") # 返回失败业务公共codeMEDIA_TYPE_ERROR = (403, "不支持的媒体异常,请核对contentType!")URL_REQ_NULL = (404, "请求路径不存在")METHOD_ERROR = (405, "不支持当前请求方法,请核对请求方法!")TIMEOUT_EXPIRE_ERROR = (406, "token登录过期!")TOKEN_ILLEGAL = (407, "非法token!")INTERNAL_SERVER_ERROR = (500, "服务器内部错误!") # 系统异常公共code###################################相关业务返回#############################RESOURCES_IP_EXIST = (1001,"资源IP已存在!")"""在枚举值初始化时,将元组中的code和message分别赋值给实例属性self.code和self.message。这样每个枚举值都有独立的code和message属性。"""def __init__(self, code, message):self.code = codeself.message = message"""@property 是 Python 中用于将类的方法转换为属性访问的装饰器。使用 @property 装饰器,你可以像访问属性一样访问方法,而不需要调用它示例:ResponseCodeEnum.SUCCESS.status_code """@propertydef status_code(self):return self.code@propertydef status_message(self):return self.message#####################################CommonResult.py###############################from typing import Any, Optionalfrom icrplat.common.enum.ResponeCodeEnum import ResponseCodeEnumclass CommonResult:""":param res: 类型为 ResponseCodeEnum,用于存储响应状态码和消息:param data: 类型为 Any,用于存储返回的数据:param pagination: 类型为 Optional[dict],是一个可选的参数,用于存储分页信息(默认为 None)"""def __init__(self, res: ResponseCodeEnum, data: Any, pagination: Optional[dict] = None):self.ResponseCodeEnum = ResponseCodeEnumself.data = dataself.pagination = pagination"""这是一个装饰器,用于定义静态方法。静态方法不需要访问类实例(self)或类本身(cls),可以直接通过类名调用。CommonResult.success_pagination"""@staticmethoddef success_pagination(data: Any, pagination: Optional[dict] = None):""":param data: Any: 表示返回的数据,类型为 Any(可以是任意类型)。:param pagination: 表示可选的分页信息,类型为字典(dict),默认值为 None。:return:返回一个字典,包含以下键值对:code: 状态码,取自 ResponseCodeEnum.SUCCESS.status_code。message: 响应消息,取自 ResponseCodeEnum.SUCCESS.message。data: 传入的 data 数据。pagination: 传入的分页信息(如果未传入则为 None)"""return {'code': ResponseCodeEnum.SUCCESS.code,'message': ResponseCodeEnum.SUCCESS.message,'data': data, # 将 QuerySet 序列化为 JSON,'pagination': pagination}@staticmethoddef success_data(data: Any):return {'code': ResponseCodeEnum.SUCCESS.code,'message': ResponseCodeEnum.SUCCESS.message,'data': data, # 将 QuerySet 序列化为 JSON,}@staticmethoddef error(code,message):return {'code': code,'message': message}@staticmethoddef error():return {'code':ResponseCodeEnum.INTERNAL_SERVER_ERROR.code,'message':ResponseCodeEnum.INTERNAL_SERVER_ERROR.message}
###############################BusinessException.py###############################class BusinessException(Exception):def __init__(self,message,code):self.message = messageself.code = codesuper().__init__(message)#####################################Products.py##################################from django.db import models# Create your models here.from django.db import modelsclass Products(models.Model):# 定义 name 字段name = models.CharField(max_length=100)# 定义 description 字段description = models.TextField()class Meta:app_label = 'mongodb'db_table = 'products' #"""自定义 to_dict 实例方法"""def to_dict(self):"""将模型实例转化为字典"""return {'name': self.name,'description': self.description}
五、nacos配置

#换成自己的地址{"mysql": {"DATABASE_NAME": "micro_aics","DATABASE_USER": "xx","DATABASE_PASSWORD": "xx","DATABASE_HOST": "xx","DATABASE_PORT": "8081"},"mongodb": {"DB_NAME": "action_log","DB_HOST": "xx","DB_PORT": "xx","DB_USERNAME": "xx","DB_PASSWORD": "xx","AUTH_DB_SOURCE": "xx"}
}
六、启动项目
#通过 daphne 启动应用
daphne icrplat.asgi:application七、测试





![P10108 [GESP202312 六级] 闯关游戏](https://i-blog.csdnimg.cn/direct/936a9071cc6646a9b2bfc3fcc098eb55.png)




![[Web 安全] PHP 反序列化漏洞 —— PHP 序列化 反序列化](https://i-blog.csdnimg.cn/direct/c16edb714278438a9ab4b4c61d043c7b.jpeg)