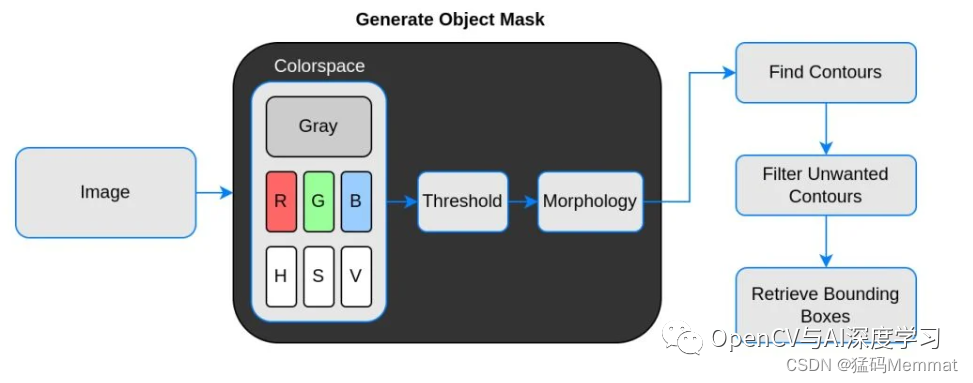
论文名称:Benchmarking Hashing Algorithms for Load Balancing in a Distributed Database Environment
摘要
现代高负载应用使用多个数据库实例存储数据。这样的架构需要数据一致性,并且确保数据在节点之间均匀分布很重要。负载均衡被用来实现这些目标。
几乎所有负载均衡系统的核心都是哈希算法。自经典一致性哈希引入以来,已经为此目的设计了许多算法。
负载均衡器的一个目的是确保存储集群的可扩展性。在节点添加或移除期间尽可能少地转移数据记录对整个系统的性能至关重要。负载均衡器中的哈希算法对这一过程影响最大。
在本文中,我们通过模拟和真实系统实验评估了几种用于负载均衡的哈希算法。为了评估算法性能,我们开发了一个基于Unidata MDM的基准测试套件——一个适用于各种主数据管理(MDM)应用的可扩展工具包。在评估中,我们采用了三个标准——产生的分布的均匀性、移动的记录数量和计算速度。根据我们实验的结果,我们创建了一个表格,在该表格中,每种算法根据上述标准进行了评估。
关键词:一致性哈希 · 数据库 · 基准测试。
1 引言
随着任何组织的增长,其企业数据资产的体积也随之上升。解决这一架构问题有两种常见方法[22]:垂直扩展和水平扩展。垂直扩展侧重于提高单个服务器的能力,而水平扩展涉及向集群添加机器。为了实现水平扩展,数据库表必须被水平分割成部分(分片),这些分片存储在不同的服务器节点上。
水平扩展有几个显著优势,例如通过改变集群大小灵活调整存储量的可能性。另一个优势是通过在服务器之间复制数据来处理数据丢失的能力。因此,出现了分布式数据存储的需求。
分布式存储的一个重要组成部分是负载均衡器——一种决定哪个特定服务器将存储数据实体(例如记录、表的一部分等)的机制。评估负载均衡器的标准有几个。首先,服务器上的数据分布应尽可能接近均匀。接下来,如果集群大小发生变化,移动的数据实体数量必须接近最优。最后,负载均衡器的计算成本不应该高。
为了计算分配给给定数据实体的分片,负载均衡器使用哈希算法。自90年代以来,已经专门为平衡不同类型的负载(如网络连接管理、分布式计算优化和数据存储平衡)设计了许多哈希算法。
专注于大数据量存储和处理的研究领域之一是主数据管理[1,19](MDM)。它围绕主数据的概念——结合了对组织内业务运营重要的对象,如库存、客户和员工。MDM的主要目标是统一、协调和确保企业主数据的完整性。
在本文中,我们比较了几种哈希算法,并评估了它们对负载均衡问题的适用性。我们通过模拟和真实测试对它们进行了实验性评估。对于后者,我们使用了Unidata平台[10] —— 一个具有分布式存储能力的开源MDM工具包。根据我们实验的结果,我们创建了一个表格,在该表格中,根据上述标准对每种算法进行了评估。
本文的结构如下。在第2节中,我们描述了一些现有的负载均衡算法,定义了MDM领域的几个术语,并回顾了Unidata存储架构。然后在第3节中,我们描述了进行的实验,并在第4节中讨论了取得的结果。我们在第6节总结了本文。
2 背景和相关工作
在本节中,我们描述了那些我们将要基准测试的现有哈希算法,由于我们的最后一系列实验是在真实系统上运行的,我们还提供了系统本身、其目的和使用的数据模式的一般描述。
这项研究涉及两个研究领域,它们都有丰富的研究成果——负载均衡和哈希算法。前者有大量的调查描述了数十项工作。例如,考虑研究[8],它引用了许多更多类似的调查。不幸的是,这些调查只使用一些高级标准(例如,适应性、静态或动态、抢占性等)对覆盖的方法进行分类。它们没有对调查的算法进行实验评估。原因是这样的调查范围太广,它们审查的研究属于许多不同的领域,进行这样的评估将极其困难。同时,工业界对特定领域最佳方法感兴趣,答案只能通过实证找到。
转向哈希,我们必须提到一个非常全面的调查[3],它描述了许多哈希方法,并提出了一个算法分类。然而,关于数据导向哈希的部分旨在数据结构和机器学习,而不是负载均衡。我们在研究中考虑的哈希算法集合在这项调查中不存在。
因此,我们的工作填补了现有研究中的空白。
2.1 考虑的方法
让我们从用于数据平衡的哈希算法开始。每个考虑的负载均衡器都将其哈希函数应用于某些传入的数据实体,因此我们称应用的结果为一个键。负载均衡器的目的是将每个键与代表一个整数编号(id)的分片之一匹配。在本文中,我们考虑了几种哈希方法:
-
线性哈希是最古老的算法之一。除了经典版本[2]外,还有许多修改版本,如LH*[18]、LHM[14]、LHG[16]、LHS[15]、LHSA[13]和LH*RS[17]。这个算法家族的核心思想是计算键除以系统中分片数量的余数。因此,它们适用于解决具有固定分片数量的问题,这在我们的案例中是一个缺点。在我们的工作中,我们采用了用于PostgreSQL3分区的版本。
-
一致性哈希。最初,这个算法[9]被设计用于计算机网络的负载平衡。如今,它似乎是平衡许多不同类型负载的最流行方法。例如,像AWS DynamoDB[4]和Cassandra[11]这样的分布式系统使用一致性哈希进行分区和复制。这种方法基于在一个环上选择随机点,这是一个表示分片和数据实体为点的循环实数段。表示键的点被分配给顺时针最近的分片。为了确保数据均匀分布,每个分片由几个点表示。注意,这种方法的设计允许在只移动最优数量记录的情况下更改分片数量。
-
Rendezvous。类似于一致性哈希,这种方法[21]也是为了优化网络负载而开发的。对于给定的键,算法为每个分片计算成本函数的值,并将键分配给值最高的分片。添加或移除分片时,Rendezvous也不会移动额外的记录。
-
RUSH[6]被开发用于在磁盘集群中存储数据。它有两个修改版:RUSHR和RUSHT[7]。RUSH的作者专注于改进集群大小变化时数据分布的均匀性,因此,算法基于以下原则:每次更改集群大小时,使用一个特殊函数来决定哪些对象应该被移动以平衡系统。
-
Maglev是谷歌为Web服务负载均衡器开发的算法[5]。Maglev的目标是改善数据均匀性(与一致性哈希相比)并导致“最小干扰”,例如,如果分片集合变化,数据记录可能会被发送到它们之前所在的同一个分片。它被提出作为一致性哈希的一种新类型,在这种哈希中,环被替换为一个查找表,通过该查找表可以将键分配给一个分片。查找表的大小应该大于可能的分片数量以降低碰撞率。平均建议的查找时间是O(Mlog(M)),其中M是查找表的大小。
-
Jump是谷歌的另一个负载均衡器[12]。其作者将其呈现为一致性哈希的优越版本,它“不需要存储,更快,并且在将键空间均匀划分到桶中做得更好”。Jump仅为分片编号生成[0; #shards]范围内的值,因此添加新分片很快。然而,删除一个中间分片将导致许多记录重新哈希。运行Jump需要O(log(N))时间,其中N是分片数量。
-
AnchorHash。根据作者的说法,AnchorHash[20]是一种“保证最小干扰、平衡、高查找率、低内存占用和资源添加及移除后快速更新时间的哈希技术”。AnchorHash与其他讨论的算法的一个显著区别是它存储了一些关于系统之前状态的信息。
每篇提出新哈希算法的论文只将其与少数其他此类算法进行了比较。据我们所知,没有专门的比较这些算法应用于水平扩展问题的。同时,确保水平扩展的高性能是工业界需求的紧迫问题。因此,有必要评估所有这些算法并研究它们对这个问题的适用性。
2.2 基本定义
为了理解负载均衡器将被评估的数据存储的特点,有必要介绍一些MDM术语:
-
金记录。MDM的主要问题之一是为给定实体编译和维护“单一真相版本”[1],例如人、公司、订单等。为了实现这一目标,MDM系统必须从许多数据源(特定组织的信息系统)中汇总信息,形成一个干净、一致的实体,称为金记录。
-
有效期是实体信息有效的时间间隔。每个金记录可能存在几个有效期。查询数据时应考虑这一事实。有两个时间维度:事件的时间和此新信息版本引入系统的时间。这导致了一种特殊的存储方案来管理这些信息。
2.3 系统架构
MDM系统是信息管理系统的一个特殊类别[10]。它们的特点对平台存储架构和数据处理提出了要求。
首先,必须支持存储对象的版本控制。因此,描述存储对象的数据资产具有有效期,查询数据时应考虑这些有效期。
其次,删除操作只能由管理员执行,而用户只能将数据实体标记为已删除。这是为了避免信息丢失并确保正确的版本控制支持所必需的。有时,这种数据处理语义有法律要求。这种架构模式通常被称为墓碑删除。
第三,应提供溯源。这意味着任何系统操作都应该是可追踪的。例如,必须有一种方法可以在每次操作后回滚所有记录的更改。
所提出的方法基于以下四个表,其中三个代表实体:
-
Etalon存储金记录本身的元数据。
-
Origin存储与记录源系统相关的元数据。
-
Vistory(版本历史)是origin的有效期,反过来可能有修订。
-
外部键是一个表,用于从Unidata存储的其他部分访问数据。
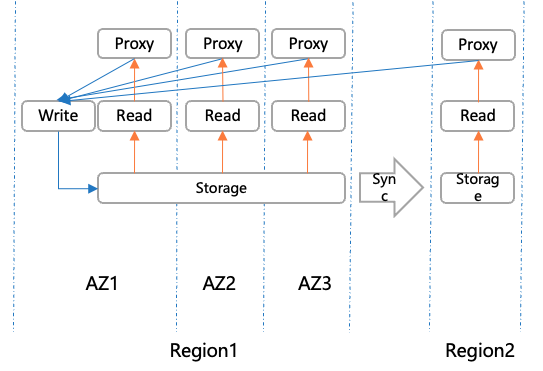
这些表之间的关系如图1所示。空心箭头表示的链接表示“共享”(继承)属性,实心箭头显示PK-FK(主键-外键)关系。表属性的详细描述可以在[10]中找到。

3 评估
为了选择最适合负载均衡问题的哈希算法,我们进行了实验评估。
3.1 实验设置
实验使用以下硬件和软件配置进行:
- 硬件:LENOVO E15,16GiB RAM,Intel(R) Core(TM) i7-10510U CPU @ 4.90GHz,TOSHIBA 238GiB KBG40ZNT。
- 软件:Ubuntu 20.04.4 LTS,Postgres 11.x,JDK 11.x,Tomcat 7.x,Elasticsearch 7.6.x。
某些算法有影响其性能的参数:
- 对于一致性哈希,为每个分片选择了16个点。这个数字是通过实验选出的,作为哈希速度和初始分布均匀性之间的折衷。
- 对于Maglev,查找表大小设置为10^3。与一致性哈希类似,这个数字是通过实验选出的。注意,这个值在重新平衡过程中很重要,但对于查找不是。
- 对于AnchorHash,我们将|A|(算法处理的桶的数量)设置为最大分片数量的两倍(即64),正如原始论文[20]中推荐的。
3.2 结果
为了评估负载均衡算法,我们定义了三个评价标准,并按其重要性降序排列:
- 产生的数据分布的均匀性。
- 在添加或移除分片期间记录的冗余移动。
- 查找速度。
为了选择最佳算法,我们进行了三项实验。首先,在Google Colab中进行了负载均衡模拟实验(使用Python)。这一步是为了进行算法性能的初步浅层评估。具体操作如下:首先生成了10K条记录,并通过哈希函数分配到32个分片中。因此,均匀分布将导致每个分片有312条记录。之后,计划移除8个分片,并强制系统重新平衡数据。因此,均匀分布应该导致每个分片有416条记录。这个过程针对每个考虑的负载均衡器(哈希函数)运行。
十次这样的实验的平均值如表1所示。表的第一列包含分片计算的平均时间,第二和第三列分别展示了重新平衡前后分配给分片的记录的方差。最后一列显示了实际移动的记录数量与最优数量的比率。
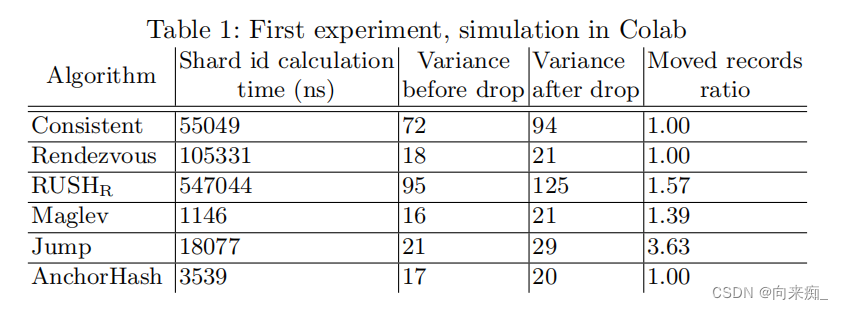
基于实验结果,我们决定由于未能满足所有三个标准,排除RUSHR进一步考虑。我们还排除了Jump,因为重新平衡的质量较差。
我们的下一个实验涉及Unidata平台,该平台是用Java实现的。为了验证先前获得结果的一致性和可转移性,我们决定在平台内重新评估分片id计算时间。因此,第二个实验也是在分片中分配10K记录。测量的平均值如下:
- 线性哈希 — 808ns
- 一致性哈希 — 2419ns
- Rendezvous — 5945ns
- Maglev — 807ns
- AnchorHash — 2015ns
可以看出,算法运行时间的顺序与之前的实验相比没有变化。因此,我们可以得出结论,切换编程语言并未影响之前实验的结果,我们可以继续使用Unidata平台。
第三个实验使用部署的Unidata平台进行。其存储配置如下:四个Docker节点,每个节点上有八个分片的PostgreSQL。我们生成了10K个外部键和标准作为工作负载。实验的思路如下:依次移除三个节点,然后以类似方式再添加回来。
评估的结果显示在以下图表中。每个重新平衡步骤花费的总时间显示在图2中,移动的标准数量显示在图3中。我们省略了外部键的这样的图表,因为它基本上是相同的(是1:1映射)。每个步骤中分片之间数据分布显示在图4和图5中。
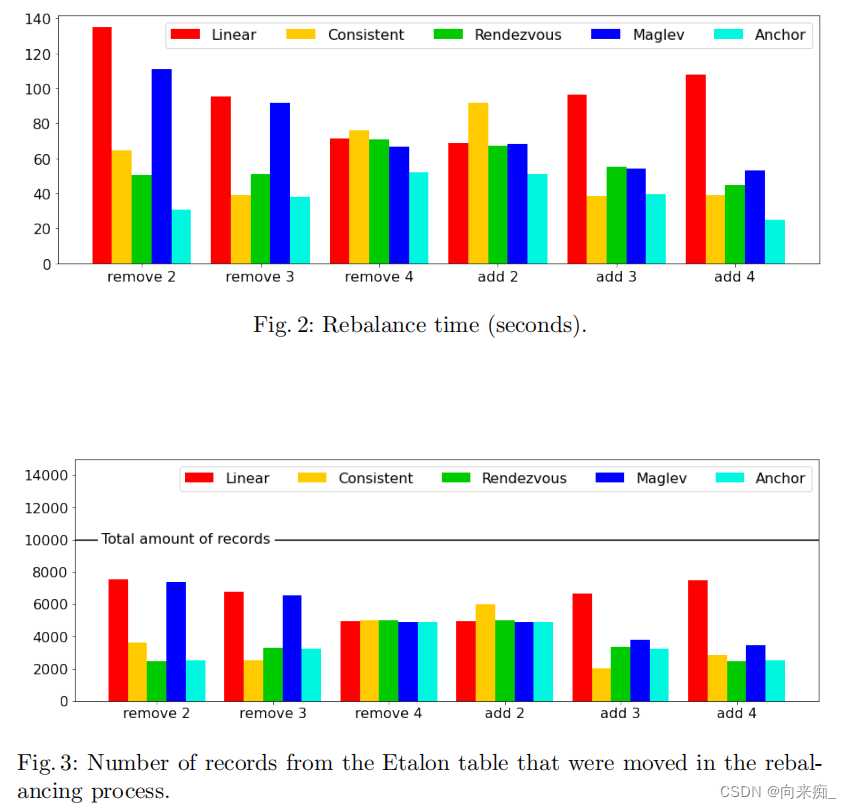
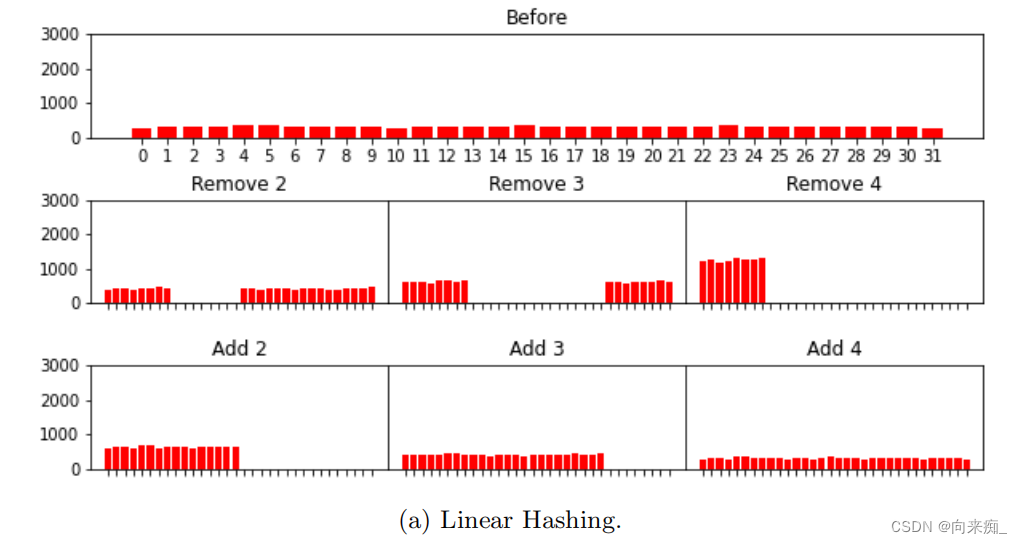

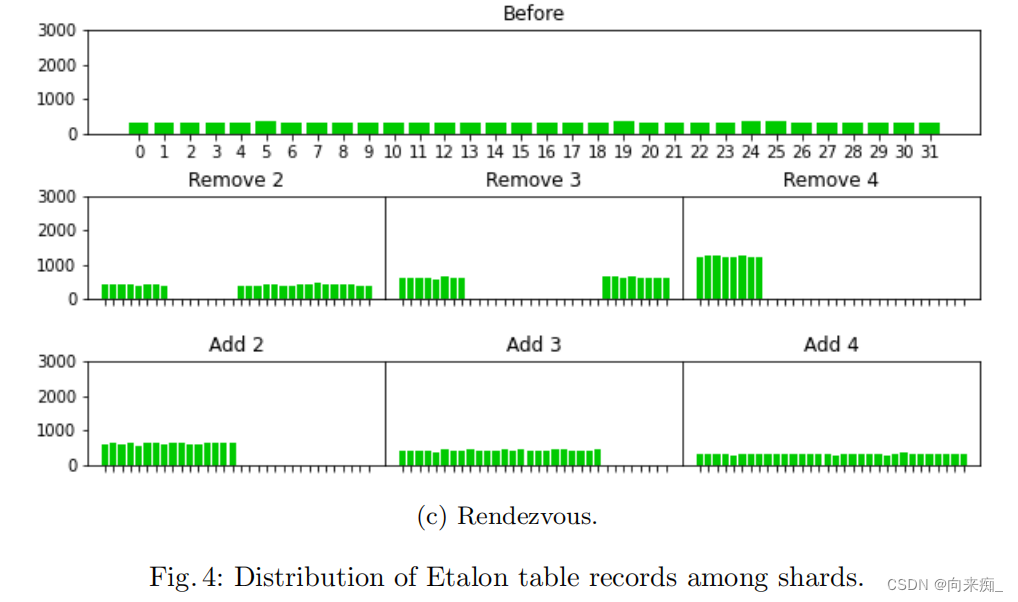
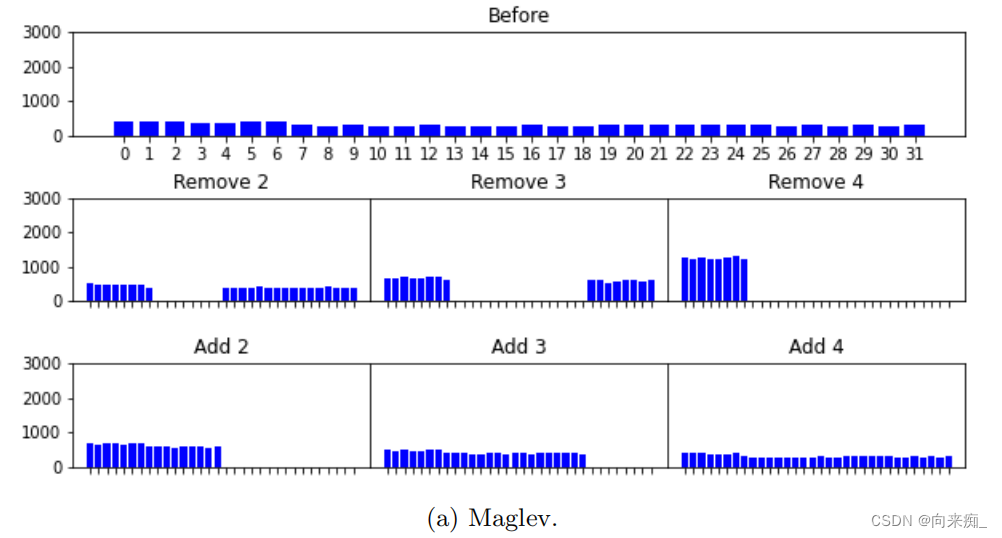
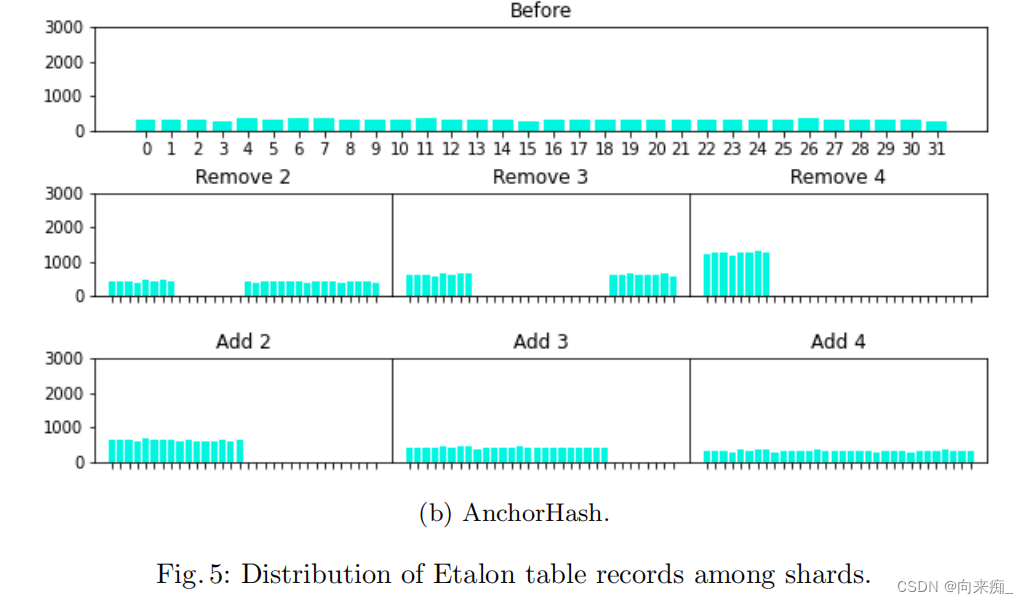
这个实验让我们得出以下结论:
- 一致性哈希、Rendezvous和AnchorHash移动的记录数量比线性哈希少超过50%。
- 在前两个重新平衡步骤中,Maglev移动的记录数量大约与线性哈希相同,但在最后两个步骤中,Maglev移动的记录数量显著减少,并接近其他三种方法。
- 线性哈希、Rendezvous、Maglev和AnchorHash分布数据足够均匀,但一致性哈希在分片体积上有显著差异。
4 讨论
现在让我们讨论每种考虑的算法与第3节定义的标准的一致性。
- 线性哈希在分片中的记录分布适当且查找速度高,但在每次重新平衡时会移动高达80%的记录,因此这种方法不符合我们的标准。然而,线性哈希可以应用于分片数量固定的系统中。
- 一致性哈希在移动最优数量的记录时具有可接受的查找时间,但数据分布极不均匀。应优先选择分布更均匀的方法。为了提高分布质量,可以增加环上每个分片的点数,但这将减慢查找速度。
- Rendezvous在数据重新平衡和分布方面是最佳的,但查找时间最长。由于查找速度是优先级最低的标准,因此这种方法适合我们。
- RUSHR不满足所有三个标准,因此不适合我们的目标。
- Maglev提供快速查找和相对均匀的分布,但在某些情况下,它可以移动超过50%的所有记录(见图3上的水平线)。因此,Maglev适用于分片数量固定的系统。
- Jump移动的记录数量最多(表1),因此也不适用。
- AnchorHash到目前为止似乎是赢家,因为它满足了所有要求。
根据所有三项实验的结果,我们创建了一个表格,在其中列出了所有评估的算法(表2)。我们根据我们的三个标准对它们进行了评估,并按三个质量等级——低、中、高——分配了评级。
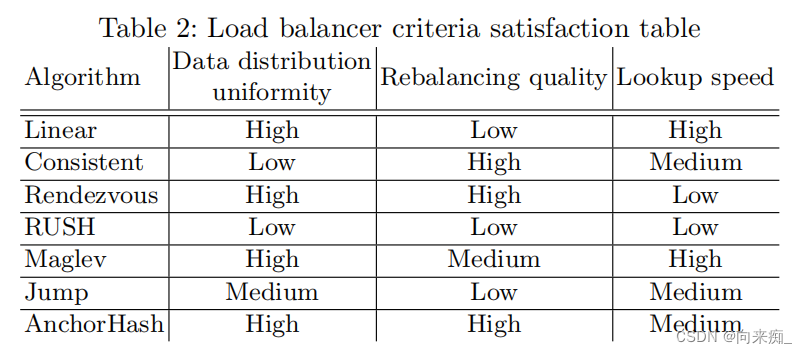
从表中可以明显看出,有两个获胜的算法——Maglev和AnchorHash,它们未能达到最佳重新平衡质量(移动记录的数量)或最高查找速度。
AnchorHash均匀地分布数据,移动了最优数量的记录,其查找时间也足够短。Rendezvous也符合第一和第二标准,但其查找时间是AnchorHash的两倍多。这两种方法适用于频繁添加或移除分片的系统。
另一方面,Maglev的查找速度是Rendezvous的两倍多,因此它适用于静态系统,类似于Jump和线性哈希。
一致性哈希似乎对两种类型的系统都有效,但其主要缺点是分片之间的数据分布不均匀。
RUSHR被证明是所有算法中最差的。
5 致谢
我们想感谢Anna Smirnova在准备本文中的帮助。
6 结论和未来工作
在本文中,我们研究了几种哈希算法,并评估了它们在分布式数据库中平衡数据的适用性。为此,我们进行了模拟和真实实验。真实实验使用Unidata平台进行,这是一个用于构建MDM解决方案的开源工具包。在这些实验中,我们采用了三个适用性标准,即产生的数据分布的均匀性、移动记录的数量和计算成本。
实验表明,在七种考虑的算法中有两个明确的赢家——AnchorHash和Maglev。另外两个,线性哈希和Jump,可能也有一些适用性。
扩展本文的几个可能方向。首先,我们注意到随机数生成器对某些算法的行为有一定影响。在当前的论文中,我们为所有算法固定了它,但探索这种影响可能是值得的。其次,研究改变算法参数的影响可能会很有趣。在本文中,我们使用了默认的或推荐的参数,但仔细调整可能会产生积极的结果。


![详解洛谷P2912 [USACO08OCT] Pasture Walking G(牧场行走)(lca模板题)](https://img-blog.csdnimg.cn/direct/b373e33186b043ac86e3a7a5566a4a7f.png)