TreeMap 集合
- 1. 概述
- 2. 方法
- 3. 遍历方式
- 4. 排序方式
- 5. 代码示例1
- 6. 代码示例2
- 7. 代码示例3
- 8. 注意事项
- 9. 源码分析
其他集合类
父类 Map
集合类的遍历方式
TreeSet 集合
具体信息请查看 API 帮助文档
1. 概述
TreeMap 是 Java 中的一个集合类,它实现了 SortedMap 接口。它是基于红黑树的数据结构实现的,它能够保持其中的元素处于有序状态。
-
TreeMap 集合中的元素是以键值对的形式存储的,其中的键用于排序和唯一性的保证,而值则用于存储具体的数据。
-
TreeMap 根据键的自然顺序或者自定义的比较器来进行排序,使得在遍历 TreeMap 集合时能够有序地访问其中的元素。
TreeMap 集合的特点:
-
TreeMap 中的键必须是可比较的,要么实现了 Comparable 接口,要么在构造 TreeMap 时提供了自定义的比较器。
-
TreeMap 中的键是唯一的,不允许重复的键存在。
-
TreeMap 是基于红黑树实现的,因此在插入、删除和查找操作的时间复杂度均为 O(logn),具有较高的效率。
-
TreeMap 中的元素是有序的,可以根据键来进行排序。
-
TreeMap 不是线程安全的,如果需要在多线程环境下使用,需要进行额外的同步处理。
2. 方法
TreeMap集合是Map集合的子类,因此Map集合的方法TreeMap集合都能使用。
Map集合
| 方法名 | 说明 |
|---|---|
| V put(K key,V value) | 添加元素 |
| V remove(Object key) | 根据键删除键值对元素 |
| void clear() | 移除所有的键值对元素 |
| boolean containsKey(Object key) | 判断集合是否包含指定的键 |
| boolean containsValue(Object value) | 判断集合是否包含指定的值 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合的长度,也就是集合中键值对的个数 |
3. 遍历方式
与共有的 集合遍历方式 一样
4. 排序方式
TreeMap集合和TreeSet集合一样,底层都是红黑树,因此排序方式一样
TreeSet 集合排序方式详解
-
默认排序规则/自然排序
-
比较器排序
5. 代码示例1
- 代码示例
需求:键:整数表示id;值:字符串表示商品名称
要求:按照id的升序排列,按照id的降序排列
package text.text02;
/*TreeMap基本应用:
需求:键:整数表示id值:字符串表示商品名称
要求:按照id的升序排列,按照id的降序排列
*/import java.util.Comparator;
import java.util.TreeMap;public class text52 {public static void main(String[] args) {//自然排序(升序排列)System.out.println("方法一:自然排序");method1(); //{1001=平板, 1002=汽车, 1003=手机, 1004=飞机, 1005=电脑}//比较器排序(降序排列)System.out.println("方法二:比较器排序");method2(); //{1005=电脑, 1004=飞机, 1003=手机, 1002=汽车, 1001=平板}}//自然排序(Java底层默认的自然排序就是按照升序排列)public static void method1() {//创建集合并添加数据TreeMap<Integer, String> tm = new TreeMap<>();tm.put(1003, "手机");tm.put(1005, "电脑");tm.put(1001, "平板");tm.put(1002, "汽车");tm.put(1004, "飞机");System.out.println(tm);}//比较器排序(当Java底层默认的自然排列不能满足需求时,采用比较器排列)public static void method2() {//创建集合(在创建对象的时候指定比较器规则)TreeMap<Integer, String> tm = new TreeMap<>(new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o2 - o1;}});//添加数据tm.put(1003, "手机");tm.put(1005, "电脑");tm.put(1001, "平板");tm.put(1002, "汽车");tm.put(1004, "飞机");System.out.println(tm);}
}- 输出结果
-
方法一:自然排序

-
方法二:比较器排序

-
6. 代码示例2
- 代码示例
需求:键:学生对象;值:籍贯
要求:按照学生年龄的升序排列,年龄一样按照姓名的字母排列,同姓名同年龄视为同一个人
package text.text02;import java.util.*;/*
需求:键:学生对象值:籍贯
要求:按照学生年龄的升序排列,年龄一样按照姓名的字母排列,同姓名同年龄视为同一个人*/
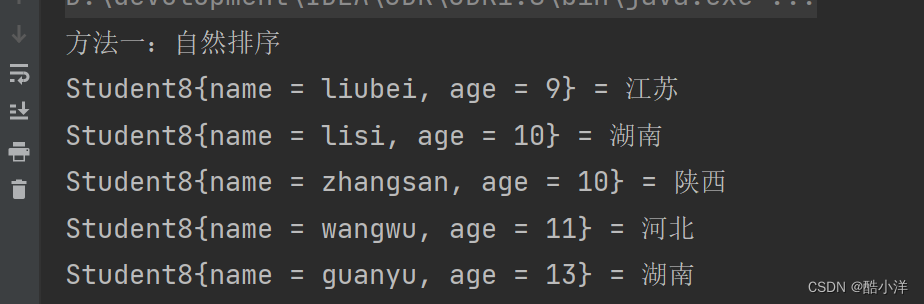
public class text53 {public static void main(String[] args) {//自然排序System.out.println("方法一:自然排序");method1();//比较器排序System.out.println("方法二:比较器排序");method2();}//自然排序 (Java底层默认的自然排序就是按照升序排列,自定义对象时,需要在Javabean类中实现Comparable接口并重写里面的CompareTo方法)public static void method1() {//创建学生对象Student8 student1 = new Student8("zhangsan", 10);Student8 student2 = new Student8("lisi", 10);Student8 student3 = new Student8("wangwu", 11);Student8 student4 = new Student8("liubei", 9);Student8 student5 = new Student8("guanyu", 13);Student8 student6 = new Student8("guanyu", 13);//创建集合对象TreeMap<Student8, String> tm = new TreeMap<>();//添加数据tm.put(student1, "陕西");tm.put(student2, "湖南");tm.put(student3, "河北");tm.put(student4, "江苏");tm.put(student5, "北京");tm.put(student6, "湖南");//遍历输出集合Set<Map.Entry<Student8, String>> entries = tm.entrySet();for (Map.Entry<Student8, String> entry : entries) {Student8 key = entry.getKey();String value = entry.getValue();System.out.println(key + " = " + value);}}//比较器排序(当Java底层默认的自然排列不能满足需求时,采用比较器排列,在创建对象时,指定比较规则)public static void method2() {//创建学生对象Student8 student1 = new Student8("zhangsan", 10);Student8 student2 = new Student8("lisi", 10);Student8 student3 = new Student8("wangwu", 11);Student8 student4 = new Student8("liubei", 9);Student8 student5 = new Student8("guanyu", 13);Student8 student6 = new Student8("guanyu", 13);//创建集合对象TreeMap<Student8, String> tm = new TreeMap<>(new Comparator<Student8>() {@Override//按照学生年龄的升序排列,年龄一样按照姓名的字母排列,同姓名同年龄视为同一个人public int compare(Student8 o1, Student8 o2) {//o1:表示当前要添加的元素//o2:表示已经在红黑树存在的元素//返回值://负数:表示当前要添加的数据是小的,存左边//正数:表示当前要添加的数据是大的,存右边//0:表示当前要添加的元素已经存在,舍弃int i = o1.getAge() - o2.getAge();i = i == 0 ? o1.getName().compareTo(o2.getName()) : i;return i;}});//添加数据tm.put(student1, "陕西");tm.put(student2, "湖南");tm.put(student3, "河北");tm.put(student4, "江苏");tm.put(student5, "北京");tm.put(student6, "湖南");//遍历输出集合Set<Map.Entry<Student8, String>> entries = tm.entrySet();for (Map.Entry<Student8, String> entry : entries) {Student8 key = entry.getKey();String value = entry.getValue();System.out.println(key + " = " + value);}}
}//学生对象
class Student8 implements Comparable<Student8> {private String name;private int age;public Student8() {}public Student8(String name, int age) {this.name = name;this.age = age;}/*** 获取** @return name*/public String getName() {return name;}/*** 设置** @param name*/public void setName(String name) {this.name = name;}/*** 获取** @return age*/public int getAge() {return age;}/*** 设置** @param age*/public void setAge(int age) {this.age = age;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Student8 student8 = (Student8) o;return age == student8.age && Objects.equals(name, student8.name);}@Overridepublic int hashCode() {return Objects.hash(name, age);}public String toString() {return "Student8{name = " + name + ", age = " + age + "}";}@Override//按照学生年龄的升序排列,年龄一样按照姓名的字母排列,同姓名同年龄视为同一个人public int compareTo(Student8 o) {//this:表示当前要添加的元素//o:表示已经在红黑树中的元素//返回值://负数:表示当前要添加的数据是小的,存左边//正数:表示当前要添加的数据是大的,存右边//0:表示当前要添加的元素已经存在,舍弃int i = this.getAge() - o.getAge();i = i == 0 ? this.getName().compareTo(o.getName()) : i;return i;}
}- 输出结果
-
方法一:自然排序
-
方法二:比较器排序

-
7. 代码示例3
- 代码示例
统计个数:
需求:字符串“aababcabcdabcde”,请统计字符串中每一个字符出现的次数,并按照如下格式输出。
输出结果:a(5)b(4)c(3)d(2)e(1)
package text.text02;import java.util.Map;
import java.util.Set;
import java.util.StringJoiner;
import java.util.TreeMap;/*
统计个数:
需求:字符串“aababcabcdabcde”,请统计字符串中每一个字符出现的次数,并按照如下格式输出。输出结果:a(5)b(4)c(3)d(2)e(1)新的统计思想:利用Map集合进行统计 (键:表示要统计的内容;值:表示次数)如果题目中没有要求对结果进行排序,默认使用HashMap如果题目中要求对结果进行排序,则使用TreeMap*/
public class text54 {public static void main(String[] args) {//创建数组存储每一个字符char[] arr = {'a', 'b', 'c', 'd', 'e'};//定义一个变量用于记录字符串String str = "aababcabcdabcde";//创建集合TreeMap<Character, Integer> tm = new TreeMap<>();for (int i = 0; i < str.length(); i++) {//如果双列集合中存在该字符,则获取双列集合中该字符的次数并将次数+1if (tm.containsKey(str.charAt(i))) {//获取双列集合中该字符的次数Integer value = tm.get(str.charAt(i));//将次数+1value++;//用新次数覆盖原次数tm.put(str.charAt(i), value);}//如果双列集合中存在该字符,则添加该字符并将次数改为1else {tm.put(str.charAt(i), 1);}}//遍历集合//1.利用StringBuilder修改输出格式//创建StringBuilder对象StringBuilder sb = new StringBuilder();Set<Map.Entry<Character, Integer>> entries = tm.entrySet();for (Map.Entry<Character, Integer> entry : entries) {//获取集合里的键Character key = entry.getKey();//获取集合里的值Integer value = entry.getValue();//将数据按照需求格式添加进StringBuilder集合sb.append(key).append("(").append(value).append(")");}System.out.println("1.利用StringBuilder修改输出格式:");System.out.println(sb); //a(5)b(4)c(3)d(2)e(1)//2.利用StringJoiner修改输出格式//创建StringJoiner对象StringJoiner sj = new StringJoiner("", "", "");Set<Character> set = tm.keySet();for (Character key : set) {Integer value = tm.get(key);//将数据按照需求格式添加进StringJoiner集合sj.add(key + "").add("(").add(value + "").add(")");//+" "是为了将key和value转换成字符串}System.out.println("2.利用StringJoiner修改输出格式:");System.out.println(sj); //a(5)b(4)c(3)d(2)e(1)}
}- 输出结果
-
1.利用StringBuilder修改输出格式:

-
2.利用StringJoiner修改输出格式:

-
8. 注意事项
-
键的唯一性:TreeMap 中的键是唯一的,不允许重复的键存在。如果尝试插入一个已经存在的键,新的值将会覆盖旧的值。如果需要存储允许重复键的情况,可以考虑使用其他集合类如 ArrayList 或者 HashMap。
-
键的可比较性:TreeMap 要求集合中的键必须是可比较的,要么实现了 Comparable 接口,要么在构造 TreeMap 时提供了自定义的比较器。如果键没有实现 Comparable 接口,并且没有提供自定义的比较器,则在插入元素或者进行比较操作时会抛出 ClassCastException 异常。
-
线程安全性:TreeMap 不是线程安全的,如果需要在多线程环境下使用 TreeMap,需要进行额外的同步处理。可以考虑使用 Collections 类的 synchronizedSortedMap 方法包装 TreeMap,或者使用并发集合类如 ConcurrentHashMap。
-
迭代顺序:TreeMap 中的元素是有序的,可以根据键来进行排序。通过 iterator 或者 forEach 遍历 TreeMap 时,元素会按照键的顺序以升序进行遍历。
-
性能开销:由于 TreeMap 的底层是红黑树,插入、删除和查找操作的时间复杂度均为 O(logn),相比于其他集合类可能会有较高的性能开销。如果对性能有较高要求,可以考虑使用其他集合类。
9. 源码分析
-
TreeMap中每一个节点的内部属性
K key; //键 V value; //值 Entry<K,V> left; //左子节点 Entry<K,V> right; //右子节点 Entry<K,V> parent; //父节点 boolean color; //节点的颜色 -
TreeMap类中中要知道的一些成员变量
public class TreeMap<K,V>{//比较器对象private final Comparator<? super K> comparator;//根节点private transient Entry<K,V> root;//集合的长度(节点的个数)private transient int size = 0; -
空参构造
//空参构造就是没有传递比较器对象 public TreeMap() {comparator = null; } -
带参构造
//带参构造就是传递了比较器对象。public TreeMap(Comparator<? super K> comparator) {this.comparator = comparator;} -
添加元素
public V put(K key, V value) {return put(key, value, true);}//参数一:键//参数二:值//参数三:当键重复的时候,是否需要覆盖值// true:覆盖// false:不覆盖private V put(K key, V value, boolean replaceOld) {//获取根节点的地址值,赋值给局部变量tEntry<K,V> t = root;//判断根节点是否为null//如果为null,表示当前是第一次添加,会把当前要添加的元素,当做根节点//如果不为null,表示当前不是第一次添加,跳过这个判断继续执行下面的代码if (t == null) {//方法的底层,会创建一个Entry对象,把他当做根节点addEntryToEmptyMap(key, value);//表示此时没有覆盖任何的元素return null;}//表示两个元素的键比较之后的结果int cmp;//表示当前要添加节点的父节点Entry<K,V> parent;//表示当前的比较规则//如果我们是采取默认的自然排序,那么此时comparator记录的是null,cpr记录的也是null//如果我们是采取比较器排序方式,那么此时comparator记录的是就是比较器Comparator<? super K> cpr = comparator;//表示判断当前是否有比较器对象//如果传递了比较器对象,就执行if里面的代码,此时以比较器的规则为准//如果没有传递比较器对象,就执行else里面的代码,此时以自然排序的规则为准if (cpr != null) {do {parent = t;cmp = cpr.compare(key, t.key);if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right;else {V oldValue = t.value;if (replaceOld || oldValue == null) {t.value = value;}return oldValue;}} while (t != null);} else {//把键进行强转,强转成Comparable类型的//要求:键必须要实现Comparable接口,如果没有实现这个接口//此时在强转的时候,就会报错。Comparable<? super K> k = (Comparable<? super K>) key;do {//把根节点当做当前节点的父节点parent = t;//调用compareTo方法,比较根节点和当前要添加节点的大小关系cmp = k.compareTo(t.key);if (cmp < 0)//如果比较的结果为负数//那么继续到根节点的左边去找t = t.left;else if (cmp > 0)//如果比较的结果为正数//那么继续到根节点的右边去找t = t.right;else {//如果比较的结果为0,会覆盖V oldValue = t.value;if (replaceOld || oldValue == null) {t.value = value;}return oldValue;}} while (t != null);}//就会把当前节点按照指定的规则进行添加addEntry(key, value, parent, cmp < 0);return null;} private void addEntry(K key, V value, Entry<K, V> parent, boolean addToLeft) {Entry<K,V> e = new Entry<>(key, value, parent);if (addToLeft)parent.left = e;elseparent.right = e;//添加完毕之后,需要按照红黑树的规则进行调整fixAfterInsertion(e);size++;modCount++;}private void fixAfterInsertion(Entry<K,V> x) {//因为红黑树的节点默认就是红色的x.color = RED;//按照红黑规则进行调整//parentOf:获取x的父节点//parentOf(parentOf(x)):获取x的爷爷节点//leftOf:获取左子节点while (x != null && x != root && x.parent.color == RED) {//判断当前节点的父节点是爷爷节点的左子节点还是右子节点//目的:为了获取当前节点的叔叔节点if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {//表示当前节点的父节点是爷爷节点的左子节点//那么下面就可以用rightOf获取到当前节点的叔叔节点Entry<K,V> y = rightOf(parentOf(parentOf(x)));if (colorOf(y) == RED) {//叔叔节点为红色的处理方案//把父节点设置为黑色setColor(parentOf(x), BLACK);//把叔叔节点设置为黑色setColor(y, BLACK);//把爷爷节点设置为红色setColor(parentOf(parentOf(x)), RED);//把爷爷节点设置为当前节点x = parentOf(parentOf(x));} else {//叔叔节点为黑色的处理方案//表示判断当前节点是否为父节点的右子节点if (x == rightOf(parentOf(x))) {//表示当前节点是父节点的右子节点x = parentOf(x);//左旋rotateLeft(x);}setColor(parentOf(x), BLACK);setColor(parentOf(parentOf(x)), RED);rotateRight(parentOf(parentOf(x)));}} else {//表示当前节点的父节点是爷爷节点的右子节点//那么下面就可以用leftOf获取到当前节点的叔叔节点Entry<K,V> y = leftOf(parentOf(parentOf(x)));if (colorOf(y) == RED) {setColor(parentOf(x), BLACK);setColor(y, BLACK);setColor(parentOf(parentOf(x)), RED);x = parentOf(parentOf(x));} else {if (x == leftOf(parentOf(x))) {x = parentOf(x);rotateRight(x);}setColor(parentOf(x), BLACK);setColor(parentOf(parentOf(x)), RED);rotateLeft(parentOf(parentOf(x)));}}}//把根节点设置为黑色root.color = BLACK;} -
课堂思考问题:
- TreeMap添加元素的时候,键是否需要重写hashCode和equals方法?
此时是不需要重写的。
- HashMap是哈希表结构的,JDK8开始由数组,链表,红黑树组成的。
既然有红黑树,HashMap的键是否需要实现Compareable接口或者传递比较器对象呢?
不需要的。
因为在HashMap的底层,默认是利用哈希值的大小关系来创建红黑树的- TreeMap和HashMap谁的效率更高?
如果是最坏情况,添加了8个元素,这8个元素形成了链表,此时TreeMap的效率要更高
但是这种情况出现的几率非常的少。
一般而言,还是HashMap的效率要更高。- 你觉得在Map集合中,java会提供一个如果键重复了,不会覆盖的put方法呢?
此时putIfAbsent本身不重要。
传递一个思想:
代码中的逻辑都有两面性,如果我们只知道了其中的A面,而且代码中还发现了有变量可以控制两面性的发生。
那么该逻辑一定会有B面。习惯:boolean类型的变量控制,一般只有AB两面,因为boolean只有两个值int类型的变量控制,一般至少有三面,因为int可以取多个值。- 三种双列集合,以后如何选择?
HashMap LinkedHashMap TreeMap
默认:HashMap(效率最高)
如果要保证存取有序:LinkedHashMap
如果要进行排序:TreeMap




![[每周一更]-(第86期):PostgreSQL入门学习和对比MySQL](https://img-blog.csdnimg.cn/direct/7661cf42fd9a48d59e2bbc14e1d257f5.jpeg#pic_center)