word2vec从大量文本语料中以无监督方式学习语义知识,是用来生成词向量的工具
把文本分散嵌入到另一个离散空间,称作分布式表示,又称为词嵌入(word embedding)或词向量
Abstract
We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best performing techniques based on different types of neural networks. We observe large improvements in accuracy at much lower computational cost, i.e. it takes less than a day to learn high quality word vectors from a 1.6 billion words data set. Furthermore, we show that these vectors provide state-of-the-art performance on our test set for measuring syntactic and semantic word similarities.
翻译:
我们提出了两种新的模型架构,用于计算来自非常大的数据集的单词的连续向量表示。在单词相似度任务中测量这些表示的质量,并将结果与先前基于不同类型神经网络的最佳表现技术进行比较。我们观察到在更低的计算成本下,准确率有了很大的提高,即从16亿个单词数据集中学习高质量的单词向量只需要不到一天的时间。此外,我们展示了这些向量在我们的测试集上提供了最先进的性能,用于测量句法和语义单词相似度。
总结:
生成词向量又快又好
Introduction
Many current NLP systems and techniques treat words as atomic units - there is no notion of similarity between words, as these are represented as indices in a vocabulary. This choice has several good reasons - simplicity, robustness and the observation that simple models trained on huge amounts of data outperform complex systems trained on less data. An example is the popular N-gram model used for statistical language modeling - today, it is possible to train N-grams on virtually all available data (trillions of words [3]).
翻译:
许多当前的NLP系统和技术将单词视为原子单位——单词之间没有相似性的概念,因为它们在词汇表中被表示为索引。这种选择有几个很好的理由——简单性、健壮性,以及观察到在大量数据上训练的简单模型优于在较少数据上训练的复杂系统。一个例子是用于统计语言建模的流行N-gram模型——今天,可以在几乎所有可用的数据(数万亿个单词[3])上训练N-gram。
总结:
NLP 里面,最细粒度的是词语,词语组成句子,句子再组成段落、篇章、文档。所以处理 NLP 的问题,首先就要拿词语开刀
However, the simple techniques are at their limits in many tasks. For example, the amount of relevant in-domain data for automatic speech recognition is limited - the performance is usually dominated by the size of high quality transcribed speech data (often just millions of words). In machine translation, the existing corpora for many languages contain only a few billions of words or less. Thus, there are situations where simple scaling up of the basic techniques will not result in any significant progress, and we have to focus on more advanced techniques.
With progress of machine learning techniques in recent years, it has become possible to train more complex models on much larger data set, and they typically outperform the simple models. Probably the most successful concept is to use distributed representations of words [10]. For example, neural network based language models significantly outperform N-gram models [1, 27, 17].
翻译:
然而,这些简单的技术在许多任务中都有其局限性。例如,用于自动语音识别的相关域内数据的数量是有限的-性能通常由高质量转录语音数据的大小(通常只有数百万个单词)决定。在机器翻译中,许多语言的现有语料库仅包含几十亿或更少的单词。因此,在某些情况下,简单地扩大基本技术不会带来任何重大进展,我们必须专注于更高级的技术。
随着近年来机器学习技术的进步,在更大的数据集上训练更复杂的模型已经成为可能,并且它们通常优于简单模型。最成功的概念可能是使用单词的分布式表示[10]。例如,基于神经网络的语言模型显著优于N-gram模型[1,27,17]。
总结:
N-gram等模型无法处理更长程的context、没有考虑词与词之间内在的联系性;而基于神经网络的语言模型则有能力解决这些问题
Goals of the Paper
The main goal of this paper is to introduce techniques that can be used for learning high-quality word vectors from huge data sets with billions of words, and with millions of words in the vocabulary. As far as we know, none of the previously proposed architectures has been successfully trained on more than a few hundred of millions of words, with a modest dimensionality of the word vectors between 50 - 100.
翻译:
本文的主要目标是介绍可用于从具有数十亿单词和数百万单词的庞大数据集中学习高质量单词向量的技术。据我们所知,之前提出的架构都没有成功地训练过超过数亿个单词,并且单词向量的维数在50 - 100之间。
We use recently proposed techniques for measuring the quality of the resulting vector representations, with the expectation that not only will similar words tend to be close to each other, but that words can have multiple degrees of similarity [20]. This has been observed earlier in the context of inflectional languages - for example, nouns can have multiple word endings, and if we search for similar words in a subspace of the original vector space, it is possible to find words that have similar endings [13, 14].
Somewhat surprisingly, it was found that similarity of word representations goes beyond simple syntactic regularities. Using a word offset technique where simple algebraic operations are performed on the word vectors, it was shown for example that vector(”King”) - vector(”Man”) + vector(”Woman”) results in a vector that is closest to the vector representation of the word Queen [20].
翻译:
我们使用最近提出的技术来测量结果向量表示的质量,期望不仅相似的单词倾向于彼此接近,而且单词可以具有多个相似度[20]。这在前面的屈折语言环境中已经被观察到——例如,名词可以有多个单词结尾,如果我们在原始向量空间的子空间中搜索相似的单词,就有可能找到具有相似结尾的单词[13,14]。
有些令人惊讶的是,人们发现单词表示的相似性超越了简单的句法规律。使用单词偏移技术,在单词向量上执行简单的代数运算,结果显示,例如向量(“King”)-向量(“Man”)+向量(“Woman”)产生的向量最接近单词Queen的向量表示[20]。
总结:
在嵌入的离散空间中,词向量之间具有多个相似度;词向量之间存在算子系统,此处是语义近似匹配
In this paper, we try to maximize accuracy of these vector operations by developing new model architectures that preserve the linear regularities among words. We design a new comprehensive test set for measuring both syntactic and semantic regularities1 , and show that many such regularities can be learned with high accuracy. Moreover, we discuss how training time and accuracy depends on the dimensionality of the word vectors and on the amount of the training data.
翻译:
在本文中,我们试图通过开发新的模型架构来最大限度地提高这些向量操作的准确性,从而保持单词之间的线性规律。我们设计了一个新的综合测试集来测量语法和语义规则1,并表明许多这样的规则可以被高精度地学习。此外,我们还讨论了训练时间和准确性如何取决于词向量的维数和训练数据的数量。
Previous Work
Representation of words as continuous vectors has a long history [10, 26, 8]. A very popular model architecture for estimating neural network language model (NNLM) was proposed in [1], where a feedforward neural network with a linear projection layer and a non-linear hidden layer was used to learn jointly the word vector representation and a statistical language model. This work has been followed by many others.
Another interesting architecture of NNLM was presented in [13, 14], where the word vectors are first learned using neural network with a single hidden layer. The word vectors are then used to train the NNLM. Thus, the word vectors are learned even without constructing the full NNLM. In this work, we directly extend this architecture, and focus just on the first step where the word vectors are learned using a simple model.
It was later shown that the word vectors can be used to significantly improve and simplify many NLP applications [4, 5, 29]. Estimation of the word vectors itself was performed using different model architectures and trained on various corpora [4, 29, 23, 19, 9], and some of the resulting word vectors were made available for future research and comparison2 . However, as far as we know, these architectures were significantly more computationally expensive for training than the one proposed in [13], with the exception of certain version of log-bilinear model where diagonal weight matrices are used [23].
翻译:
将单词表示为连续向量已有很长的历史[10,26,8]。文献[1]提出了一种非常流行的神经网络语言模型(NNLM)估计模型体系结构,其中使用具有线性投影层和非线性隐藏层的前馈神经网络来联合学习词向量表示和统计语言模型。这项工作已经被许多人跟进。
NNLM的另一个有趣的架构在[13,14]中提出,其中首先使用具有单个隐藏层的神经网络学习单词向量。然后使用单词向量来训练NNLM。因此,即使不构建完整的NNLM,也可以学习单词向量。在这项工作中,我们直接扩展了这个架构,并只关注使用简单模型学习单词向量的第一步。
后来的研究表明,词向量可以用来显著改善和简化许多NLP应用[4,5,29]。使用不同的模型架构对词向量本身进行估计,并在不同的语料库上进行训练[4,29,23,19,9],并且一些结果词向量可用于未来的研究和比较2。然而,据我们所知,除了使用对角权矩阵的对数双线性模型的某些版本外,这些架构的训练计算成本明显高于[13]所提出的架构[23]。
总结:
word2vec从NNLM中简化训练而来:由于NNLM将前n-1个词在词汇表D中对应的词向量直接拼接作为神经网络的输入,导致训练起来就很耗时;词向量是NNLM的副产品
Model Architectures
Many different types of models were proposed for estimating continuous representations of words, including the well-known Latent Semantic Analysis (LSA) and Latent Dirichlet Allocation (LDA).In this paper, we focus on distributed representations of words learned by neural networks, as it was previously shown that they perform significantly better than LSA for preserving linear regularities among words [20, 31]; LDA moreover becomes computationally very expensive on large data sets.
Similar to [18], to compare different model architectures we define first the computational complexity of a model as the number of parameters that need to be accessed to fully train the model. Next, we will try to maximize the accuracy, while minimizing the computational complexity.
翻译:
人们提出了许多不同类型的模型来估计单词的连续表示,包括众所周知的潜在语义分析(LSA)和潜在狄利克雷分配(LDA)。在本文中,我们关注神经网络学习的词的分布式表示,因为之前的研究表明,它们在保持词之间的线性规律方面表现得比LSA好得多[20,31];此外,LDA在处理大型数据集时在计算上变得非常昂贵。
与[18]类似,为了比较不同的模型架构,我们首先将模型的计算复杂度定义为完全训练模型所需访问的参数的数量。接下来,我们将尝试最大化准确性,同时最小化计算复杂度。
For all the following models, the training complexity is proportional to
O = E × T × Q;
where E is number of the training epochs, T is the number of the words in the training set and Q is defined further for each model architecture. Common choice is E = 3 − 50 and T up to one billion.All models are trained using stochastic gradient descent and backpropagation [26].
翻译:
对于以下所有模型,训练复杂度为
O = E × T × Q;
其中E为训练epoch的个数,T为训练集中的单词个数,Q为每个模型架构进一步定义。通常的选择是E = 3 - 50, T可达十亿。所有模型都使用随机梯度下降和反向传播进行训练[26]。
Feedforward Neural Net Language Model (NNLM)
The probabilistic feedforward neural network language model has been proposed in [1]. It consists of input, projection, hidden and output layers. At the input layer, N previous words are encoded using 1-of-V coding, where V is size of the vocabulary. The input layer is then projected to a projection layer P that has dimensionality N × D, using a shared projection matrix. As only N inputs are active at any given time, composition of the projection layer is a relatively cheap operation.
翻译:
概率前馈神经网络语言模型已在文献[1]中提出。它由输入层、投影层、隐藏层和输出层组成。在输入层,使用1-of-V编码对之前的N个单词进行编码,其中V是词汇表的大小。然后使用共享投影矩阵将输入层投影到维度为N × D的投影层P。由于在任何给定时间只有N个输入是活动的,因此组合投影层是一个相对便宜的操作。
The NNLM architecture becomes complex for computation between the projection and the hidden layer, as values in the projection layer are dense. For a common choice of N = 10, the size of the projection layer (P) might be 500 to 2000, while the hidden layer size H is typically 500 to 1000 units. Moreover, the hidden layer is used to compute probability distribution over all the words in the vocabulary, resulting in an output layer with dimensionality V . Thus, the computational complexity per each training example is
Q = N × D + N × D × H + H × V;
where the dominating term is H × V . However, several practical solutions were proposed for avoiding it; either using hierarchical versions of the softmax [25, 23, 18], or avoiding normalized models completely by using models that are not normalized during training [4, 9]. With binary tree representations of the vocabulary, the number of output units that need to be evaluated can go down to around log2(V ). Thus, most of the complexity is caused by the term N × D × H.
翻译:
由于投影层中的值是密集的,因此NNLM体系结构在投影层和隐藏层之间的计算变得复杂。对于N = 10的常见选择,投影层(P)的大小可能是500到2000个单位,而隐藏层大小H通常是500到1000个单位。此外,隐藏层用于计算词汇表中所有单词的概率分布,从而得到维数为V的输出层。因此,每个训练样例的计算复杂度为
Q = N × D + N × D × H + H × V;
其中主导项为H × V。然而,提出了一些实际的解决办法来避免这种情况;要么使用分层版本的softmax[25,23,18],要么使用在训练过程中未归一化的模型来完全避免归一化模型[4,9]。使用词汇表的二叉树表示,需要评估的输出单元的数量可以减少到log2(V)左右。因此,大多数复杂性是由N × D × H引起的。
In our models, we use hierarchical softmax where the vocabulary is represented as a Huffman binary tree. This follows previous observations that the frequency of words works well for obtaining classes in neural net language models [16]. Huffman trees assign short binary codes to frequent words, and this further reduces the number of output units that need to be evaluated: while balanced binary tree would require log2(V ) outputs to be evaluated, the Huffman tree based hierarchical softmax requires only about log2(Unigram perplexity(V )). For example when the vocabulary size is one million words, this results in about two times speedup in evaluation. While this is not crucial speedup for neural network LMs as the computational bottleneck is in the N ×D×H term, we will later propose architectures that do not have hidden layers and thus depend heavily on the efficiency of the softmax normalization.
翻译:
在我们的模型中,我们使用分层softmax,其中词汇表被表示为霍夫曼二叉树。这遵循了先前的观察,即单词的频率在神经网络语言模型中很好地用于获取类[16]。霍夫曼树将短二进制代码分配给频繁的单词,这进一步减少了需要评估的输出单元的数量:平衡二叉树需要评估log2(V)个输出,而基于霍夫曼树的分层softmax只需要大约log2(Unigram perplexity(V))。例如,当词汇量为100万个单词时,这将导致评估速度提高两倍左右。虽然这对于神经网络LMs来说并不是至关重要的加速,因为计算瓶颈在N ×D×H项中,但我们稍后将提出没有隐藏层的架构,因此严重依赖于softmax归一化的效率。
总结:
用Huffman树来压缩词汇表并为频繁出现的单词分配短的二进制编码。假定往左走为负设为1,往右走为正设为0,利用sigmoid计算结点被分为正(负)类的概率,将每个分支看做一次二分类,每一次二分类就产生一个概率,将这些概率乘起来,就是所要求的p(w|context(w))
模型会赋予这些抽象的中间节点一个合适的向量,这个向量代表了它对应的所有子节点。因为真正的单词公用了这些抽象节点的向量,所以Hierarchical Softmax方法和原始问题并不是等价的,但是这种近似并不会带来效果上的显著损失,同时又使得模型的求解规模显著上升
Huffman编码相当于做了一定的聚类,且越高频的计算量越少
减少输出单元数量和使用分层softmax,大量减少了softmax归一化计算的复杂度
Recurrent Neural Net Language Model (RNNLM)
Recurrent neural network based language model has been proposed to overcome certain limitations of the feedforward NNLM, such as the need to specify the context length (the order of the model N), and because theoretically RNNs can efficiently represent more complex patterns than the shallow neural networks [15, 2]. The RNN model does not have a projection layer; only input, hidden and output layer. What is special for this type of model is the recurrent matrix that connects hidden layer to itself, using time-delayed connections. This allows the recurrent model to form some kind of short term memory, as information from the past can be represented by the hidden layer state that gets updated based on the current input and the state of the hidden layer in the previous time step.
The complexity per training example of the RNN model is
Q = H × H + H × V
where the word representations D have the same dimensionality as the hidden layer H. Again, the term H × V can be efficiently reduced to H × log2(V ) by using hierarchical softmax. Most of the complexity then comes from H × H.
翻译:
基于递归神经网络的语言模型已经被提出,以克服前馈NNLM的某些局限性,例如需要指定上下文长度(模型N的阶数),并且因为理论上rnn可以有效地表示比浅神经网络更复杂的模式[15,2]。RNN模型没有投影层;只有输入层、隐藏层和输出层。这种模型的特殊之处在于循环矩阵使用延时连接将隐藏层与自身连接起来。这允许循环模型形成某种短期记忆,因为来自过去的信息可以由隐藏层状态表示,该状态根据当前输入和前一个时间步长的隐藏层状态进行更新。RNN模型的每个训练样例的复杂度为
Q = H × H + H × V
其中单词表示D与隐藏层H具有相同的维数。同样,通过使用分层softmax,术语H × V可以有效地简化为H × log2(V)。大部分的复杂性来自于H × H。
总结:
RNN引入上下文信息,并将Embedding层与RNN里的隐藏层合并,从而解决了变长序列的问题
Parallel Training of Neural Networks
To train models on huge data sets, we have implemented several models on top of a large-scale distributed framework called DistBelief [6], including the feedforward NNLM and the new models proposed in this paper. The framework allows us to run multiple replicas of the same model in parallel, and each replica synchronizes its gradient updates through a centralized server that keeps all the parameters. For this parallel training, we use mini-batch asynchronous gradient descent with an adaptive learning rate procedure called Adagrad [7]. Under this framework, it is common to use one hundred or more model replicas, each using many CPU cores at different machines in a data center.
翻译:
为了在庞大的数据集上训练模型,我们在一个名为DistBelief的大规模分布式框架上实现了几个模型[6],包括前馈NNLM和本文提出的新模型。该框架允许我们并行运行同一模型的多个副本,每个副本通过保存所有参数的集中式服务器同步其梯度更新。对于这种并行训练,我们使用小批量异步梯度下降和自适应学习率过程,称为Adagrad[7]。在此框架下,通常使用100个或更多模型副本,每个模型副本在数据中心的不同机器上使用许多CPU内核
New Log-linear Models
In this section, we propose two new model architectures for learning distributed representations of words that try to minimize computational complexity. The main observation from the previous section was that most of the complexity is caused by the non-linear hidden layer in the model. While this is what makes neural networks so attractive, we decided to explore simpler models that might not be able to represent the data as precisely as neural networks, but can possibly be trained on much more data efficiently.
The new architectures directly follow those proposed in our earlier work [13, 14], where it was found that neural network language model can be successfully trained in two steps: first, continuous word vectors are learned using simple model, and then the N-gram NNLM is trained on top of these distributed representations of words. While there has been later substantial amount of work that focuses on learning word vectors, we consider the approach proposed in [13] to be the simplest one.Note that related models have been proposed also much earlier [26, 8].
翻译:
在本节中,我们提出了两种新的模型架构,用于学习分布式单词表示,以尽量减少计算复杂性。上一节的主要观察结果是,大多数复杂性是由模型中的非线性隐藏层引起的。虽然这是神经网络如此吸引人的原因,但我们决定探索更简单的模型,这些模型可能无法像神经网络那样精确地表示数据,但可能可以更有效地训练更多的数据。
新的架构直接遵循了我们在早期工作中提出的[13,14],其中发现神经网络语言模型可以通过两步成功训练:首先,使用简单模型学习连续词向量,然后在这些分布式词表示的基础上训练N-gram NNLM。虽然后来有大量的工作集中在学习词向量上,但我们认为[13]中提出的方法是最简单的方法。值得注意的是,相关模型也在更早的时候被提出[26,8]。
Continuous Bag-of-Words Model
The first proposed architecture is similar to the feedforward NNLM, where the non-linear hidden layer is removed and the projection layer is shared for all words (not just the projection matrix); thus, all words get projected into the same position (their vectors are averaged). We call this architecture a bag-of-words model as the order of words in the history does not influence the projection.Furthermore, we also use words from the future; we have obtained the best performance on the task introduced in the next section by building a log-linear classifier with four future and four history words at the input, where the training criterion is to correctly classify the current (middle) word.
Training complexity is then
Q = N × D + D × log2(V)
We denote this model further as CBOW, as unlike standard bag-of-words model, it uses continuous distributed representation of the context. The model architecture is shown at Figure 1. Note that the weight matrix between the input and the projection layer is shared for all word positions in the same way as in the NNLM.
翻译:
第一个提出的架构类似于前馈NNLM,其中非线性隐藏层被删除,所有单词共享投影层(不仅仅是投影矩阵);因此,所有单词都被投射到相同的位置(它们的向量被平均)。我们称这种结构为词袋模型,因为历史上的词的顺序不影响投影。此外,我们也使用来自未来的词汇;通过在输入处构建一个具有四个未来词和四个历史词的对数线性分类器,我们在下一节中介绍的任务中获得了最佳性能,其中训练标准是正确分类当前(中间)词。
训练的复杂度是Q = N × D + D × log2(V)
我们将此模型进一步表示为CBOW,因为与标准的词袋模型不同,它使用上下文的连续分布式表示。模型体系结构如图1所示。请注意,输入层和投影层之间的权重矩阵对于所有单词位置都是共享的,与NNLM中的方式相同。
总结:
去掉了最耗时的非线性隐层且所有词共享隐层,从输入层到隐层所进行的操作实际上就是上下文向量的加和
看左右两边来预测中间
CBOW有两种可选的算法: Hierarchical Softmax和Negative Sampling:
1.Hierarchical Softmax结合了Huffman编码,每个词w都可以从树的根节点沿着唯一一条路径被访问到
2.Negative Sampling在源代码中随机生成negative个负例,原来的word为正例,标签为1,其他随机生成的标签为0;隐层为输入层各变量的加和,因此输入层的梯度即为隐层梯度

Continuous Skip-gram Model
The second architecture is similar to CBOW, but instead of predicting the current word based on the context, it tries to maximize classification of a word based on another word in the same sentence.More precisely, we use each current word as an input to a log-linear classifier with continuous projection layer, and predict words within a certain range before and after the current word. We found that increasing the range improves quality of the resulting word vectors, but it also increases the computational complexity. Since the more distant words are usually less related to the current word than those close to it, we give less weight to the distant words by sampling less from those words in our training examples.
The training complexity of this architecture is proportional to
Q = C × (D + D × log2(V ));
where C is the maximum distance of the words. Thus, if we choose C = 5, for each training word we will select randomly a number R in range < 1; C >, and then use R words from history and R words from the future of the current word as correct labels. This will require us to do R × 2 word classifications, with the current word as input, and each of the R + R words as output. In the following experiments, we use C = 10.
翻译:
第二个体系结构类似于CBOW,但它不是根据上下文预测当前单词,而是尝试根据同一句子中的另一个单词最大限度地对单词进行分类。更准确地说,我们将每个当前单词作为具有连续投影层的对数线性分类器的输入,并在当前单词之前和之后的一定范围内预测单词。我们发现增加范围提高了结果词向量的质量,但也增加了计算复杂度。由于距离较远的单词与当前单词的相关性通常低于与其相近的单词,因此我们通过在训练示例中减少对这些单词的采样来减少对距离较远的单词的权重。
该体系结构的训练复杂度正比于Q = C × (D + D × log2(V))
式中,C为单词的最大距离。因此,如果我们选择C = 5,对于每个训练词,我们将R随机赋值在< 1;C >中,然后使用R个历史单词和R个当前单词的未来单词作为正确的标签。这将需要我们进行R × 2个单词分类,当前单词作为输入,每个R + R单词作为输出。在接下来的实验中,我们使用C = 10。
总结:
Skip-gram模型中的词语指示方向正好与CBOW反,Skip-gram应该预测概率p (wi|wt),尝试根据同一句子中的另一个单词最大限度地对单词进行分类。其中t-c<i<t+c且i≠t,c是决定上下文窗口大小的常数
Skip-gram是一种对称的模型。如果以wt为中心词,wk在其窗口内,那么wt也必然在以wk为中心词的同样大小的窗口内
Skip-gram中的每个词向量都表征了上下文的分布。skip-gram中的skip是指在一定窗口内的词两两都会计算概率,即使它们之间隔着一些词,比如“白色汽车”和“白色的汽车”很容易被识别为相同的短语
Results
To compare the quality of different versions of word vectors, previous papers typically use a table showing example words and their most similar words, and understand them intuitively. Although it is easy to show that word France is similar to Italy and perhaps some other countries, it is much more challenging when subjecting those vectors in a more complex similarity task, as follows. We follow previous observation that there can be many different types of similarities between words, for example, word big is similar to bigger in the same sense that small is similar to smaller. Example of another type of relationship can be word pairs big - biggest and small - smallest [20]. We further denote two pairs of words with the same relationship as a question, as we can ask: ”What is the word that is similar to small in the same sense as biggest is similar to big?”
Somewhat surprisingly, these questions can be answered by performing simple algebraic operations with the vector representation of words. To find a word that is similar to small in the same sense as biggest is similar to big, we can simply compute vector X = vector("biggest")−vector("big") + vector("small"). Then, we search in the vector space for the word closest to X measured by cosine distance, and use it as the answer to the question (we discard the input question words during this search). When the word vectors are well trained, it is possible to find the correct answer (word smallest) using this method.
Finally, we found that when we train high dimensional word vectors on a large amount of data, the resulting vectors can be used to answer very subtle semantic relationships between words, such as a city and the country it belongs to, e.g. France is to Paris as Germany is to Berlin. Word vectors with such semantic relationships could be used to improve many existing NLP applications, such as machine translation, information retrieval and question answering systems, and may enable other future applications yet to be invented.
翻译:
为了比较不同版本的词向量的质量,以前的论文通常使用一个表来显示示例词和它们最相似的词,并直观地理解它们。虽然很容易显示单词法国与意大利和其他一些国家相似,但是当将这些向量置于更复杂的相似性任务中时,难度要大得多,如下所示。我们遵循之前的观察,即单词之间可能有许多不同类型的相似性,例如,单词big与bigger相似,而单词small与较小相似。另一种类型的关系可以是单词对大-最大和小-最小[20]。我们进一步表示具有相同关系的两对单词作为一个问题,因为我们可以问:“哪个单词在相同意义上与small相似,就像最大与大相似一样?”
有些令人惊讶的是,这些问题可以通过对单词的向量表示执行简单的代数运算来回答。要找到一个与small相似的单词,就像最大与big相似一样,我们可以简单地计算vector X = vector(“最大”) - vector(“大”)+ vector(“小”)。然后,我们在向量空间中搜索通过余弦距离测量的最接近X的单词,并将其用作问题的答案(在此搜索期间我们丢弃输入的问题单词)。当单词向量训练得很好时,使用这种方法可以找到正确的答案(单词最小)。
最后,我们发现,当我们在大量数据上训练高维词向量时,得到的向量可以用来回答词之间非常微妙的语义关系,比如一个城市和它所属的国家,例如法国和巴黎之间的关系,德国和柏林之间的关系。具有这种语义关系的词向量可以用来改进许多现有的NLP应用,如机器翻译、信息检索和问答系统,并可能使其他未来的应用得以发明。
总结:
word2vec的算子系统比其他技术的要强,也就意味着学到的词语直接的语义联系更紧密
Task Description
To measure quality of the word vectors, we define a comprehensive test set that contains five types of semantic questions, and nine types of syntactic questions. Two examples from each category are shown in Table 1. Overall, there are 8869 semantic and 10675 syntactic questions. The questions in each category were created in two steps: first, a list of similar word pairs was created manually.
Then, a large list of questions is formed by connecting two word pairs. For example, we made a list of 68 large American cities and the states they belong to, and formed about 2.5K questions by picking two word pairs at random. We have included in our test set only single token words, thus multi-word entities are not present (such as New York).
We evaluate the overall accuracy for all question types, and for each question type separately (semantic, syntactic). Question is assumed to be correctly answered only if the closest word to the vector computed using the above method is exactly the same as the correct word in the question; synonyms are thus counted as mistakes. This also means that reaching 100% accuracy is likely to be impossible, as the current models do not have any input information about word morphology.
However, we believe that usefulness of the word vectors for certain applications should be positively correlated with this accuracy metric. Further progress can be achieved by incorporating information about structure of words, especially for the syntactic questions.
翻译:
为了测量词向量的质量,我们定义了一个包含五种语义问题和九种句法问题的综合测试集。表1显示了每个类别中的两个示例。总共有8869个语义题和10675个句法题。每个类别中的问题分两步创建:首先,手动创建一个相似单词对列表。
然后,通过连接两个词对形成一个大的问题列表。例如,我们列出了美国68个大城市及其所属的州,通过随机选择两个单词对,形成了大约2.5万个问题。我们在测试集中只包含了单个令牌词,因此不存在多词实体(例如New York)。
我们评估了所有问题类型的总体准确性,并分别评估了每种问题类型(语义、句法)。只有当使用上述方法计算出的最接近向量的单词与问题中的正确单词完全相同时,才认为问题得到了正确答案;同义词因此被视为错误。这也意味着达到100%的准确率可能是不可能的,因为目前的模型没有任何关于单词形态学的输入信息。
然而,我们认为,在某些应用中,词向量的有用性应该与这个精度度量呈正相关。进一步的进步可以通过结合词的结构信息来实现,特别是在句法问题上。
总结:
用单词之间的相似度测量词向量的质量
Maximization of Accuracy
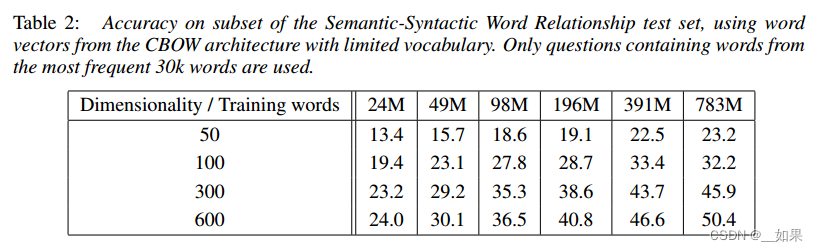
We have used a Google News corpus for training the word vectors. This corpus contains about 6B tokens. We have restricted the vocabulary size to 1 million most frequent words. Clearly, we are facing time constrained optimization problem, as it can be expected that both using more data and higher dimensional word vectors will improve the accuracy. To estimate the best choice of model architecture for obtaining as good as possible results quickly, we have first evaluated models trained on subsets of the training data, with vocabulary restricted to the most frequent 30k words.
The results using the CBOW architecture with different choice of word vector dimensionality and increasing amount of the training data are shown in Table 2.
It can be seen that after some point, adding more dimensions or adding more training data provides diminishing improvements. So, we have to increase both vector dimensionality and the amount of the training data together. While this observation might seem trivial, it must be noted that it is currently popular to train word vectors on relatively large amounts of data, but with insufficient size(such as 50 - 100). Given Equation 4, increasing amount of training data twice results in about the same increase of computational complexity as increasing vector size twice.
For the experiments reported in Tables 2 and 4, we used three training epochs with stochastic gradient descent and backpropagation. We chose starting learning rate 0.025 and decreased it linearly, so that it approaches zero at the end of the last training epoch.
翻译:
我们使用谷歌新闻语料库来训练词向量。这个语料库包含大约6B个token。我们将词汇量限制在100万个最常用的单词。显然,我们面临着时间约束的优化问题,因为可以预期,使用更多的数据和更高维度的词向量将提高准确性。为了评估模型架构的最佳选择,以便快速获得尽可能好的结果,我们首先评估了在训练数据子集上训练的模型,词汇表限制为最常见的30k个单词。
使用不同词向量维数选择和增加训练数据量的CBOW架构的结果如表2所示。
可以看出,在某个点之后,添加更多的维度或添加更多的训练数据提供的改进是递减的。因此,我们必须同时增加向量维数和训练数据量。虽然这个观察可能看起来微不足道,但必须注意的是,目前流行的是在相对大量的数据上训练词向量,但规模不足(例如50 - 100)。根据公式4,训练数据量增加两倍导致的计算复杂度增加与向量大小增加两倍大致相同。
对于表2和表4中报告的实验,我们使用了随机梯度下降和反向传播的三个训练时期。我们选择起始学习率为0.025,并将其线性减小,使其在最后一个训练历元结束时趋近于零。
总结:
必须同时增加向量维数和训练数据量,但也会带来计算复杂度的激增
Comparison of Model Architectures
First we compare different model architectures for deriving the word vectors using the same training data and using the same dimensionality of 640 of the word vectors. In the further experiments, we use full set of questions in the new Semantic-Syntactic Word Relationship test set, i.e. unrestricted to the 30k vocabulary. We also include results on a test set introduced in [20] that focuses on syntactic similarity between words3 .
The training data consists of several LDC corpora and is described in detail in [18] (320M words, 82K vocabulary). We used these data to provide a comparison to a previously trained recurrent neural network language model that took about 8 weeks to train on a single CPU. We trained a feedforward NNLM with the same number of 640 hidden units using the DistBelief parallel training [6], using a history of 8 previous words (thus, the NNLM has more parameters than the RNNLM, as the projection layer has size 640 × 8).
In Table 3, it can be seen that the word vectors from the RNN (as used in [20]) perform well mostly on the syntactic questions. The NNLM vectors perform significantly better than the RNN - this is not surprising, as the word vectors in the RNNLM are directly connected to a non-linear hidden layer. The CBOW architecture works better than the NNLM on the syntactic tasks, and about the same on the semantic one. Finally, the Skip-gram architecture works slightly worse on the syntactic task than the CBOW model (but still better than the NNLM), and much better on the semantic part of the test than all the other models.
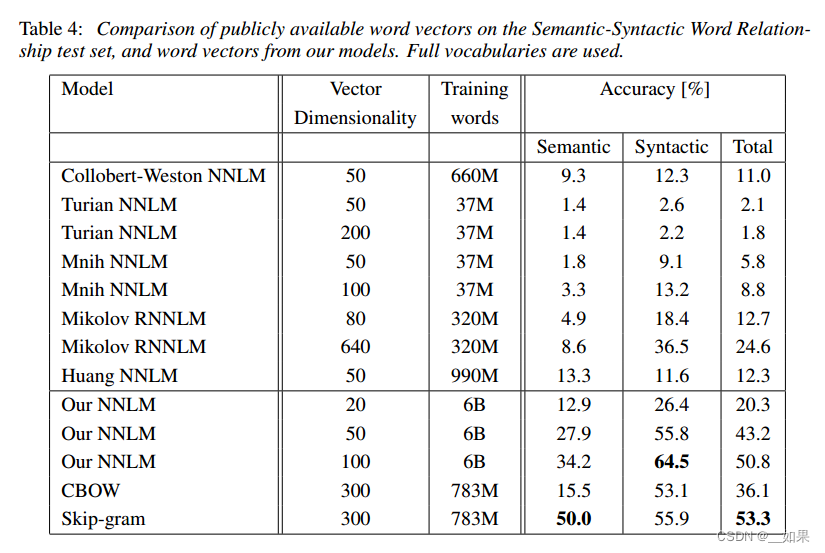
Next, we evaluated our models trained using one CPU only and compared the results against publicly available word vectors. The comparison is given in Table 4. The CBOW model was trained on subset of the Google News data in about a day, while training time for the Skip-gram model was about three days.
For experiments reported further, we used just one training epoch (again, we decrease the learning rate linearly so that it approaches zero at the end of training). Training a model on twice as much data using one epoch gives comparable or better results than iterating over the same data for three epochs, as is shown in Table 5, and provides additional small speedup.
翻译:
首先,我们比较了不同的模型架构,使用相同的训练数据和相同的640维数的词向量来推导词向量。在进一步的实验中,我们在新的语义-句法词关系测试集中使用全套问题,即不受30k词汇的限制。我们还包括了[20]中引入的一个测试集的结果,该测试集主要关注单词之间的句法相似性3。
训练数据由多个LDC语料库组成,详细描述见[18](320M words, 82K vocabulary)。我们使用这些数据与之前训练的循环神经网络语言模型进行比较,该模型在单个CPU上训练了大约8周。我们使用DistBelief并行训练[6]训练了一个具有相同数量的640个隐藏单元的前馈NNLM,使用8个以前的单词的历史(因此,NNLM比RNNLM具有更多的参数,因为投影层的大小为640 × 8)。
从表3中可以看出,来自RNN(如[20]中使用的)的词向量主要在句法问题上表现良好。NNLM向量的表现明显优于RNN——这并不奇怪,因为RNNLM中的单词向量直接连接到非线性隐藏层。CBOW体系结构在句法任务上优于NNLM,在语义任务上也基本相同。最后,Skip-gram架构在语法任务上的表现比CBOW模型略差(但仍然比NNLM好),在测试的语义部分上比所有其他模型都要好得多。
接下来,我们评估仅使用一个CPU训练的模型,并将结果与公开可用的词向量进行比较。对比如表4所示。CBOW模型在Google News数据子集上的训练时间约为一天,而Skip-gram模型的训练时间约为三天。
对于进一步报道的实验,我们只使用了一个训练历元(同样,我们线性降低学习率,以便在训练结束时接近零)。使用一个epoch对两倍数据量的模型进行训练,得到的结果与使用三个epoch对相同数据进行迭代的结果相当,甚至更好,如表5所示,并且提供了额外的小加速。

Microsoft Research Sentence Completion Challenge
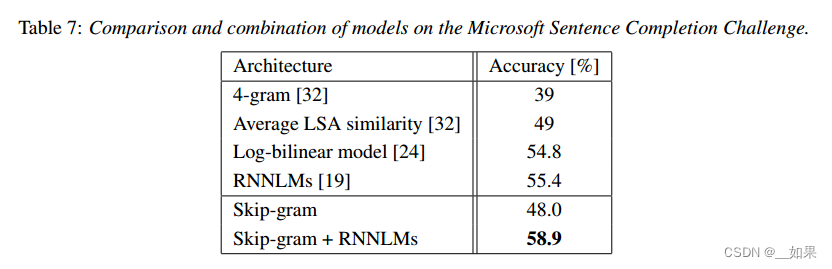
The Microsoft Sentence Completion Challenge has been recently introduced as a task for advancing language modeling and other NLP techniques [32]. This task consists of 1040 sentences, where one word is missing in each sentence and the goal is to select word that is the most coherent with the rest of the sentence, given a list of five reasonable choices. Performance of several techniques has been already reported on this set, including N-gram models, LSA-based model [32], log-bilinear model [24] and a combination of recurrent neural networks that currently holds the state of the art performance of 55.4% accuracy on this benchmark [19].
We have explored the performance of Skip-gram architecture on this task. First, we train the 640dimensional model on 50M words provided in [32]. Then, we compute score of each sentence in the test set by using the unknown word at the input, and predict all surrounding words in a sentence.
The final sentence score is then the sum of these individual predictions. Using the sentence scores, we choose the most likely sentence.
A short summary of some previous results together with the new results is presented in Table 7.
While the Skip-gram model itself does not perform on this task better than LSA similarity, the scores from this model are complementary to scores obtained with RNNLMs, and a weighted combination leads to a new state of the art result 58.9% accuracy (59.2% on the development part of the set and 58.7% on the test part of the set).
翻译:
微软句子完成挑战最近被引入,作为推进语言建模和其他自然语言处理技术的任务[32]。这个任务由1040个句子组成,每个句子中缺少一个单词,目标是在给出五个合理选择的列表中选择与句子其余部分最连贯的单词。几种技术的性能已经在这个集合上得到了报道,包括N-gram模型、基于lsa的模型[32]、对数双线性模型[24]和递归神经网络的组合,目前在这个基准上的准确率达到了55.4%[19]。
我们已经探索了Skip-gram架构在这个任务上的性能。首先,我们在[32]中提供的50M个单词上训练640维模型。然后,我们使用未知单词作为输入,计算测试集中每个句子的分数,并预测句子中所有周围的单词。
最后的句子得分是这些个体预测的总和。根据句子得分,我们选择最有可能的句子。
表7简要总结了一些以前的结果和新的结果。
虽然Skip-gram模型本身在这项任务上的表现并不比LSA相似度好,但该模型的分数与rnnlm获得的分数是互补的,加权组合导致新的最新技术结果58.9%的准确率(集的开发部分为59.2%,集的测试部分为58.7%)。
Examples of the Learned Relationships
Table 8 shows words that follow various relationships. We follow the approach described above: the relationship is defined by subtracting two word vectors, and the result is added to another word. Thus for example, Paris - France + Italy = Rome. As it can be seen, accuracy is quite good, although there is clearly a lot of room for further improvements (note that using our accuracy metric that assumes exact match, the results in Table 8 would score only about 60%). We believe that word vectors trained on even larger data sets with larger dimensionality will perform significantly better, and will enable the development of new innovative applications. Another way to improve accuracy is to provide more than one example of the relationship. By using ten examples instead of one to form the relationship vector (we average the individual vectors together), we have observed improvement of accuracy of our best models by about 10% absolutely on the semantic-syntactic test.
It is also possible to apply the vector operations to solve different tasks. For example, we have observed good accuracy for selecting out-of-the-list words, by computing average vector for a list of words, and finding the most distant word vector. This is a popular type of problems in certain human intelligence tests. Clearly, there is still a lot of discoveries to be made using these techniques.
翻译:
表8显示了遵循各种关系的单词。我们遵循上面描述的方法:通过减去两个词向量来定义关系,并将结果添加到另一个词中。例如,巴黎-法国+意大利=罗马。可以看到,准确性非常好,尽管显然还有很多进一步改进的空间(注意,使用我们的准确度度量假设完全匹配,表8中的结果只能得到大约60%的分数)。我们相信,在更大的数据集和更大的维度上训练的词向量将表现得更好,并将使新的创新应用程序的开发成为可能。另一种提高准确性的方法是提供多个关系示例。通过使用10个例子而不是一个例子来形成关系向量(我们将单个向量平均在一起),我们观察到在语义-句法测试中,我们的最佳模型的准确性提高了大约10%。
也可以应用向量运算来解决不同的任务。例如,我们观察到,通过计算单词列表的平均向量,并找到距离最远的单词向量,可以很好地选择列表外的单词。这是某些人类智力测试中常见的一类问题。显然,使用这些技术仍有许多发现有待发现。
总结:
多给一些单词关系的实例可以增强算子系统的能力
Conclusion
In this paper we studied the quality of vector representations of words derived by various models on a collection of syntactic and semantic language tasks. We observed that it is possible to train high quality word vectors using very simple model architectures, compared to the popular neural network models (both feedforward and recurrent). Because of the much lower computational complexity, it is possible to compute very accurate high dimensional word vectors from a much larger data set.Using the DistBelief distributed framework, it should be possible to train the CBOW and Skip-gram models even on corpora with one trillion words, for basically unlimited size of the vocabulary. That is several orders of magnitude larger than the best previously published results for similar models.
An interesting task where the word vectors have recently been shown to significantly outperform the previous state of the art is the SemEval-2012 Task 2 [11]. The publicly available RNN vectors were used together with other techniques to achieve over 50% increase in Spearman’s rank correlation over the previous best result [31]. The neural network based word vectors were previously applied to many other NLP tasks, for example sentiment analysis [12] and paraphrase detection [28]. It can be expected that these applications can benefit from the model architectures described in this paper.
Our ongoing work shows that the word vectors can be successfully applied to automatic extension of facts in Knowledge Bases, and also for verification of correctness of existing facts. Results from machine translation experiments also look very promising. In the future, it would be also interesting to compare our techniques to Latent Relational Analysis [30] and others. We believe that our comprehensive test set will help the research community to improve the existing techniques for estimating the word vectors. We also expect that high quality word vectors will become an important building block for future NLP applications.
翻译:
本文在一组语法和语义语言任务中,研究了由不同模型派生的词向量表示的质量。我们观察到,与流行的神经网络模型(前馈和循环)相比,使用非常简单的模型架构可以训练高质量的词向量。由于计算复杂性低得多,因此可以从更大的数据集中计算非常精确的高维词向量。使用DistBelief分布式框架,即使在具有一万亿单词的语料库上训练CBOW和Skip-gram模型也应该是可能的,因为词汇量基本上是无限的。这比之前发表的类似模型的最佳结果高出好几个数量级。
一个有趣的任务是SemEval-2012 task 2[11],其中单词向量最近被证明明显优于以前的技术状态。公开可用的RNN向量与其他技术一起使用,使Spearman的秩相关比之前的最佳结果提高了50%以上[31]。基于神经网络的词向量以前被应用于许多其他NLP任务,例如情感分析[12]和释义检测[28]。可以预期,这些应用程序可以从本文中描述的模型体系结构中受益。
我们正在进行的工作表明,词向量可以成功地应用于知识库中事实的自动扩展,也可以用于验证现有事实的正确性。机器翻译实验的结果也很有希望。在未来,将我们的技术与潜在关系分析[30]和其他技术进行比较也会很有趣。我们相信我们的综合测试集将有助于研究界改进现有的估计词向量的技术。我们也期望高质量的词向量将成为未来自然语言处理应用的重要组成部分。