1.介绍
在之前的文章中介绍了PyTorch的环境安装,和张量(tensor)的基本使用,为防止陷入枯燥的理论学习中,在这篇文章,我们将进行项目实战学习,项目主要内容: 基于MNIST数据集,实现一个手写数字识别的神经网络模型;
@说明: 通过具体项目实战,我们可以初步了解:使用
PyTorch框架开发一个人工智能应用的基本流程。
1.1 什么是MNIST
MNIST数据集是一个广泛用于机器学习和深度学习领域的图像数据集,MNIST数据集包含了60,000个用于训练的图像和10,000个用于测试的图像,共计70,000张图片。每张图像都是28x28像素的灰度图,其中每个像素的灰度值在0到255之间。每张图像都标有相应的标签,表示图中所描绘的数字是0到9中的一个。
MNIST数据集的目标是使研究者能够快速测试和比较不同的机器学习和深度学习算法,特别是在手写数字识别领域。由于其相对简单的图像和标签,MNIST通常被用作入门级的图像分类问题的基准数据集。许多深度学习框架和教程都使用MNIST作为演示和实践的数据集。
1.2 什么是神经网络
@说明: 神经网络,后面会单独学习,这里只做简单了解。下面是来自维基百科的介绍:
人工神经网络(英语:artificial neural network,ANNs)简称神经网络(neural network,NNs)或类神经网络,在机器学习和认知科学领域,是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统,通俗地讲就是具备学习功能。现代神经网络是一种非线性统计性数据建模工具,神经网络通常是通过一个基于数学统计学类型的学习方法(learning method)得以优化,所以也是数学统计学方法的一种实际应用,通过统计学的标准数学方法我们能够得到大量的可以用函数来表达的局部结构空间,另一方面在人工智能学的人工感知领域,我们通过数学统计学的应用可以来做人工感知方面的决定问题(也就是说通过统计学的方法,人工神经网络能够类似人一样具有简单的决定能力和简单的判断能力),这种方法比起正式的逻辑学推理演算更具有优势。—— 维基百科
2. 流程梳理
基于各类学习资料,梳理出一个快速入门的流程和步骤,具体每个步骤详情如下:
-
数据准备:下载和加载数据集,并对数据进行预处理,包括归一化、平铺(Flatten)、划分为训练集和测试集等。 -
编写模型: 使用 PyTorch的nn.Module类创建自定义模型,在这个步骤中,可自定义神经网络的结构,包括层数、每层的神经元数量、激活函数等。 -
训练模型:迭代训练数据集,将输入传递给模型,计算损失,然后反向传播和更新参数。 -
评估模型: 使用测试集或验证集评估模型性能,计算准确率等指标。 -
保存和加载模型: 保存训练好的模型以备后续使用。
3. 数据准备
3.1 下载数据
在PyTorch 的 torchvision.datasets 模块中提供了,用于加载和下载MNIST 数据集的类(MNIST),我们可以直接使用,类的主要传参如下:
torchvision.datasets.MNIST(
root: str,
train: bool = True,
transform: Optional[Callable] = None,
target_transform: Optional[Callable] = None,
download: bool = False,
)
参数说明:
-
root:数据集存储的根目录,默认是当前工作目录。 -
train:True表示加载训练集,False表示加载测试集。 -
transform:可选参数,用于对数据进行变换的函数或变换列表。 -
target_transform:可选参数,对标签进行变换的函数。 -
download:True表示如果数据集未下载,它将被下载并存储在root指定的目录中;False表示如果数据集未下载,将不会自动下载,而是会尝试使用已存在的数据集。如果不存在,将抛出一个RuntimeError。
3.2 加载数据
PyTorch 不但提供了数据下载工具包,也提供了加载数据的包: torch.utils.data.DataLoader, 通过使用 DataLoader,不但可以对自定义数据集的高效迭代和批处理支持,也可以方便地处理大规模数据集,并将数据传递给神经网络进行训练。
DataLoader参数比较多,这里这列出部分参数含义,更多参数使用可参考官方文档
torch.utils.data.DataLoader(
dataset: Dataset[T_co],
batch_size: Optional[int] = 1,
shuffle: Optional[bool] = None,
num_workers: int = 0,
drop_last: bool = False,
timeout: float = 0,
sampler: Union[Sampler, Iterable, None] = None,
...
)
参数说明:
-
dataset:数据集对象,例如torchvision.datasets.MNIST。 -
batch_size:每个批次的样本数。 -
shuffle:是否在每个 epoch 重新洗牌数据,以确保每个批次包含不同的样本。 -
num_workers:用于数据加载的子进程数量,加速数据加载过程。 -
drop_last:如果数据总数不能被批次大小整除,确定是否舍弃最后一个不完整的批次。 -
timeout:用于定义数据加载器迭代超时的时间限制,默认为 0,表示不超时。 -
sampler:一个用于定义数据加载顺序的采样器。默认情况下,使用SequentialSampler,即按顺序加载数据。你可以传递自定义的采样器。
3.3 完整示例
上面介绍了数据集下载和加载的工具包,结合本篇文章的主题,下面函数演示MNIST数据集的下载和加载使用:
代码文件: app/mnist/mnistData.py
import torchvision
from torch.utils import data
from torch.utils.data import DataLoader
from torchvision import transforms
def dataReady(dataPath: str = "./dataset") -> tuple[DataLoader, DataLoader]:
""" 数据准备 """
# 将图像转换为张量并进行归一化
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]
)
# 下载MNIST训练集
trainDataset = torchvision.datasets.MNIST(
root=dataPath, train=True, download=True, transform=transform
)
# 下载MNIST测试集
testDataset = torchvision.datasets.MNIST(
root=dataPath, train=False, download=True, transform=transform
)
# 加载数据训练集
trainLoader = DataLoader(dataset=trainDataset, batch_size=64, shuffle=True)
# 加载数据测试集
testLoader = DataLoader(dataset=testDataset, batch_size=64, shuffle=True)
return trainLoader, testLoader
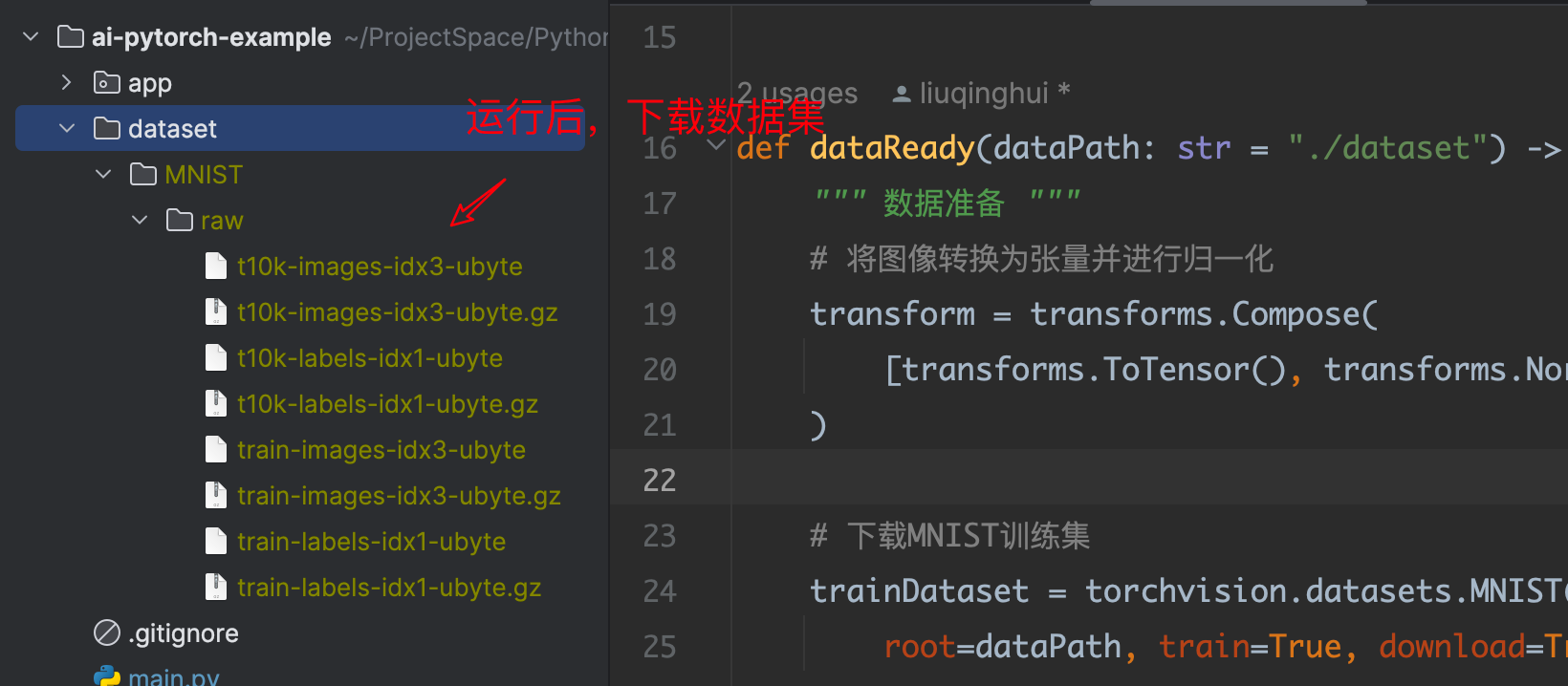
3.4 数据可视化
上面示例运行后,会把数据下载到指定目录,但并没有把图片直观的显示,下面代码是对训练数据集中的部分数据进行可视化展示:
代码文件: app/mnist/mnistData.py
import torch
import torchvision
from matplotlib import pyplot as plt
from torchvision import transforms
def viewTrainDataset(dataPath: str):
"""训练集数据可视化"""
# 定义数据转换
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))]
)
# 下载MNIST训练集
trainDataset = torchvision.datasets.MNIST(
root=dataPath, train=True, download=True, transform=transform
)
figure = plt.figure(figsize=(8, 8))
cmapColor = "gray"
# 定义画布为 5行5列
cols, rows = 5, 5
for i in range(1, cols * rows + 1):
# 随机从训练集中取出图像及其标签
image_index = torch.randint(len(trainDataset), size=(1,))
img, label = trainDataset[image_index.item()]
figure.add_subplot(rows, cols, i)
# 关闭坐标轴的显示
plt.axis("off")
plt.imshow(img.squeeze(), cmapColor)
# 展示图片
plt.show()

4.神经网络模型
4.1 编写模型
代码文件: app/mnist/mnistModel.py
import torch
import torch.nn.functional as F
from torch import nn
num_classes = 10 # 图片的类别数(图片中的数字是0-9)
class DigitDiscernModel(nn.Module):
""" mnist手写数字识别-神经网络"""
def __init__(self):
super().__init__()
# 特征提取网络
self.conv1 = nn.Conv2d(1, 32, kernel_size=3) # 第一层卷积,卷积核大小为3*3
self.pool1 = nn.MaxPool2d(2) # 设置池化层,池化核大小为2*2
self.conv2 = nn.Conv2d(32, 64, kernel_size=3) # 第二层卷积,卷积核大小为3*3
self.pool2 = nn.MaxPool2d(2)
# 分类网络
self.fc1 = nn.Linear(1600, 64)
self.fc2 = nn.Linear(64, num_classes)
# 前向传播
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = torch.flatten(x, start_dim=1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
打印网络模型信息:
代码文件: main.py
import torchinfo
from app import mnist
if __name__ == "__main__":
# 实例化网络模型
model = mnist.DigitDiscernModel()
# 打印网络模型信息
torchinfo.summary(model)
"""
=================================================================
Layer (type:depth-idx) Param #
=================================================================
DigitDiscernModel --
├─Conv2d: 1-1 320
├─MaxPool2d: 1-2 --
├─Conv2d: 1-3 18,496
├─MaxPool2d: 1-4 --
├─Linear: 1-5 102,464
├─Linear: 1-6 650
=================================================================
Total params: 121,930
Trainable params: 121,930
Non-trainable params: 0
=================================================================
"""
4.2 训练模型
代码文件: app/mnist/mnistRun.py
import torch
from torch import nn
from torch.optim import Optimizer
from datetime import datetime
from .mnistData import dataReady
from .mnistModel import DigitDiscernModel
from torch.utils.data import DataLoader
# 判断本地cuda是否可用,不可用则使用cpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def trainModel(trainDataLoader: DataLoader, model: nn.Module, optimizer: Optimizer, loss_fn) -> tuple[float, float]:
"""
训练模型函数
:param trainDataLoader: 训练数据集加载器
:param model: 被训练的网络模型
:param optimizer: 优化器
:param loss_fn: 损失函数
:return: 返回损失率、正确率
"""
# model.train() # 开启训练模式
totalNum = len(trainDataLoader.dataset) # 训练集的大小,一共60000张图片
numBatches = len(trainDataLoader) # 批次数目(60000/64)
trainLoss, trainAccuracy = 0, 0 # 初始化训练损失和正确率
for x, y in trainDataLoader: # 获取图片及其标签
x, y = x.to(device), y.to(device)
# 计算预测误差
pred = model(x) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
# pred.argmax(1): 返回在第一轴上最大值所在的索引
# (pred.argmax(1) == y): 样本的预测是否正确
trainAccuracy += (pred.argmax(1) == y).type(torch.float32).sum().item()
trainLoss += loss.item()
trainAccuracy /= totalNum
trainLoss /= numBatches
return trainLoss, trainAccuracy
def RunTrainMnistModel(dataPath: str, epochs: int):
"""
运行手写数字识别模型训练
:param dataPath: 数据集目录
:param epochs: 训练总次数
:return:
"""
# 运行数据准备
trainDataLoader, testDataLoader = dataReady(dataPath)
# 加载模型
model = DigitDiscernModel()
# ------------------------- 训练模型 ---------------------------------------
# --- 训练加速设置 ---
model = model.to(device)
# 使用PyTorch2.0新特性,对模型进行编译;以提高训练速度
model = torch.compile(model)
# --- 设置超参数 ---
# 损失函数
lossFunc = torch.nn.CrossEntropyLoss()
# 学习率
learn_rate = 0.01
# 优化算法
optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate)
# 开始训练
for epoch in range(epochs):
beginTime = datetime.now()
model.train() # 开启训练模式
# 调用训练函数,返回损失率、正确率
trainLoss, trainAccuracy = trainModel(trainDataLoader, model, optimizer, lossFunc)
# 计算耗时
useTime = datetime.now() - beginTime
print(f"Epoch {epoch + 1}/{epochs}, Loss: {trainLoss:.4f}, Accuracy: {trainAccuracy * 100:.3f}% UseTime: {useTime}")
运行模型训练:
代码文件: main.py
from datetime import datetime
import torchinfo
from app import mnist
if __name__ == "__main__":
# 数据目录
dataPath = "./dataset"
beginTime = datetime.now()
print("------------------------- 开始训练数据 -------------------------")
# 运行数据准备
mnist.RunTrainMnistModel(dataPath, 10)
print("训练总耗时:", datetime.now() - beginTime)
print("------------------------- 训练数据结束 -------------------------")
"""
------------------------- 开始训练数据 -------------------------
Epoch 1/10, Loss: 0.8963, Accuracy: 75.765% UseTime: 0:00:29.220260
Epoch 2/10, Loss: 0.2070, Accuracy: 93.918% UseTime: 0:00:22.031694
Epoch 3/10, Loss: 0.1333, Accuracy: 96.145% UseTime: 0:00:23.531896
Epoch 4/10, Loss: 0.1013, Accuracy: 97.052% UseTime: 0:00:21.245337
Epoch 5/10, Loss: 0.0839, Accuracy: 97.485% UseTime: 0:00:21.997837
Epoch 6/10, Loss: 0.0731, Accuracy: 97.798% UseTime: 0:00:23.366349
Epoch 7/10, Loss: 0.0652, Accuracy: 98.067% UseTime: 0:00:23.617671
Epoch 8/10, Loss: 0.0587, Accuracy: 98.260% UseTime: 0:00:22.976249
Epoch 9/10, Loss: 0.0546, Accuracy: 98.337% UseTime: 0:00:22.871648
Epoch 10/10, Loss: 0.0508, Accuracy: 98.448% UseTime: 0:00:23.636519
训练总耗时: 0:03:54.948401
------------------------- 训练数据结束 -------------------------
"""
4.3 评估模型
代码文件: app/mnist/mnistRun.py
def testModel(model: nn.Module, testDataLoader: DataLoader) -> float:
"""
评估模型
:param model:
:param testDataLoader:
:return:
"""
model.eval()
accuracy = 0
total = 0
with torch.no_grad():
for imgs, labels in testDataLoader:
# 根据输入获取输出
outputs = model(imgs)
# torch.max(outputs.data, 1) : 返回一个元组,包含两个张量。第一个张量是每行中最大元素的值,第二个张量是最大元素的索引。
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
accuracy += (predicted == labels).sum().item()
# 计算准确量占比
accuracyRatio = accuracy / total
return accuracyRatio
运行评估模型:
改造上面函数RunTrainMnistModel,在训练模型后,调用评估模型函数,用来验证模型的准确度。
def RunTrainMnistModel(dataPath: str, epochs: int):
"""
运行手写数字识别模型训练
:param dataPath: 数据集目录
:param epochs: 训练总次数
:return:
"""
...
# 开始训练
for epoch in range(epochs):
...
# 这里加上--评估模型
testAccuracy = testModel(model, testDataLoader)
print(f"评估模型运行结果,准确率: {testAccuracy * 100:.3f}%")
"""
------------------------- 开始训练数据 -------------------------
Epoch 1/5, Loss: 0.9592, Accuracy: 73.862% UseTime: 0:00:31.245215
Epoch 2/5, Loss: 0.1988, Accuracy: 94.225% UseTime: 0:00:25.062082
Epoch 3/5, Loss: 0.1289, Accuracy: 96.205% UseTime: 0:00:25.547806
Epoch 4/5, Loss: 0.0987, Accuracy: 97.033% UseTime: 0:00:23.455382
Epoch 5/5, Loss: 0.0825, Accuracy: 97.530% UseTime: 0:00:24.252379
评估模型运行结果,准确率: 97.740%
训练总耗时: 0:02:12.983897
------------------------- 训练数据结束 -------------------------
"""
4.4 保存模型
在 PyTorch 中,通过使用 torch.save() 函数,保存训练后的模型;
torch.save(model.state_dict(), "./models/mnist_model.pth")
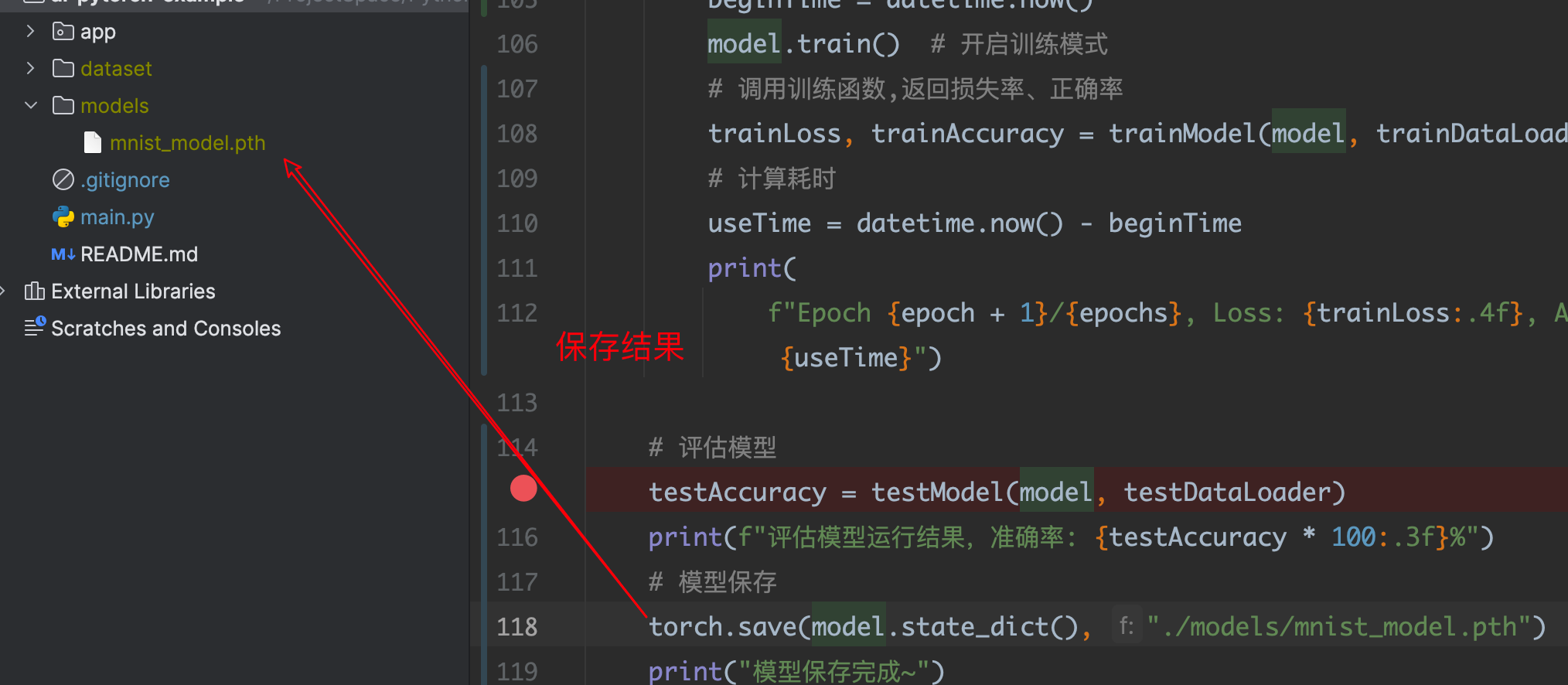
4.5 加载使用模型
代码文件: app/mnist/mnistRun.py
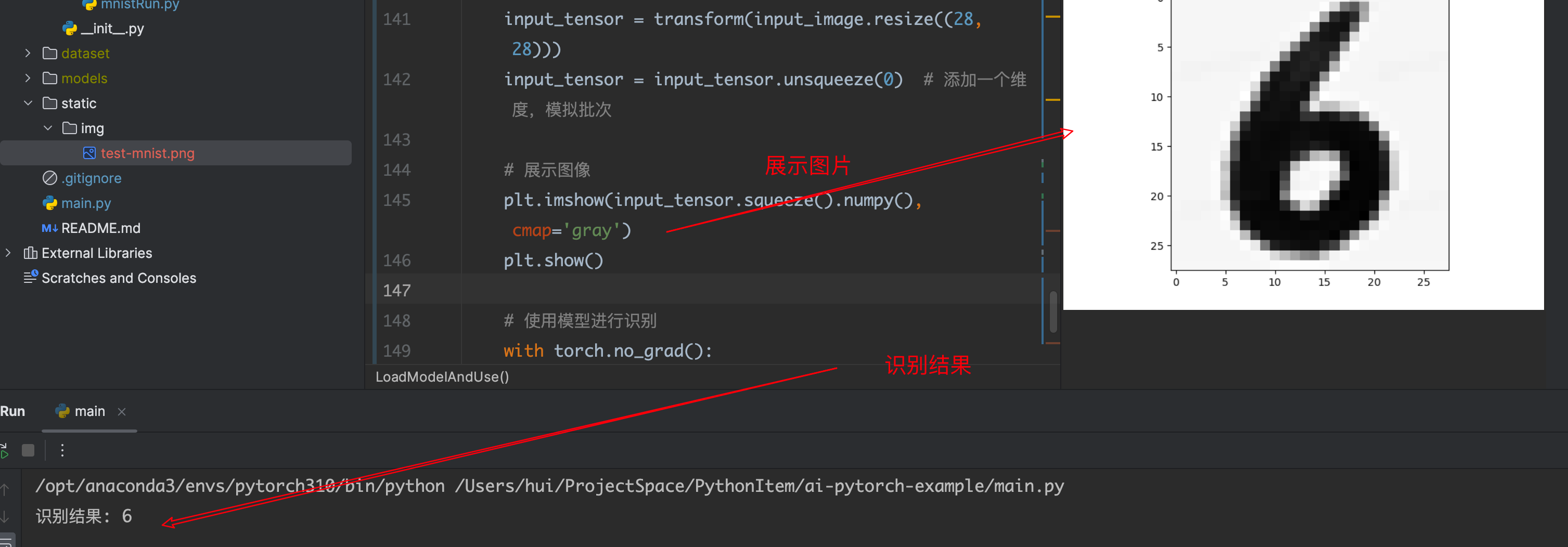
def LoadModelAndUse(imgPath: str):
""" 加载已保存的模型,并验证使用 """
# 创建一个新的模型实例
model = DigitDiscernModel()
# 加载模型
model.load_state_dict(torch.load("./models/mnist_model.pth"))
# 定义图像预处理操作
transform = transforms.Compose([
transforms.Grayscale(), # 转为灰度图
transforms.ToTensor(), # 转为张量
transforms.Normalize((0.5,), (0.5,)) # 归一化
])
input_image = Image.open(imgPath)
input_tensor = transform(input_image.resize((28, 28)))
input_tensor = input_tensor.unsqueeze(0) # 添加一个维度,模拟批次
# 展示图像
plt.imshow(input_tensor.squeeze().numpy(), cmap='gray')
plt.show()
# 使用模型进行识别
with torch.no_grad():
outputs = model(input_tensor)
# 获取模型的预测结果
_, result = torch.max(outputs, 1)
print(f"识别结果: {result.item()}")
运行测试:
from app import mnist
if __name__ == "__main__":
mnist.LoadModelAndUse("./static/img/test-mnist.png")
本文由 mdnice 多平台发布





![[Vue3] useRoute、useRouter](https://img-blog.csdnimg.cn/direct/7df1ed7e6b9c4818a27d60e5f09e4a97.png)
![[嵌入式系统-7]:龙芯1B 开发学习套件 -4- LoongIDE 集成开发工具的使用-创建应用程序工程、编译、下载、调试](https://img-blog.csdnimg.cn/direct/d0b1f2488ef848809938af3c2cb4b36a.png)