这篇文章主要放源代码,思路不会介绍特别清楚,详细思路可以看评论区的b站讲解视频。
1.场景需求
获取微博肖战超话内容部分用户的帖子数据,日期范围限定在近2个月,要求获得帖子的发布时间、帖子文本内容、转发数据、评论数据和点赞数据(不包括评论的内容和点赞的人)。
2.网站调研
通过调查发现,微博有2个入口,第一种如下:
第二种如下:
 这2种入口爬取方式不同,我因为不熟悉微博,所以也是把两个入口的方式都试了一遍。。。所以这里有个经验要分享一下:爬虫的最终目的是获取需要的数据,不管用什么方式,从网站哪个入口开始,都应该要实现高效率的获得所有数据。因此在爬虫之前,应该花时间了解目标网站的数据存储方式,切忌一上来就找个网址开始胡乱一通爬,得动脑子思考、观察再决定爬取方案。尤其是规模大的项目,方案没选好后面会出现爬取速度很慢、内存不够用、爬一半发现方案行不通等问题。
这2种入口爬取方式不同,我因为不熟悉微博,所以也是把两个入口的方式都试了一遍。。。所以这里有个经验要分享一下:爬虫的最终目的是获取需要的数据,不管用什么方式,从网站哪个入口开始,都应该要实现高效率的获得所有数据。因此在爬虫之前,应该花时间了解目标网站的数据存储方式,切忌一上来就找个网址开始胡乱一通爬,得动脑子思考、观察再决定爬取方案。尤其是规模大的项目,方案没选好后面会出现爬取速度很慢、内存不够用、爬一半发现方案行不通等问题。
3.解决方案
这里写文章主要就放源代码,思路不会介绍的特别清楚,详细思路可以看评论区的b站讲解视频。
3.1 入口选择
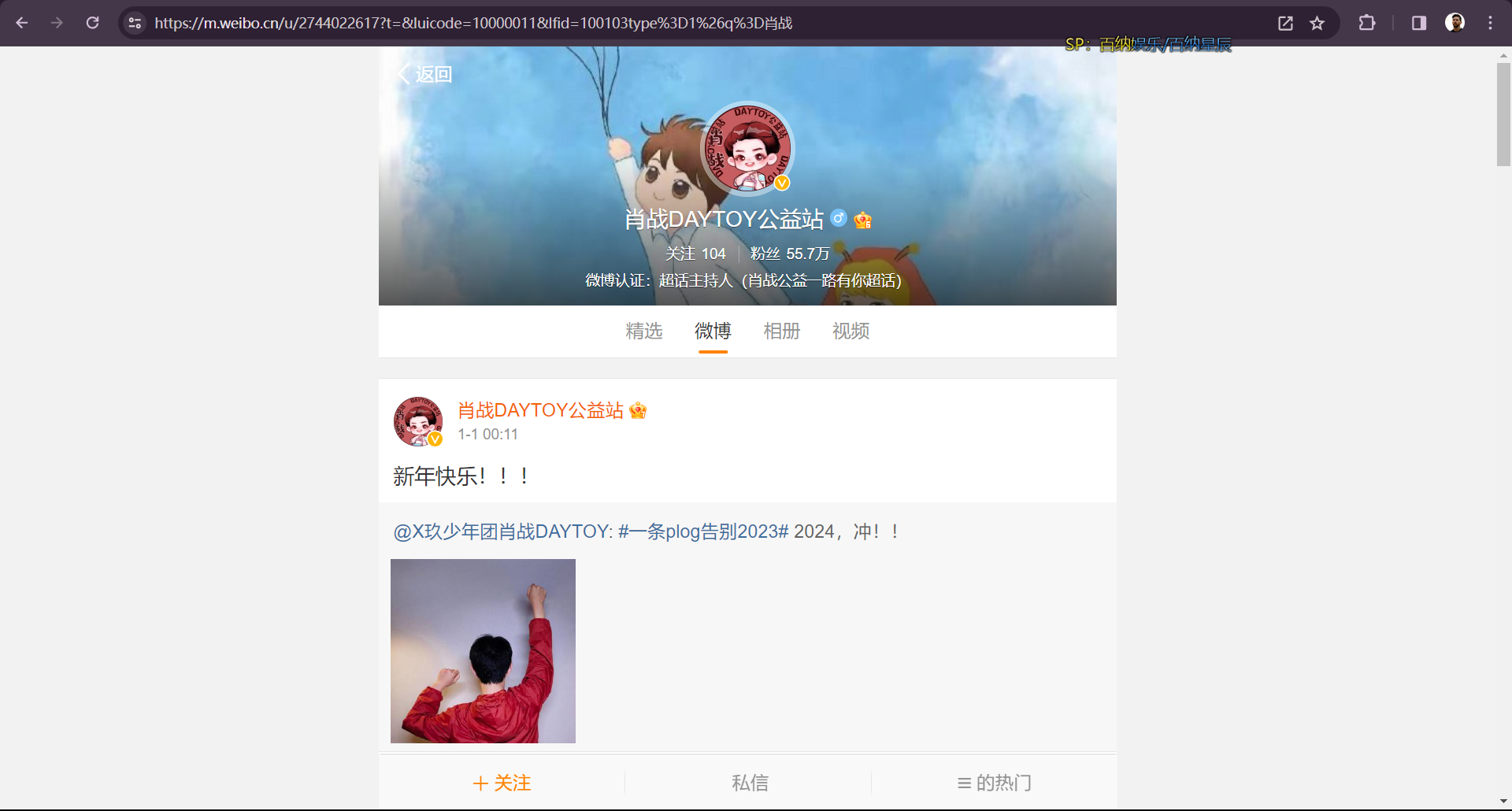
通过不断尝试,最后发现一个兼具通用性和速度的方法。首先选择如下入口,通过微博自带的微博lite,点击在浏览器打开:


这个入口的优点是不需要登录就可以获取全部上述信息,因此也就省去了模拟登录的麻烦。接下来搜索对应用户的ID,便可以进入其主页:
3.2 实现方法
可以发现每个用户所有发布的帖子都在上面的个人主页中,因此需要不断向下滑动以获取更多的数据。这种特点比较适合用selenium,通过模拟浏览器的滑动操作加时间判断便可以较为精准的得到指定时间内的帖子。那么下面就是源代码,一个函数,很简洁:
def getTieziContent(user_url, file_path, start_num=0, browser='chrome', step=1, roll_height=2500):"""输入用户主页url,直接获取帖子的文本和相关数据注意:这个方法不点开帖子,速度更快:param start_num: 崩溃后从哪个帖子数开始爬:param user_url: 用户主页url:param browser: 用什么浏览器爬:param step: 爬取帖子数的步长,0为全部爬取:param roll_height: 滚动多少页面:param file_path: 存储用户所有帖子的url文件路径(人名即可):return: 写入文件"""# 先用浏览器打开用户主页if browser == 'chrome':path = "C:\Program Files\Google\Chrome\Application\chromedriver.exe"ops = chrom_opt()service_path = Service(executable_path=path)# ops.add_argument("--headless")ops.add_argument('--blink-settings=imagesEnabled=false')ops.add_argument('--disable-plugins')ops.add_argument("--disable--gpu")ops.add_argument("--disable-images")ops.add_argument('--disk-cache-size=2000000000') # 设置大容量内存driver = webdriver.Chrome(ops, service_path)driver.set_window_size(480, 1080) # 设置窗口大小driver.set_window_position(800, 0) # 设置窗口x, y位置driver.get(user_url)time.sleep(1) # 1秒等待加载else:path = "C:\Program Files\Mozilla Firefox\geckodriver.exe" # 浏览器驱动器service_path = Service(executable_path=path)binary_path = (r'C:\Program Files\Mozilla Firefox\firefox.exe') # binary_path就是你的浏览器路径ops = Options()ops.binary_location = binary_path# ops.add_argument("--headless")ops.add_argument('--blink-settings=imagesEnabled=false')ops.add_argument('--disable-plugins')ops.add_argument("--disable--gpu")ops.add_argument("--disable-images")ops.add_argument('--disk-cache-size=2000000000') # 设置大容量内存driver = webdriver.Firefox(ops, service_path)driver.set_window_size(480, 1080) # 设置窗口大小driver.set_window_position(900, 0) # 设置窗口x, y位置driver.get(user_url)time.sleep(1) # 1秒等待加载# 先获取关注数和粉丝数name = driver.find_element(By.XPATH, '/html/body/div/div[1]/div[1]/div[1]/div/div[4]/div[1]').textguanzhu_fans = driver.find_element(By.XPATH, '/html/body/div/div[1]/div[1]/div[1]/div/div[4]/div[2]').find_elements(By.CLASS_NAME, 'txt-shadow')guanzhu, fans = [i.text for i in guanzhu_fans]print(name, guanzhu, fans)# 下滑2000,帖子数正常人就可以到达2023年的帖子start_time = time.time() # 开始时间for i in range(1, roll_height):driver.execute_script(f'document.documentElement.scrollTop={i * 100}')time.sleep(2) # 停两秒看看翻到多少driver.execute_script("var q=document.documentElement.scrollTop=0")divs = driver.find_elements(By.CLASS_NAME, 'card-main') # 所有帖子所在h4s = driver.find_elements(By.TAG_NAME, 'h4') # 判断发帖时间,可以翻到2023的说明帖子数量不是很多length = len(divs)print(length)# 最后打开文件,写入用户主页出现的所有帖子的urlfor h4 in h4s[-7:]:post_time = h4.get_attribute("class")flag1 = h4.text.startswith("2023-11")flag2 = h4.text.startswith("2023-10")flag3 = h4.text.startswith("2023-9")flag4 = h4.text.startswith("2023-8")flag5 = h4.text.startswith("2023-7")flag6 = h4.text.startswith("2023-6")flag7 = h4.text.startswith("2023-5")flag8 = h4.text.startswith("2023-12")flag9 = h4.text.startswith("2023-4")flag10 = h4.text.startswith("2023-3")flag11 = h4.text.startswith("2023-1")flag12 = h4.text.startswith("2022")flag13 = h4.text.startswith("2021")flag14 = h4.text.startswith("2020")flag15 = h4.text.startswith("2019")flag16 = h4.text.startswith("2018")flag17 = h4.text.startswith("2017")flag18 = h4.text.startswith("2016")flag19 = h4.text.startswith("2015")flag20 = h4.text.startswith("2014")flag21 = h4.text.startswith("2013")if post_time == 'm-text-cut' and (flag1 or flag2 or flag3 or flag4 or flag5 or flag6 or flag7 orflag8 or flag9 or flag10 or flag11 or flag12 or flag13 or flag14 orflag15 or flag16 or flag17 or flag18 or flag19 or flag20 or flag21):with open(f"肖战3类粉丝数据/10个来自评论区/{file_path}-用户信息.csv", 'a', encoding='utf_8_sig',newline="") as f:writer = csv.writer(f)writer.writerow([name, guanzhu, fans])with open(f"肖战3类粉丝数据/10个来自评论区/{file_path}-用户信息.csv", 'a', encoding="utf_8_sig",newline="") as f:writer = csv.writer(f)for i in range(start_num, length, step):if i % 100 == 0:print(f"爬完{i}个")# if i == 1500:# breaktry:tiezis = driver.find_elements(By.CLASS_NAME, 'card-main') # 重新定位,因为dom树刷新了name = tiezis[i].find_element(By.TAG_NAME, 'h3').text # 发布人idpost_time = tiezis[i].find_element(By.TAG_NAME, 'header').find_element(By.CLASS_NAME, 'time').text # 发布时间text = tiezis[i].find_element(By.CLASS_NAME, 'weibo-og').text # 发布内容repost = tiezis[i].find_element(By.TAG_NAME, 'footer').find_elements(By.TAG_NAME, 'h4')[0].text # 转发数comment = tiezis[i].find_element(By.TAG_NAME, 'footer').find_elements(By.TAG_NAME, 'h4')[1].text # 评论数attitude = tiezis[i].find_element(By.TAG_NAME, 'footer').find_elements(By.TAG_NAME, 'h4')[2].text # 评论数writer.writerow([name, post_time, text, repost, comment, attitude])except Exception as e:continuedriver.close()breakelse:continueif __name__ == '__main__':# 清空一下进程os.system('taskkill /F /iM chromedriver.exe')os.system('taskkill /F /iM firefox.exe')s = time.time()with open("肖战3类粉丝数据/补充.csv", 'r', encoding='utf8') as f:data = list(csv.reader(f))for i in range(47, len(data)):print(f"=====================第{i + 1}个用户======================")url = data[i][1]name = data[i][0]getTieziContent(url, name, roll_height=8000)e = time.time()print(f"{((e - s) // 60) // 60}h{((e - s) // 60) % 60}min")