本文为 「茶桁的 AI 秘籍 - BI 篇 第 09 篇」

文章目录
- EDA 作用
- 可视化视图
- Python 进行可视化
- subplot
Hi,你好。我是茶桁。
今天想给大家讲的是关于数据的可视化。在工作中很多时候我们不光要计算结果,还要把结果呈现出来,最好是一种图形化的方式。因为这样领导会更容易去理解。
此外在工作中我们也希望自己对数据更有感觉,因为数据量有的时候会非常大,对于几十万上百万的数据的不可能一行一行看,所以可视化就是一个非常重要的工具。
首先一起来思考一下可视化都有哪些视图。这些视图我们把它归成四大类,每一大类里面都有一些可以选择的图表样式。在 Python 要做可视化离不开两个工具箱,一个工具箱是 Matplotlib, 一个是 Seaborn。
这里做一个调查,读者中的小伙伴们有没有使用过这类工具?大家可以在下面留给我,看一看大家之前有没有做过。如果你用 Python 做过可视化基本上都会用这两个工具。
我相信大部同学应该还是有一些了解的,没用过的到时候看一下我课件上的一些代码,这个代码直接运行的话是可以运行出来,在运行之前你需要安装这两个工具。
如果你的图表比较复杂,一张图上面要把它分成几个象限,那么你们会使用到一个工具叫 subpolot,就是子图的意思,所以它是专门去画一些小的图形。
后面几天咱们还会去做一些可视化的样式是跟词云相关,这次带来一个项目,看一看怎么样用词云展示去呈现出来那些关键词。
还有可以对树来做可视化。决策树本身是一种机器学习的模型,这个模型你脑海中可以想一想,它会分成两个叉,每个叉都有一个判断的标准。那这棵树也可以给它用可视化的工具来呈现出来。
最后我们还是会有一个项目,这个项目是在阿里云的天池上的一场比赛。我们主要的任务就是用这样的一个数据集来看一看怎么样去用可视化的方式方便你去了解它们。
接着,咱们会继续来看 Python 的可视化。Python 的可视化如果你要封装成一个产品,这个产品指的是发布的产品,可以由用户来使用,那么你会使用到 Flask 这个工具。
Python 在做这个搭建所有框架里面除了 Flask 还有一个叫做 Django 的。我推荐大家使用 Flask,因为它更加轻量级。如果你不写 Python 代码,想要更方便的直接通过拖拽的方式来完成可视化的话,我们会使用到一些 PowerBI,类似于这样的一些软件的 BI 报表,还有我一直以来比较推崇的 Tableau。
所以在之后的课程中我们看一看一个完整型的数据产品是如何搭建出来的。这里也给大家一个例子,就是我之前做过的一个例子,通过 Flask 加 echarts 可以搭建一个肺炎疫情的可视化的 Dashboard。
不可能一口吃成一个胖子,咱们一步一步慢慢来。首先我们一起来思考一下,可视化的 EDA 都有哪些作用?我们先来看看什么是 EDA,EDA 这个名词大家可能在网上会看过,我们在做数据处理的过程中第一项就是要做一个 explore data analysis,叫做探索性的数据分析。所以探索性的数据分析可以通过可视化的方式帮我们来做呈现。
EDA 作用
那我们来思考一下,可视化都有哪些方式?它可以说贯穿到我们整个数据分析的始终。
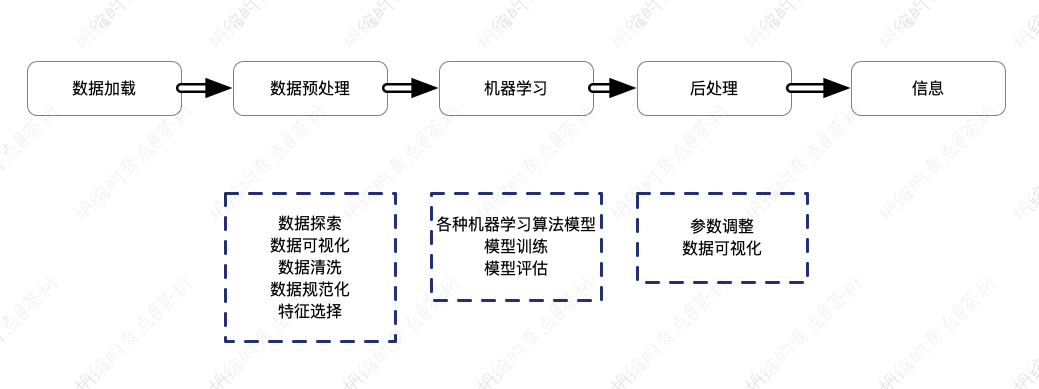
在数据加载之后的预处理环节中要做一些探索,这个探索可以用可视化的图形来做。机器学习的过程中有没有必要去做可视化呢?如果你要预测一个模型,训练一个模型需要花一天的时间,那这一天 20 多个小时时间之内你要了解机器目前运行的程度是怎样的。所以你可以把一张 loss 的曲线图给它进行一个呈现。所以在机器学习的训练过程中可以做可视化。训练完成之后你也可以把结果呈现出来。
可视化视图
所以在训练前、训练中和训练后都可以使用可视化的工具。那这样的可视化的工具都有哪些?
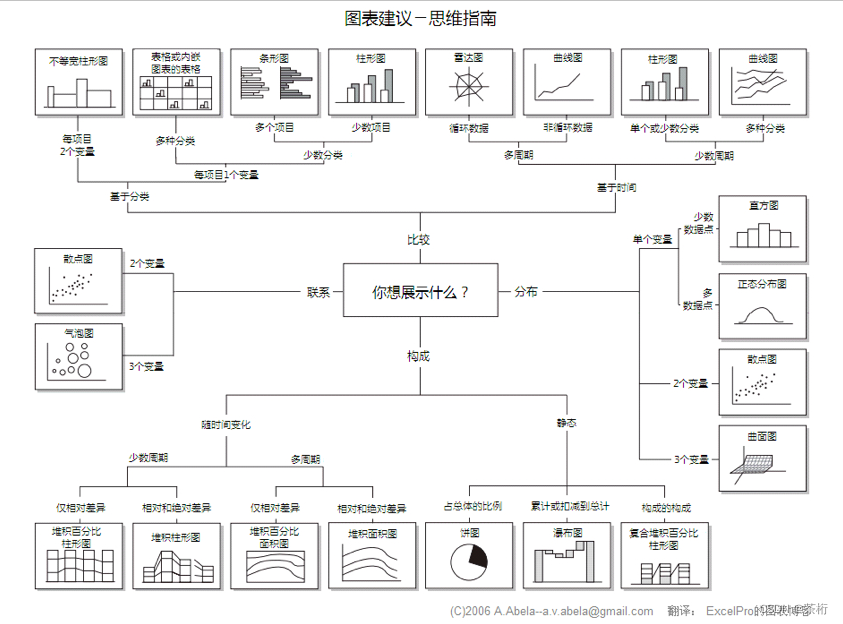
基本上,我们可以将可视化视图按类别区分一下,分成比较、联系、构成和分布。
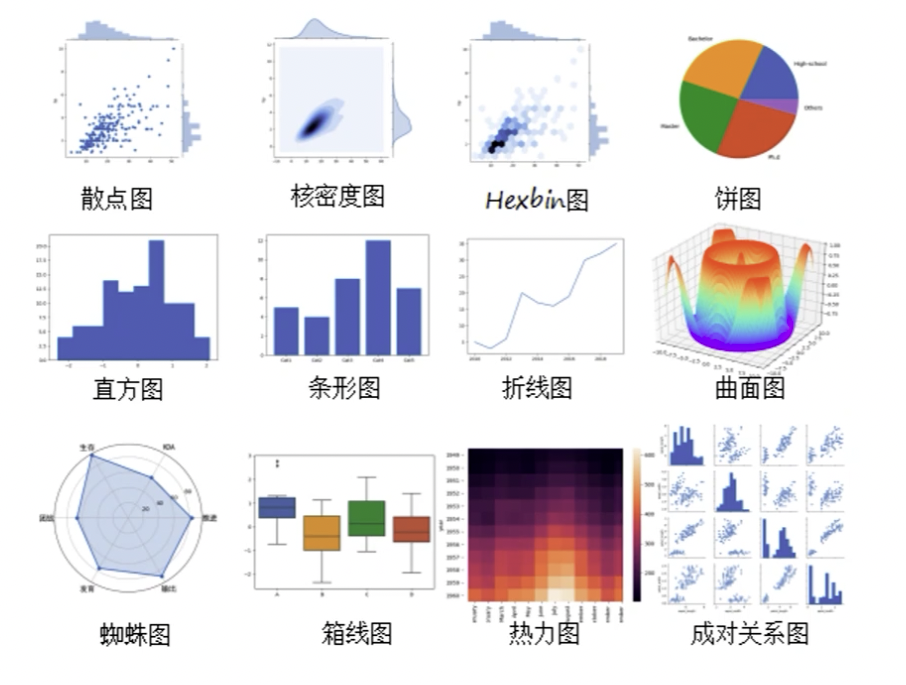
- 比较:展示事物的排列顺序,比如条图
- 练习:查看两个变量之间的关系,比如气泡图
- 构成:每个部分所占整体的百分比,比如饼图
- 分布:关心各数值范围包含多少项目,比如柱状图
图表可以说是非常非常多,如果我们要去学的话有三种必知必会的,在使用过程中用的场景非常的多。第一个散点图,第二个是看趋势用折线图,还有看对比用直方图。这三个是必须会的,那我们可以再加一个饼图。这几个图形基本上我们大概率都会用到。
除了这些图还有其它的一些图,比如说像雷达图,然后做一些地图的呈现等等都可以去来做。那么在 Python 中我们会用到两个包,一个是 Matplotlib, 一个是 Seaborn。
那我们第一眼看到 Matplotlib 的时候会想到什么工具跟它有关系?不知道有没有小伙伴在读研究生的时候会用到一个数据仿真软件,叫做 MATLAB。

这个软件有用过的同学可以给我留言,我们一起可以交流一下。这个软件如果你在做仿真实验的时候研究生期间有可能会用到,但是后来可能用的没有那么的多了,因为之前有过一个针对哈工大的名单事件。
我们在 Python 里面使用的 Matplotlib 本身是个开源工具,它不是商业化的 MATLAB,是 MATLAB 的一个竞争对手开发的一个工具。它把这个工具开源出来,作用是帮你来做可视化的呈现。
在可视化呈现的编码过程中你会发现它跟 MATLAB 很像,比如说我们要设置子图,画图等等。好在 Python 就是一个开源的生态系统,基于它我们基本上可以实现你想要实现的任何的图表,都是可以完成的。
那 Matplotlib 和 Seaborn 之间有没有区别呢?你可以把 Matplotlib 认为是一个基础版本,它是个底层的东西,而 Seaborn 是一个基于 Matplotlib 的高级封装,它在 Matplotlib 的基础上去封装了一些代码,让你使用起来会更加的方便。
Python 进行可视化
下面我们给大家看一下这些代码的实践的过程,第一个是散点图,先来随机生成的一些数据
# 数据准备
N = 500
x = np.random.randn(N)
y = np.random.randn(N)
如果你用 Matplotlib 的是用 scatter,scatter 代表散点的含义。把 x,y 在坐标轴上绘制出来。
# 用 Matplotlib 画散点图
plt.scatter(x, y, marker='x')
plt.show()
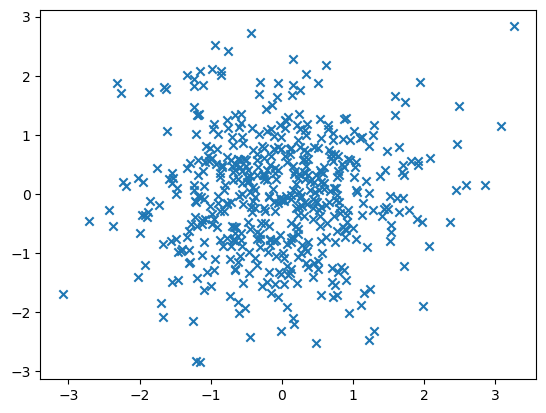
marker 代表的是你绘制的这个样式,它是一个x的样式。这个就是我们的第一张图。
第二张图用的是 seaborn 这个工具箱。这个工具箱我们先用了一个 DataFrame 的样式。DataFrame 平时应该是在 Python 里面使用频率最高的。你要处理任何的数据基本上都离不开 DataFrame。
我们可以直接在 DataFrame 的基础上去喂给 sns,这样我们直接把 DataFrame 传给我们的 data,然后指定 x 轴和 y 轴。
# 用 Seaborn 画散点图
df = pd.DataFrame({'x':x, 'y':y})
sns.jointplot(x='x', y='y', data=df, kind='scatter')
plt.show()
kind 我们用选散点图 scatter,最后给它呈现出来。
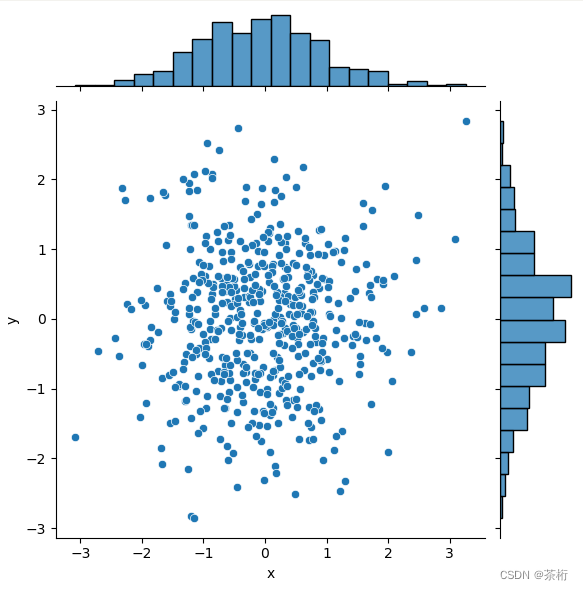
两相对比之下,matploylib 的图就没有那么方正,seaborn 似乎更没罐一些。
seaborn 的散点图上面和右面都有多出来的一部分,它是额外做了一个辅助的标记,代表着数据分布情况。那这可以看到,两边和上下的分布的比较散比较少,中间的部分数据比较集中,也比较多。它是一个分布直方图。
这是我们第一个,散点图的一个样式。
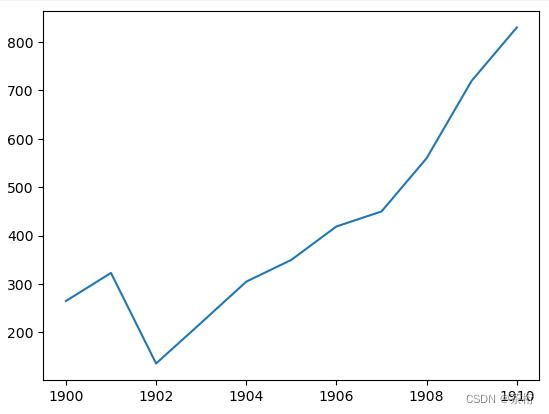
第二个图也是使用场景比较多,就是折线图。什么情况下会选择折线图呢?我们接下来的一个数据模拟,是从 1990 开始到 1910。所以它应该是用于连续数据,主要用到跟时间序列相关,或者用的是一个叫做趋势项,要看趋势就离不开折线图。
我们还是先来准备一下数据:
# 数据准备
x = [1900, 1901, 1902, 1903, 1904, 1905, 1906, 1907, 1908, 1909, 1910]
y = [265, 323, 136, 220, 305, 350, 419, 450, 560, 720, 830]
然后依然是先来看看 matploylib 的呈现:
# 使用 Matplotlib 画折线图
plt.plot(x, y)
plt.show()
接着是 seaborn
# 使用 Seaborn 画折线图
df = pd.DataFrame({'x':x, 'y':y})
sns.lineplot(x='x', y='y', data=df)
plt.show()
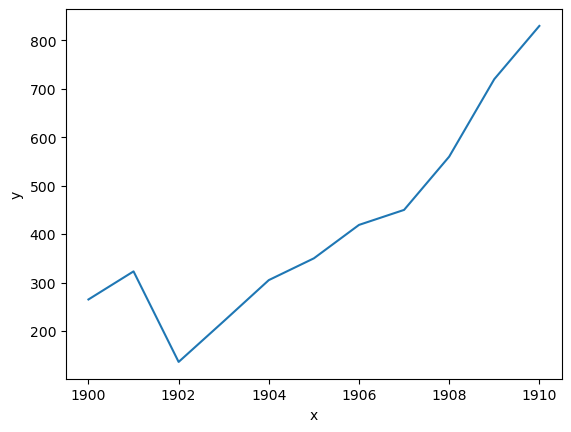
这个折线图里,x 是代表时间轴,y 是它的统计量。一起来看一看这两张图,呈现出来的样式谁会更加美观一点?说实话,看不出什么差别,基本上都是一样的。
第三个是条形图。条形图有的时候也叫直方图,直方图就经常用于不同类别之间的一些对比。那这两种工具都可以做直方图的呈现,我们还是一样,进行数据生成后来看看两个的区别:
# 数据准备
x = ['c1', 'c2', 'c3', 'c4']
y = [15, 18, 5, 27]# 用 plt 来画条形图
plt.bar(x, y)
plt.show()# 用 seaborn 来画条形图
sns.barplot(x=x, y=y)
plt.show()
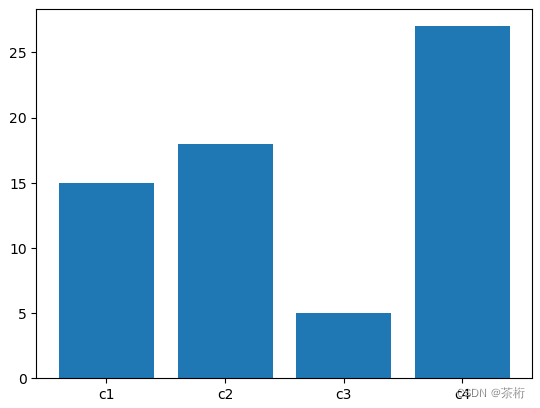
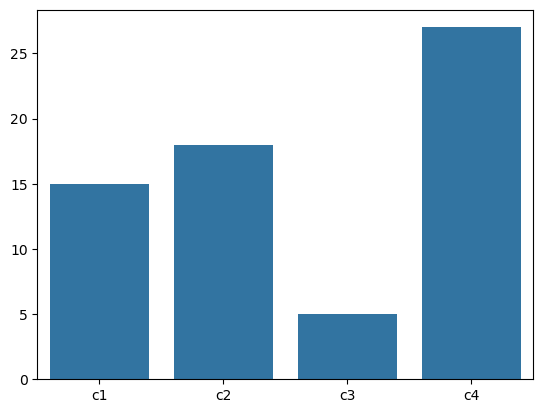
上面是 Matploylib, 下面是 Seaborn。说实话,没啥区别。本来 Seaborn 应该在柱子的颜色上有所区分的,我印象中以前使用 Seaborn 是默认带颜色的,现在这个 0.13 版本不知道是取消了还是用法和以前不一样了。
前面给大家讲完了散点图、折线图和条形图,下面咱们来看看箱线图。我们一起来看看,先模拟一下数据:
# 生成数据
# 生成 0-1 之间的 20*4 维度数据
data = np.random.normal(size=(10, 4))
labels = ['A', 'B', 'C', 'D']
这个数据模拟了 ABCD 四个类别,每个类别里面有 10 个数据。然后我们来画图:
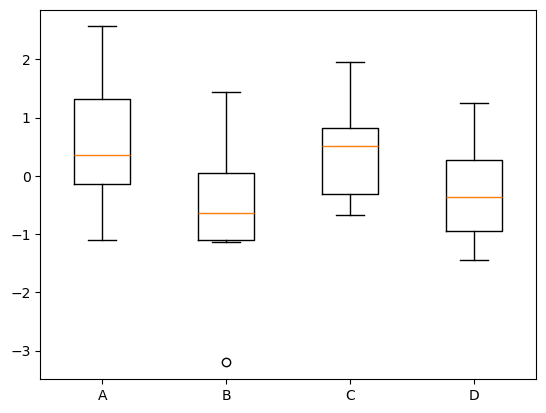
# 用 Matplotlib 画箱线图
plt.boxplot(data, labels=labels)
plt.show()
# 用 Seaborn 画箱线图
df = pd.DataFrame(data, columns=labels)
sns.boxplot(data=df)
plt.show()
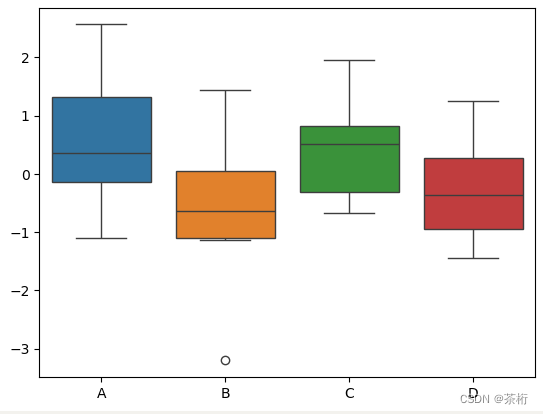
这个图的区别就比较明显了。有些人喜欢朴素一点的,有些人喜欢颜色显明一点的是吧。
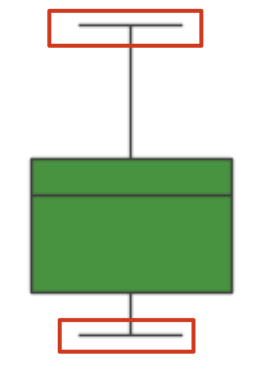
我们看一看某一个单独的箱子,上面这个线和下面这个线,这两条线代表什么含义?上面线和下面线你可以把它理解成一个是 Max
一个是 min,或者把它理解成是 100%和 0%,数据正常范围的 0%到 100%,也就是极值。
再来看箱子本身的上下的这两条边线
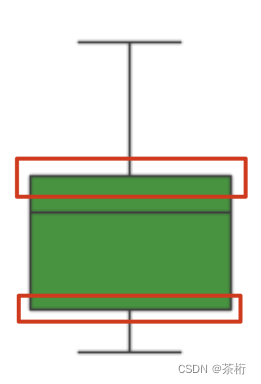
这两条线代表的含义,一个应该是四分位数的 75%,还有一个是 25%。这个就跟股票阴阳线是差不多的。那箱子里面中间那条线,就是数据的 50%。
所以箱线图是把它的数据特征从 0%、25、50、75 和 100 都呈现了出来。
最后还有,我们注意看 label B 的位置,在箱子下面有一个圆点,它在箱子的外面。那这个点是什么?那这样的一个点就是异常值,称为离群点。
所以箱线图可以用于我们特征的统计,也可以帮你来判断这样的一个特征里面有没有一些异常值,你可以把它用于异常值的检测的使用。
那下面一个图我们就很熟悉了,我们来看看饼图:
# 数据准备
nums = [25, 33, 38]# 射手 adc, 法师 apc, 坦克 tk
labels = ['adc', 'apc', 'tk']# 用 matplotlib 画饼图
plt.pie(x=nums, labels=labels)
plt.show()
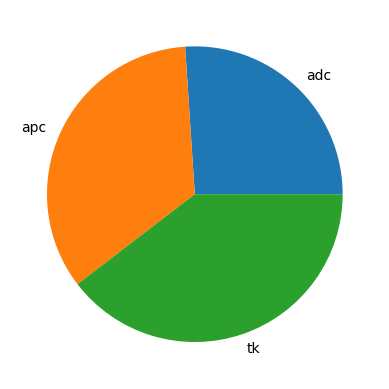
这张图只有 matplotlib 的,是因为 seaborn 里面我没有找到有相关的饼图的绘制方法,只有在 matplotlib 里有绘制,通过 pie 方式就可以给它绘制出来。
然后我们来看看热力图
# 数据准备
np.random.seed(2021)
data = np.random.rand(3,3)sns.heatmap(data)
plt.show()
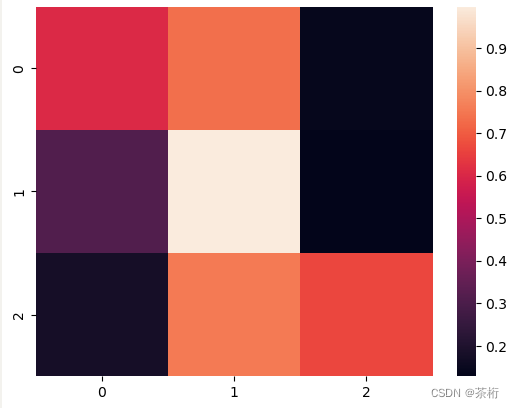
那热力图我们在之前的课程中就有看到过了,当我们需要找数据之间的相关性的时候,就能看到这张图。热力图的含义就是把数字转换成为颜色。
我们看右边的热力值的那一条柱子,颜色比较浅的部分,它的数值就比较高,如果数值比较低的话它会比较深。所以我们把这个数值和颜色之间做了一个映射。
除了相关性系数之外,我们看到天气预报会在地图上面做呈现。如果一个地方 37 度,有个地方是 15 度、10 度,观看数字没有这么直观,但如果把颜色给你标识出来,温度很低的地方用蓝色,温度很高用深色的,暖色的。这样就非常直观。知道全国每个地区哪些温度高,哪些温度低。所以热力图它就是一种非常直观的形象的方式来了解数值的大小。
那接下来的这张图就是雷达图,我们也可以叫它蜘蛛图。我们说马龙是六边形战士是吧,那这个六边形就是在雷达图上做了展示。还有,我们的英雄比赛完以后可以通过它的画像,可以比较这几个维度的高低之分。它是做多维度的展示,它会把 6 个维度指标用一个雷达图来做个呈现。
我这边写数据就用咱们的英雄的比赛来做,六个维度:KDA、生存、团战、发育和输出。
# 数据准备
labels = np.array([u'推进', 'KDA', u'生存', u'团战', u'发育', u'输出'])stats = [76, 58, 67, 97, 86, 58]
然后在画图之前,我们需要做一些准备工作,包括数据准备,角度和状态值。这里需要注意的是,我们虽然是 6 个维度,但是需要多生成出来一个坐标点和第一个点重叠,否则连线是无法闭合的,那这个闭合点包括标签,角度和数据都需要做:
# 画图数据准备,角度,状态值
angles = np.linspace(0, 2*np.pi, len(labels), endpoint=False)
stats = np.concatenate((stats, [stats[0]]))
angles = np.concatenate((angles, [angles[0]]))
labels = np.concatenate((labels, [labels[0]]))# 检查角度和标签的数量是否相同
print(len(angles), len(labels)) ---
7, 7
然后我们就可以用 matplotlib 来画雷达图了,画图之前,我们要知道 matplotlib 显示图像如果有中文和负号,基本会显示乱码,也就是显示成一个个的方框,这个要提前处理一下,设置一下中文默认字体和解决负号问题:
from pylab import mpl# 设置中文字体
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像负号'-'显示为方块的问题# 用 matplotlib 画雷达图
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, stats, 'o-', linewidth=2)
ax.fill(angles, stats, alpha=0.25)ax.set_thetagrids(angles*180/np.pi, labels)
plt.show()
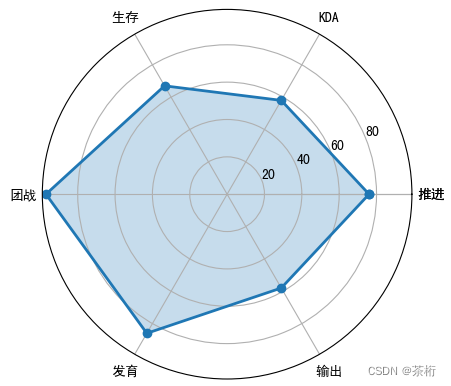
那我们可以很直观的看到,这场比赛我们的英雄团战的指标很高,那哪个指标万的不太好呢?就是 KDA 和输出都不是太好,比较低。
所以通过雷达图就非常一目了然,它主要用于多维度的判断和分析。那其实雷达图在 Python 里面没有专门的工具箱,我们这一段代码的本质含义就是自己来画一个圈把线段给连接起来,最终再去设置一个阴影绘图。
下面我们来看一个图,这个图平时我们也有看到过,但是不常见。这个图叫做二元分布图。
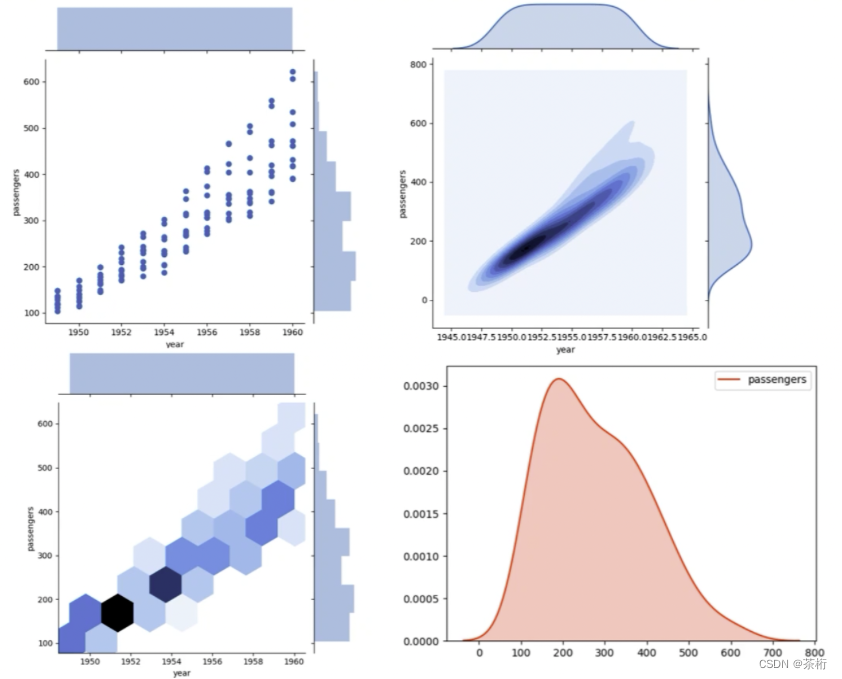
二元分布图主要用于两个特征之间的一个关联分析,这个图呢,我用了一个数据集来做示例,咱么弄一个美国航空公司的一个数据集。这是在 seaborn 里面自带的一个 dataset,先把数据加载进来。
# 数据准备
flights = sns.load_dataset('flights')
flights.info()---
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 144 entries, 0 to 143
Data columns (total 3 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 year 144 non-null int64 1 month 144 non-null category2 passengers 144 non-null int64
dtypes: category(1), int64(2)
memory usage: 2.9 KB
顺便我们观察了一下这个数据,可以看到这个数据里一个是有 144 个数据行,一共有 3 个特征,包括year, month和passengers。
观察数据是让大家知道,之后我们如果要用 seaborn 来画这个图的画,我的数据应该是整理成什么样。
好,接下来,让我们画三张图,一个是我们上面学过的散点图,一个是核密度图,一个是 Hexbin 图,先别管这些图都用来做什么,让我们先画出来,看着图才好去解释:
# 用 Seaborn 画二元变量分布图(散点图,核密度图,Hexbin 图)
sns.jointplot(x='year', y='passengers', data=flights, kind='scatter')
sns.jointplot(x='year', y='passengers', data=flights, kind='kde')
sns.jointplot(x='year', y='passengers', data=flights, kind='hex')
plt.show()
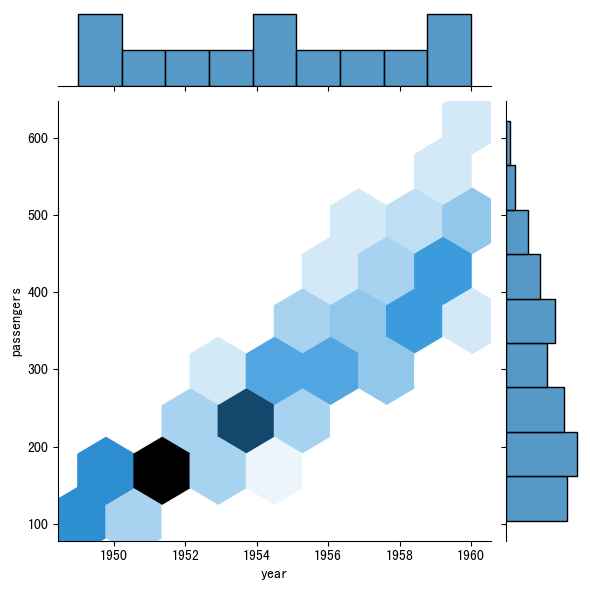
我们可以看到,这三障图在数据上一模一样,不同的就是最后的 kind,我们使用了不同的类型。我们从上到下依次粘贴一下图像来看看。
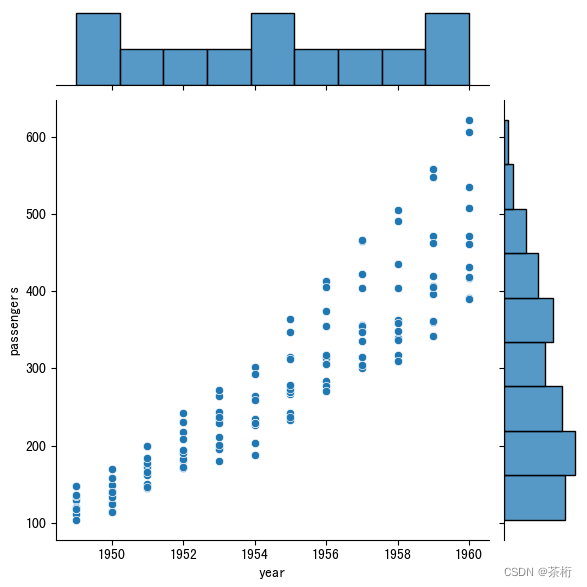
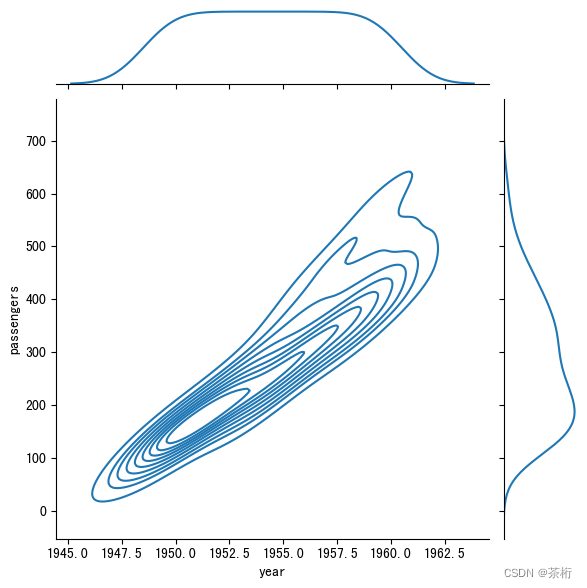
我们想要判断两个指标,年份和 passengers 这两个指标它们呈现的关系。第一张图,散点图可以看一看,可以看到随着时间的一个增长,乘客的数量也在线性的增长,是一个非常明显的一个趋势。这样就可以把两个特征之间的关系用一个散点图来做呈现。
那二联分布的关系除了散点图以外,kind 还可以指向kde,它叫做核密度图,还有hex叫做蜂窝图。基于图像我们能看出来和散点图呈现出了一个对应的关系,不同的是,在整个增长的趋势里,我们还可以看到最大的增长是在什么区间内,虽然散点图旁边的直方图上也能看得出来,但是核密度和蜂窝图就更直观的显示了具体的范围。
这是做了二元的一个关系,如果要看一元关系呢?一元关系里面直接用一个 KDE 核密度就把它的密度曲线给它呈现出来了.
# 查看 passengers 的分布情况(一元分布)
sns.kdeplot(flights['passengers'], color='red', fill=True)
plt.show()
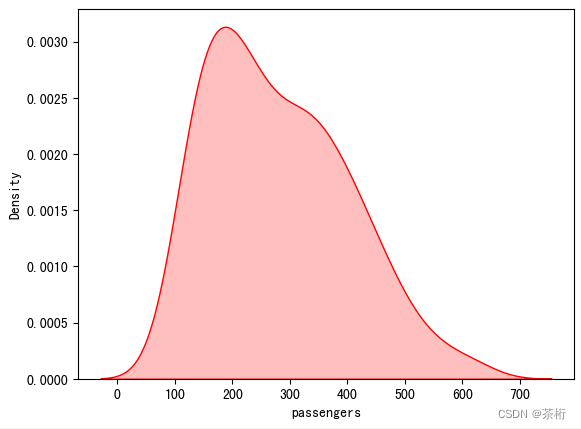
大家有没有发现这个曲线很熟悉,我们再来一个直方图大家观察一下:
sns.distplot(flights['passengers'], color='red')
plt.show()
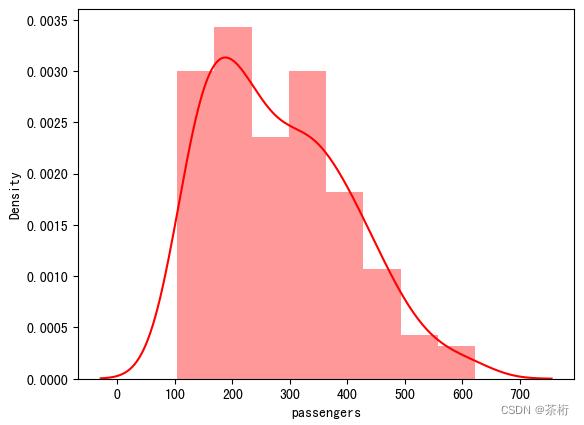
是不是曲线是一样的?这里多说一点,distplot这个方法在之后的 seaborn 里会被删除,被取代的是displot和histplot方法。新的displot方法里,kde 默认并不是 True 的状态,需要自己设置kde=True才可以看到曲线。
回到我们这张 kde 的一元呈现,这个密度曲线的含义,可以想一想,我们用的是一个passengers,现在的密度体现是一元的,我们使用的数据集是从 1949 年到 1960 年期间每个月份美国航空公司的乘客的数量,那么这个月份的乘客的数量它的密度曲线是怎样的可以用 kde 给它呈现出来。我们可以从中看到,200 到 300 之间的这个人数的密度最大,也就是出现的概率最多。哪个概率最低呢?700 以上的,还有就是 50 以下这样的概率是比较低的。
所以密度图是可以帮你来预估一个它的分布,这个一元密度图就单独预测它的出现的一个分布,二元呢就是这两者之间的一个相关关系。
在一元分布中,纵坐标就是 probability, 也就是我们的概率。
现在我们来想想,这整个的阴影面积,就是红色的曲线圈定的部分加起来应该等于多少?我们所有的情况把它做一个累加,它的面积累加求和等于 1。等于 1 的话,上面每一个点代表就是它的一个概率值。
比如说 200 的概率值,在这里大概对应出来就是 0.003,也就是百分之 0.3,所以他出现的概率就是 0.3%。这个数值看起来似乎很小,但其实后面还有 201、202,并不是我们看到的 200,300,200 到 300 之间其实还有 100 个数值,把所有的加到一起就等于我们整个面积为 1。
所以这个概率分布也挺重要的,给了这个数据集,我们可以预估出来。
除此之外,我们还有另外一种呈现方式:
sns.pairplot(flights)
plt.show()
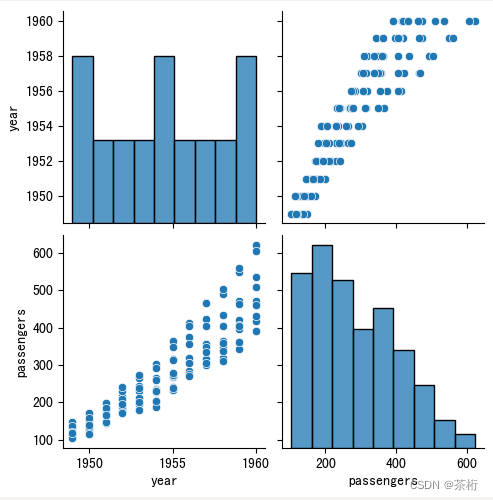
这样成对就把所有的组合都给你呈现出来了,这个数据集比较简单,只有两个特征,所以如果你用成对关系的就是 2 乘以 2。x 轴有两个,y 轴有两个。它的好处就是一次只用一条命令就可以把所有的可能性的关系给呈现出来。
现在我们来思考一下,如果换一个数据集,这个数据集里面有 5 个特征,那么现在用pairplot来做呈现,这张图里面会呈现出来多少种子图?应该是 5 乘上 5,就是 x 轴有 5 个特征,y 轴也有 5 个特征,每个特征和另外一个特征之间一个是 x 轴一个 y 轴,它们都可以呈现出来,所以它一共有 25 张图。
这 25 张纸图就不需要一个一个自己写了,直接可以用一条命令pairplot给呈现出来。在这个呈现过程中就可以一目了然的更容易发现哪两个特征之间是有关联关系的。
subplot
除了单张的图以外,我们还可以用一些分块的方式给它做一个细分。matplotlib 一个 figuer 对象可以包含多个子图(Axes), 可以使用subplot()快速绘制。它有三个参数,行(numRows),列(numCols)还有当下的座标位置(plotNum)。
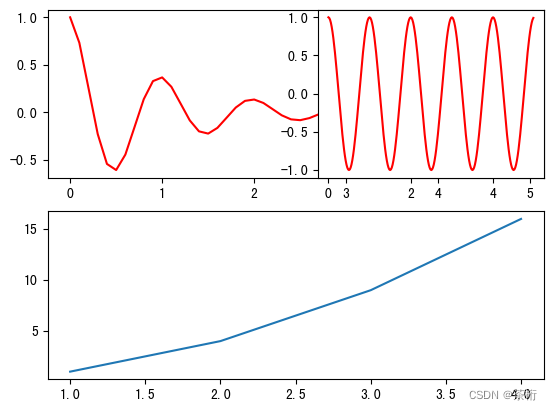
这张图不是很规则,如果你要划分的话可以分为上面一行,下面一行,然后左边是一列,右边还有一列,先这么去设置。
第一张图左上角的图我们去定义 subolot 内的参数,应该是 221,物理含义就是我们这张图的位置是把一张大图拆成了 2 乘以 2,它的第一张图,就是 221。右上角这张的参数那就应该是 222。
下面这张就有点不一样,行依旧是两行,但是列没有必要拆成两列。因为这个是把单元格合并到一起的,所以是把它看成了一列,所以应该是 212.
这三张子图的整个代码如下:
def f(t):return np.exp(-t) * np.cos(2*np.pi*t)t1 = np.arange(0, 5, 0.1)
t2 = np.arange(0, 5, 0.02)plt.figure()
plt.subplot(221)
plt.plot(t1, f(t1), 'r-')
plt.subplot(222)
plt.plot(t2, np.cos(2*np.pi*t2), 'r-')
plt.subplot(212)
plt.plot([1, 2, 3, 4], [1, 4, 9, 16])
plt.show()
你们可以拿来自己运行一下,就把上面那张图画出来了。subplot 就是画网格,然后数到底属于第几块网格。
比较规整的就如下面这样:
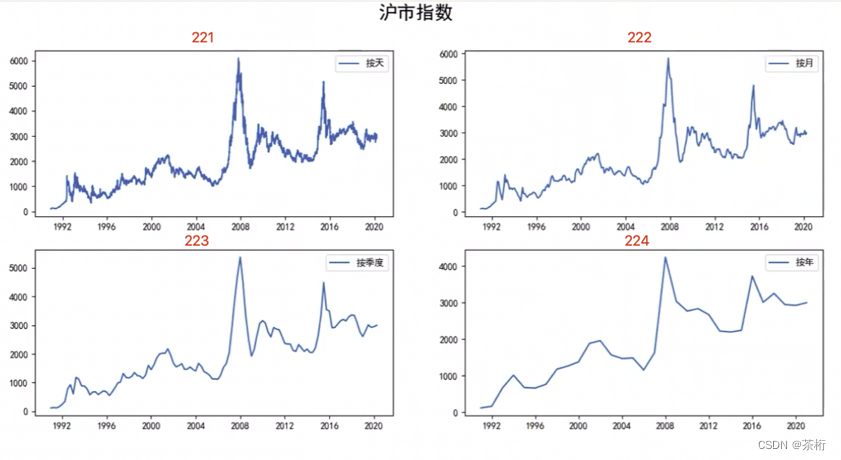
这个应该就简单一点,从左到右从上到下依次就是 221,222,223,224。这样你可以把一张大图分成几张小块,方便做绘制。为什么有的时候这么画呢?是因为图太多了,一张一张画会给你顺序排列,所以可以把它一张大图绘成几个小图的一个拼接的方法。
那以上就基本上把我们可视化用到的图表样式给大家讲完了,当然还有一部分没有讲到。我之前在讲 Python 基础的时候,有专门拿一章来讲过 Matplotlib,关于如何绘制图表大家可以去看看那一章,算是一个工具的使用手册,比较基础的部分。
在使用过程中你不需要背下来,只要把我的这两篇文章(之前 Python 部分的 Matplotlib 和本章)当成你的手册,可以下次使用的时候直接套。比如说直方图、散点图、折线图怎么做,直接套用就可以了。