我们知道GPT的含义是:
Generative - 生成下一个词
Pre-trained - 文本预训练
Transformer - 基于Transformer架构
我们看到Transformer模型是GPT的基础,这篇博客梳理了一下Transformer的知识点。
- BERT: 用于语言理解。(Transformer的Encoder)
- GPT: 用于语言生成。(Transformer的Decoder)
GPT也是在BERT的基础上发展起来的,只是OpenAI和google、百度走了不同的路线。
Transformer本质上提出了一种基于注意力机制的encoder-decoder框架或架构。这个架构中的主要组件,如多头注意力机制、位置编码、残差连接以及前馈神经网络都是通用的构建块。
Transformer对比RNN或者LSTM有这些优点:
- 并行计算
- 长期依赖学习
- 训练更稳定
- 更少的参数
- 无需标定的输入输出
Transformer主要缺点如下:
- Transformer无法很好地建模周期时间序列。
- Transformer可能不适合较短序列。
- 计算复杂度较高。
- 缺乏韵律和时域信息。
Encoder的组成:
- Inputs - 输入分词层(Tokenize)
- Input Token Embedding 输入词向量嵌入化(WordEmbedding)
- Transformer Block 中间Encoder层可以简单把这个盒子理解为一个Block ,整 Transformer Block中可以在分解为四层:
- self-attention layer 自注意力计算层
- normalization layer 归一化层
- feed forward layer 前馈层
- anothernormalization layer 另一个归一化层
Decoder和Encoder唯一的区别就是多了一个Encode-Decode注意力层,然后最后一层接了个linear+softmax层,损失函数就是交叉熵损失。
- Self-Attention 计算过程
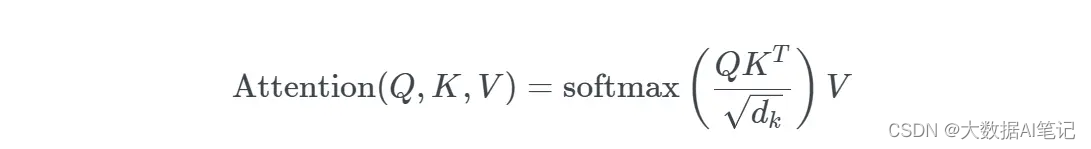
第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。
- 多头-Attention的计算

把multi-headed输出的不同的z,组合成最终想要的输出的z,这就是multi-headed Attention要做的一个额外的步骤。