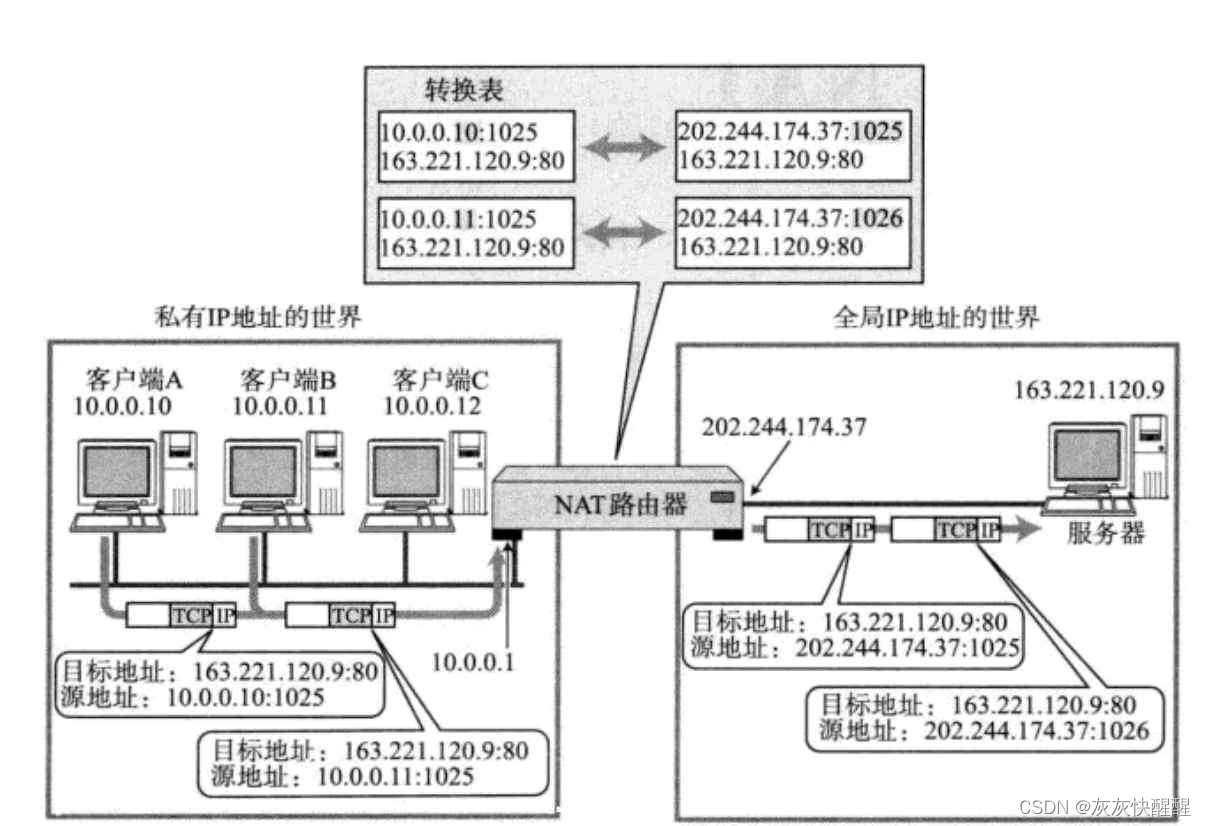
哨兵模式介绍
在深入理解Redis主从架构中Redis 的主从架构中,由于主从模式是读写分离的,如果主节点(master)挂了,那么将没有主节点来服务客户端的写操作请求,也没有主节点给从节点(slave)进行数据同步了。
在实际生产环境中,服务器难免会遇到一些突发状况:服务器宕机,停电,硬件损坏等等,一旦发生,后果不堪设想。 Redis 在 2.8 版本以后提供的哨兵(Sentinel)机制,它的作用是实现主从节点故障转移。它会监测主节点是否存活,如果发现主节点挂了,它就会选举一个从节点切换为主节点,并且把新主节点的相关信息通知给从节点和客户端。
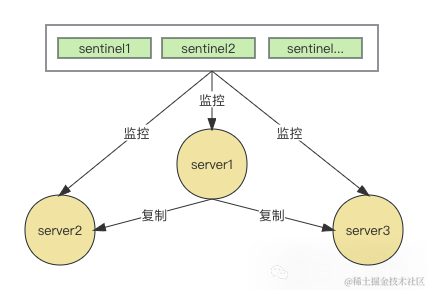
哨兵的能力包含如下几点:
-
监控: 持续监控 master 、slave 是否健康,是否处于预期工作状态。
-
主从动态切换: 当 Master 运行故障,哨兵启动自动故障恢复流程:从 slave 中选择一台作为新 master。
-
通知机制: 竞选出新的master之后,通知客户端与新 master 建立连接;slave 从新的 master 中 replicaof,保障主从数据的一致性。
哨兵集群原理
监控能力
哨模式启用的时候,会启动Sentinel的进程。sentinel进程会向所有的master 和 slave 以及其他sentinel进程 发送心跳包(1s一次),看看是否正常返回响应。
-
如果slave 没有在规定的时间内响应
sentinel的PING命令 ,sentinel会认为该实例已经挂了,将它tag为:下线状态; -
同理,如果master 没有在规定时间响应
sentinel的PING命令,也会被判定为 offline 状态,只是会多做一步 自动切换 master 的流程。
PING 命令的回复有两种情况:
-
有效回复:返回 +PONG、-LOADING、-MASTERDOWN 任何一种;
-
无效回复:有效回复之外的回复,或者指定时间内返回任何回复。
但是可能存在一些误判的情况,比如说网络拥塞、master实例假死、请求延迟,导致实例在某个短暂时间段不可用,后续又快速恢复了。
如果这时候被我们主动下线了,其实整个系统的可用性反而遭到了退化。而且 误判之后的一系列操作,master竞选、消息通知,slave 与新 master 同步数据,都会消耗大量资源。所以,误判要不得啊。
为了保证判断的可靠性,我们对下线的标识做了区分:一种是 主观下线,一种是客观下线。
-
主观下线: 哨兵利用
PING命令来监测master、slave实例节点的状态。如果是无效回复,哨兵就把这个实例节点标记为主观下线。如果是slave,一般是有多从概念,直接下线即可,但如果是master,就需要小心了。需要多个sentinel进投票裁决。哨兵机制采用多个实例组成sentinel集群模式进行部署,即哨兵集群。多个哨兵实例一起来判断,就可以避免单个哨兵因为自身网络状况不好,而误判主库下线的情况。 -
客观下线:
master是否要下线不是单个sentinel能够决定的,上面说了我们会有个sentinel集群,大家一起投票,超过一半的sentinel都判断了主观下线,这时候我们就把master标记为客观下线,认为它是真的不行了。
当 master 被判定为 客观下线 后,就算正式没有master了,当务之急就是赶紧竞选出一个新的master。 -
总结: 主观下线表示一个哨兵认为某个节点不可用,客观下线表示足够多的哨兵对某个节点的主观下线达成一致。只有在客观下线时,哨兵才会认定一个节点真正下线。
这里的「一定数量」是一个法定数量(Quorum),是由哨兵监控配置决定的,解释一下该配置:
# sentinel monitor <master-name> <master-host> <master-port> <quorum>
# 举例如下:
sentinel monitor mymaster 127.0.0.1 6379 2这条配置项用于告知哨兵需要监听的主节点:
-
sentinel monitor:代表监控。
-
mymaster:代表主节点的名称,可以自定义。
-
127.0.0.1:代表监控的主节点 ip,6379 代表端口。
-
2:法定数量,代表只有两个或两个以上的哨兵认为主节点不可用的时候,才会把 master 设置为客观下线状态,然后进行 failover 操作。
客观下线 的标准就是,当有 N 个哨兵实例时,要有 N/2 + 1 个实例判断 master 为 主观下线 ,才能最终判定 master 为 客观下线 ,其实就是过半机制。
主从动态切换
当master下线后,sentinel如何从多个slave中选举出一个新的master?这就需要通过 筛选 + 评估 方式进行选举了。
筛选
-
过滤掉不健康的(下线或者断线),没有回复哨兵ping响应的从节点。
-
过滤网路不好的节点:通过
down-after-milliseconds评估以往断连情况,如果一定周期内(如24h)从库和主库经常断连,而且超出了一定的阈值(如 10 次),则该slave不予考虑。
评估
筛选掉不健康的实例之后,我们就可以对于剩下健康的实例按顺序进行综合评估了。
-
slave 优先级,通过
slave-priority配置项(redis.conf),可以给不同的从库设置不同优先级,优先级高的优先成为master。 -
选择数据偏移量差距最小的,即
slave_repl_offset与master_repl_offset进度差距,其实就是比较 slave 与 原master 复制进度差距。 -
slave
runID,在优先级和复制进度都相同的情况下,选用runID最小的,runID越小说明创建时间越早,优先选为master。先来后到原则。
等这几个条件都评估完,我们就会选择出最适合slave,把他推举为新的master。
信息通知
等推选出最新的master之后,后续所有的写操作都会进入这个master中。所以需要尽快通知到所有的slave,让他们重新 replacaof 到 master上,重新建立runID和slave_repl_offset ,来保证数据的正常传输和主从一致性。
信息通知主要通过** Redis 的发布者/订阅者机制来实现的。每个哨兵节点提供发布者/订阅者机制,客户端可以从哨兵订阅消息。主从切换完成后,哨兵就会向 +switch-master 频道发布新主节点的 IP 地址和端口的消息,这个时候客户端就可以收到这条信息,然后用这里面的新主节点的 IP 地址和端口进行通信了**。
总结
哨兵模式的核心还是主从模式的演变,只不过相对于主从模式在主节点宕机导致不可写的情况下,多了探活,以及竞选机制:从所有的从节点竞选出新的主节点,然后自动切换。Redis 哨兵模式通过监控、协调和通知机制,使得 Redis 集群能够在主节点故障时自动完成切换,提高了 Redis 的高可用性。