EXPLAIN 可用来查看SQL执行计划,常用来分析调试SQL语句,来使SQL语句达到更好的性能。
1 前置知识
在学习EXPLAIN 之前,有些基础知识需要清楚。
1.1 JSON类型
MySQL 5.7及以上版本支持JSON数据类型。可以将数组存为JSON格式的字符串,并使用JSON函数来提取元素。
-- 定义JSON数据类型变量
SET @json_str = '{"name":"黄先生","age": 28, "address": {"city": "深圳"}}';1.1.1 JSON_VALUE 与 JSON_EXTRACT
JSON_VALUE: 返回json类型的键值。(返回字符串)
JSON_EXTRACT: 返回的是JSON某路径下的值。(返回JSON类型)
路径是一种字符串,类似于文件路径,用于指定JSON对象的特定位置,由一些列的键和路径组成,用于定位JSON对象中的值。
键,是JSON 用于定义对象的属性,每个键对应一个值。
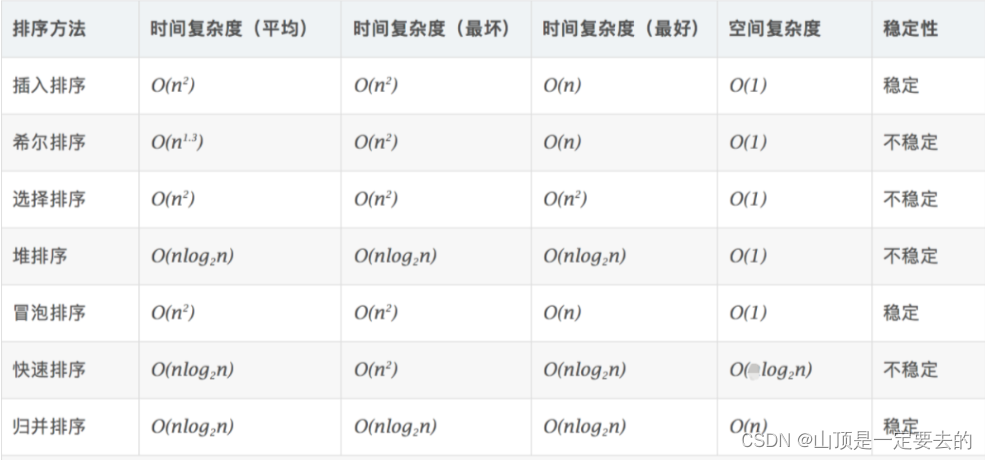
| 路径支持 | JSON_EXTRACT 允许使用JSON路径来提取值 JSON_VALUE 只能提取具有指定键的值。 |
| 错误处理 | JSON_EXTRACT 如果指定路径不存在,则返回NULL JSON_VALUE 如果键不存在,则返回NULL或报错(取决于是否启用了non_strict模式)。 |
| 用途 | JSON_EXTRACT 通常用于更复杂的JSON结构。 |
| 性能 | 某些情况下,因为JSON_VALUE更简单,可能比JSON_EXTRACT更快。 |
图 JSON_VALUE 与 JSON_EXTRACT的区别
-- 数据库版本 8.0.29
DROP TABLE IF EXISTS e_student_course_grade;
DROP TABLE IF EXISTS e_course;
DROP TABLE IF EXISTS e_student;
DROP TABLE IF EXISTS e_class;
DROP TABLE IF EXISTS e_teacher;CREATE TABLE e_teacher(id INT NOT NULL AUTO_INCREMENT COMMENT '教师id',`name` VARCHAR(20) NOT NULL,`age` VARCHAR(20) NOT NULL,PRIMARY KEY(id)
) COMMENT '教师';CREATE TABLE e_class(id INT NOT NULL AUTO_INCREMENT COMMENT '班级号',`name` VARCHAR(20) NOT NULL,teacher_id INT NOT NULL COMMENT '班主任id',PRIMARY KEY(id),FOREIGN KEY(teacher_id) REFERENCES e_teacher(id) ON DELETE CASCADE
) COMMENT '班级';CREATE TABLE e_student(id INT NOT NULL AUTO_INCREMENT COMMENT '学号',`name` VARCHAR(20) NOT NULL,`age` VARCHAR(20) NOT NULL,class_id INT NOT NULL COMMENT '班级id',PRIMARY KEY(id),FOREIGN KEY(class_id) REFERENCES e_class(id) ON DELETE CASCADE
) COMMENT '学生';CREATE TABLE e_course(id INT NOT NULL AUTO_INCREMENT COMMENT '学科号',`name` VARCHAR(20) NOT NULL,teacher_id INT NOT NULL COMMENT '教师id',PRIMARY KEY(id),FOREIGN KEY(teacher_id) REFERENCES e_teacher(id) ON DELETE CASCADE
) COMMENT '学科';CREATE TABLE e_student_course_grade(student_id INT NOT NULL COMMENT '学生id',course_id INT NOT NULL COMMENT '课程id',grade DOUBLE NOT NULL COMMENT '成绩',PRIMARY KEY(student_id,course_id),FOREIGN KEY(student_id) REFERENCES e_student(id) ON DELETE CASCADE,FOREIGN KEY(course_id) REFERENCES e_course(id) ON DELETE CASCADE
) COMMENT '学生课程成绩';-- 数据插入函数
DROP PROCEDURE IF EXISTS eDataInsert;
CREATE PROCEDURE eDataInsert(IN json_data JSON, IN sql_str TEXT)
BEGINDECLARE pos INT DEFAULT 0;SET @json_count := JSON_LENGTH(json_data);fetch_loop: LOOPIF pos >= @json_count THENLEAVE fetch_loop; END IF; SET @json := JSON_EXTRACT(json_data,CONCAT("$[",pos,"]"));SET @query = sql_str; PREPARE stmt FROM @query; EXECUTE stmt; DEALLOCATE PREPARE stmt; SET pos := pos + 1;END LOOP fetch_loop;
END;-- 教师数据
SET @teacher_json_data := '[{"name": "刘老师","age": 29},{"name": "黄老师","age": 28},{"name": "陈老师","age": 29},{"name": "李老师","age": 32},{"name": "张老师","age": 25}]';
SET @teacher_sql_str = 'INSERT INTO e_teacher(`name`,age) VALUES(JSON_VALUE(@json,"$.name"),JSON_VALUE(@json,"$.age"))';
CALL eDataInsert(@teacher_json_data,@teacher_sql_str);
-- 班级数据
SET @class_json_data := '[{"name": "实验班","teacherName": "刘老师"},{"name": "平衡班","teacherName": "黄老师"},{"name": "基础班","teacherName": "陈老师"}]';
SET @class_sql_text = 'INSERT INTO e_class(`name`,teacher_id) VALUES(JSON_VALUE(@json,"$.name"), (SELECT id FROM e_teacher WHERE `name` = JSON_VALUE(@json,"$.teacherName") LIMIT 0,1));';
CALL eDataInsert(@class_json_data,@class_sql_text);
-- 学生数据
SET @student_json_data := '[{"name": "黄兮言","className":"实验班","age":10},{"name": "胡沛煊","className":"实验班","age":10},{"name": "李正国","className":"平衡班","age":11},{"name": "陈青青","className":"基础班","age":10},{"name": "刘丽丽","className":"平衡班","age":11},{"name": "张小五","className":"平衡班","age": 10},{"name":"孙小","className":"基础班","age":10},{"name":"周欣欣","className":"实验班","age":11},{"name":"吴郑立","className":"平衡班","age":11},{"name": "李亚楠","className":"基础班","age":11},{"name": "邓贤","className":"基础班","age":10},{"name": "谢正华","className":"平衡班","age":10}]';
SET @student_sql_text := 'INSERT INTO e_student(`name`,age,class_id) VALUES(JSON_VALUE(@json,"$.name"),JSON_VALUE(@json,"$.age"),(SELECT id FROM e_class WHERE `name` = JSON_VALUE(@json,"$.className") LIMIT 0,1));';
CALL eDataInsert(@student_json_data, @student_sql_text);
-- 学科数据
SET @course_json_data := '[{"name":"英语","teacherName":"刘老师"},{"name":"数学","teacherName":"黄老师"},{"name":"语文","teacherName":"陈老师"},{"name":"物理","teacherName":"李老师"},{"name":"化学","teacherName":"张老师"}]';
SET @course_sql_text := 'INSERT INTO e_course(`name`,teacher_id) VALUES(JSON_VALUE(@json,"$.name"),(SELECT id FROM e_teacher WHERE `name` = JSON_VALUE(@json,"$.teacherName") LIMIT 0,1));';
CALL eDataInsert(@course_json_data, @course_sql_text);
-- 学科成绩数据
INSERT INTO e_student_course_grade ( student_id, course_id, grade ) SELECT
studentId,
courseId,
(CASEclassName WHEN '实验班' THENROUND( 80 + RAND() * 20, 0 ) WHEN '平衡班' THENROUND( 60 + RAND() * 20, 0 ) ELSE ROUND( 10 + RAND() * 20, 0 ) END ) FROM(SELECTs.id AS studentId,co.id AS courseId,cl.`name` AS className FROMe_student sJOIN e_course coLEFT JOIN e_class cl ON s.class_id = cl.id ) temp;1.2 连接查询原理
SELECT e.`name` AS courseName, t.`name` AS teacherName
FROM `e_course` e
LEFT JOIN e_teacher t ON e.teacher_id = t.id
WHERE e.`name` != '化学';上面是简单的左连接查询,其中LEFT JOIN 左边的表是驱动表(e_course表),而右边的表是从表(e_teacher)。
上面语句的查询步骤是:1)从驱动表中找到符合where条件的数据;2)对步骤1的数据遍历从表,根据on条件找到匹配的数据,然后放到结果池。3)重复步骤1及步骤2,直到遍历完整张驱动表。伪代码如下:
for (int i = 0; i < 驱动表.length; i++) {let item = 驱动表[i];if (item 符合 where 条件) {for (int j = 0; j < 从表.length; j++) {let it = 从表[j];if (it 符合 on 条件) {将item及it 放到结果池;}}}
}由上面伪代码可知,在连接查询的时候,会对驱动表每个符合的数据都遍历一遍从表。两张表相当于双层循环,三张表相当于三层循环。联表越多时间复杂度呈指数级别增长,联表的性能开销会非常大。在设计上,尽量选择驱动表为小表,用小表驱动大表。
1.2.1 连接查询优化方式
优化连接查询可以从两方面出发:1)减少访问从表的次数;2)加快查询从表。MySQL提供了三种方案:
1)BNL算法,Block Nested Loop 块嵌套循环,适用于从表无法使用索引的场景,通过减少访问从表的次数来进行优化。
使用一块缓存池(join buffer)记录满足驱动表的记录,将缓存池装满后再去从表中遍历查询。
注意join buffer 存储需要查询的列和查询条件的列,因此不要使用select * ,避免浪费join buffer的空间。
2)BKA算法,Block Key Access,适用于从表能使用索引的场景。驱动表中满足条件的记录,其id不一定有序,使用乱序的id去从表查找可能发生随机IO。
BKA 算法是基于MRR的,对驱动表结果的id进行排序后,再去从表中查找。
3)hash join 哈希连接。MySQL 8.0 默认使用hash的join buffer,通过空间换时间的方式来加速查找被驱动表。
分为构建阶段和探测阶段:
- 构建阶段(build过程):选择较小的表作为驱动表,并将其加载到内存中的哈希表中,哈希表通过使用连接条件中的列作为键,将驱动表中的记录映射到不同的桶中。
- 探测阶段(probe过程):遍历从表记录,对于每个别驱动的记录,算法使用连接条件中的列作为键,再哈希表中查找匹配的捅,如果找到了,就会将记录连接在一起并返回结果。
2 EXPLAIN 命令
MySQL的EXPLAIN命令能帮助你识别查询中的瓶颈,并据此优化查询或数据库的结构。
执行在SQL查询语句前面加上 EXPLAIN关键字,即可查询该语句的执行计划。
| id | 执行语句的唯一标识。如果结果包含多个id值,则数字越大越先执行,对于相同id的行,则从上往下依次执行。为NULL表示结果集,不需要使用它来进行查询。 |
| select_type | 查询类型。 |
| table | 表名,表示当前正在访问哪张表,如果定义了别名,则显示别名。 |
| partitions | 匹配的分区。 |
| type | 连接类型。 |
| possible_keys | 可能使用的索引。展示的是当前查询(在优化前)可能使用哪些索引,这列数据是早期创建的,因此有些索引可能对于后续的优化过程没用。 |
| key | 实际使用的索引。 |
| key_len | 索引长度。 |
| ref | 索引的哪一列被引用了。 |
| rows | 估计要扫描的行,数值越小越好。 |
| filtered | 符合查询条件的数据百分比。 |
| extra | 附加信息。 |
表 EXPLAIN 命令结果的相关字段
2.1 select_type 查询类型
| SIMPLE | 简单查询,未使用UNION或子查询。 |
| PRIMARY | 最外层的查询,如果包含子查询,最外层的SELECT被标记未PRIMARY。 |
| UNION | 在UNION中的第二个及随后的SELECT被标记为UNION。如果UNION被FROM子句的子查询包含,那么它的第一个SELECT会被标记为DERIVED。 |
| DEPENDENT UNION | DEPENDENT UNION 中的第二个及随后的SELECT被标记为DEPENDENT UNION。 |
| UNION RESULT | UNION的结果。 |
| SUBQUERY | 子查询中的第一个SELECT。 |
| DEPENDENT SUBQUERY | 子查询中的第一个SELECT,并依赖了外面的查询。 |
| DERIVED | 包含在FROM子句的子查询中的SELECT。 |
| DEPENDENT DERIVED | 包含在FROM子句的子查询中的SELECT,并依赖了外面的查询。 |
| MATERIALIZED | 物化子查询。 |
| UNCACHEABLE SUBQUERY | 无法缓存结果的子查询。 |
| UNCACHEABLE UNION | 无法缓存的UNION查询。 |
表 EXPLAIN命令的select_type 的查询类型含义
2.1.1 MATERIALIZED 物化子查询
物化子查询(MATERIALIZED Subquery)是一种特殊的子查询,它在查询过程中将子查询的结果先计算处理,并存储在一个临时表中,然后再对临时表进行进一步查询操作。
内部临时表:MySQL借助临时表处理中间的结果,此时使用的临时表称为内部临时表,对用户不可见也不能直接操作。 create temporary table 创建外部临时表,仅对当前会话可见,会话退出后会自动删除临时表。
派生表:是FROM子句的子查询的结果集。优化器对派生表的有两种优化策略:1)合并到外层查询;2)物化,这个过程产生了物化表。
物化表:物化是指将子查询的结果集保存到临时表的过程。该表称为物化表。
2.2 type 连接类型
| system | 该表只有一行(相当于系统表),system是const类型的特例。 |
| const | 针对主键或唯一索引等值查询,最多只返回一行数据。 |
| eq_ref | 使用索引的全部组成部分,并且索引是PRIMARY KEY 或 UNIQUE NOT NULL。 |
| ref | 满足索引最左前缀规则,并且索引不是主键也不是唯一索引。 |
| fulltext | 全文索引。 |
| ref_or_null | 类似于ref,但会额外搜索那些包含了NULL的空行。 |
| index_merge | 使用了索引合并优化,表示一个查询用到了多个索引。 |
| unique_subquery | 与eq_ref类似,但是使用了IN查询,并且子查询是主键或唯一索引。 |
| index_subquery | 与uinque_subquery类似,只是子查询使用的是非唯一索引。 |
| range | 范围扫描,检索指定范围的行,主要用于有限制的索引扫描。 |
| index | 全索引扫描。 |
| ALL | 全表扫描。 |
表 连接类型,性能由好到坏排序
2.3 key_len 计算索引长度
了解key_len的计算方式对于优化查询和索引非常重要。
不同的存储引擎及字符集可能会对其值产生影响。对于复合索引,key_len 是复合索引每一列的索引长度。如果指定了索引前缀长度,例如:INDEX(column(10)),那么key_len 只会考虑这10个字符。
不同的字段类型,索引长度的计算方式也不同:
- 固定长度的字段,例如INT是4个字节。char(10) 表示10个字符。Date,TIMESTAMP 是3个字节。
- 可变长度的字段。VARCHAR(100)最大是100个字符长度。实际使用的长度取决于存储的值的长度。但是,在索引中,VARCHAR的长度可能有一个最大前缀限制,例如前N个字符。而key_len 表示索引中使用的字节的最大长度。
注意,VARCHAR和char括号内的数字表示的是最大的字符串长度,不是字节。如果字段类型允许为null,则计算索引长度时还需要+1(NULL);如果是可变长度的字段,计算时还需要+2(变长长度)。
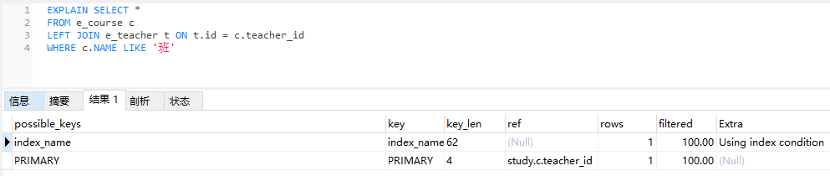
图 explain实战,演示key_len的值

图 e_course 表结构及索引字段
utf8_bin 字符集下varchar 类型需要3个字节。所以索引index_name的 ken_ken = 20 * 3 + 2(变长长度)。而teacher_id 是int类型,字节长度为4。