基础介绍
Stable Diffusion 是一个文本到图像的生成模型,它能够根据用户输入的文本提示(prompt)生成相应的图像。在这个模型中,CLIP(Contrastive Language-Image Pre-training)模型扮演了一个关键的角色,尤其是在将文本输入转换为机器可以理解的形式方面。
CLIP 模型最初由 OpenAI 开发,它是一个多模态预训练模型,能够理解图像和文本之间的关系。CLIP 通过在大量的图像和文本对上进行训练,学习到了一种能够将文本描述和图像内容对齐的表示方法。这种表示方法使得 CLIP 能够理解文本描述的内容,并将其与图像内容进行匹配。
在 Stable Diffusion 中,CLIP 的文本编码器(Text Encoder)部分被用来将用户的文本输入转换为一系列的特征向量。这些特征向量捕捉了文本的语义信息,并且可以与图像信息相结合,以指导图像的生成过程。
贴一下模型结构:
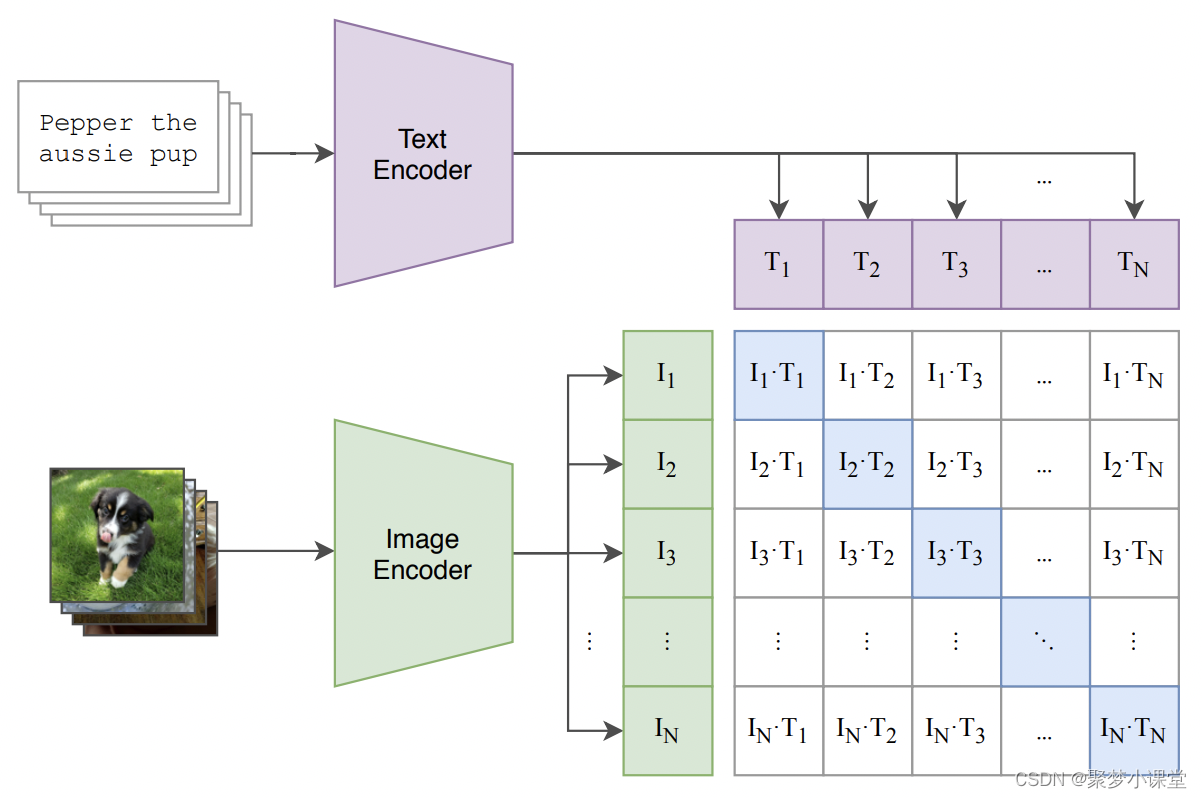
具体来说,当用户输入一个文本提示时,CLIP 的文本编码器会将这个文本转换成一个固定长度的向量序列。这个向量序列包含了文本的语义信息,并且与现实世界中的图像有相关性。在 Stable Diffusion 的图像生成过程中,这些文本特征向量与随机噪声图像一起被送入模型的后续部分,如图像信息创建器(Image Information Creator)和图像解码器(Image Decoder),以生成与文本描述相匹配的图像。
总结来说,CLIP 模型在 Stable Diffusion 中的作用是将文本输入转换为机器可以理解的数值特征,这些特征随后被用来指导图像的生成,确保生成的图像与文本描述相符合。这种结合了文本和图像理解能力的多模态方法,使得 Stable Diffusion 能够创造出丰富多样且与文本描述高度相关的图像。
关于特征向量的长度
在CLIP模型中,文本编码器输出的特征向量的长度是一致的。
CLIP模型的文本编码器通常是一个基于Transformer架构的神经网络,它将输入的文本(例如单词、短语或句子)转换成一系列固定长度的向量。这些向量被称为嵌入(embeddings),它们代表了文本在模型的内部表示空间中的位置。
在CLIP模型的训练过程中,这些嵌入向量的长度是预先设定的,并且在模型的所有训练和推理过程中保持不变。例如,如果CLIP模型被训练为输出768维的文本嵌入,那么无论输入的文本长度如何,每个文本输入都会被转换成一个长度为768的向量。
这种固定长度的向量表示允许模型处理不同长度的文本输入,同时保持模型的一致性和可扩展性。对于较长的文本,CLIP模型可能会采用截断或填充(padding)的方法来确保所有输入的长度一致。这样,无论文本的实际长度如何,模型都能够以统一的方式处理它们。
提示词长度是不是越长越好
在CLIP模型中,如果输入的文本提示(prompt)超过了模型处理的最大长度,可能会出现后半部分的文本不被编码或者不被充分考虑的情况。
CLIP模型在处理文本时,通常会有一个最大长度限制,这意味着它只能有效地处理一定长度内的文本。如果输入的文本超过了这个长度,模型可能会采取以下几种策略之一来处理:
-
截断(Truncation):模型会只考虑文本的前N个标记(tokens),忽略超出部分。这意味着超出长度限制的文本部分不会对最终的特征向量产生影响。
-
摘要(Summarization):模型可能会尝试生成一个文本的摘要,只保留关键信息,但这通常不是CLIP模型的直接功能。
-
滑动窗口(Sliding Window):模型可以采用滑动窗口的方法,对文本的不同部分分别编码,然后将这些局部编码组合起来。这种方法可以保留更多文本信息,但可能会丢失一些上下文信息。
在实际应用中,为了确保文本提示能够有效地影响图像生成的结果,通常会对输入的文本进行适当的编辑,使其长度适应模型的处理能力。
Clip模型是如何与unet模型结合使用的呢
CLIP(Contrastive Language-Image Pre-training)模型与UNet模型结合使用通常是为了在图像生成或图像处理任务中利用CLIP的文本理解能力和UNet的图像处理能力。这种结合可以在多种应用中实现,例如在Stable Diffusion等文本到图像的生成模型中。以下是CLIP与UNet结合使用的一种可能方式:
-
文本编码:首先,CLIP的文本编码器(Text Encoder)部分用于处理用户提供的文本提示(prompt)。它将文本转换为一系列的特征向量(text embeddings),这些向量捕捉了文本的语义信息。
-
图像编码:UNet结构通常用于图像的编码和解码。在图像生成任务中,UNet的编码器(Encoder)部分可以将输入的图像或噪声数据编码为一个隐含向量(latent vector),而解码器(Decoder)部分则可以从这个隐含向量重建图像。
-
结合文本和图像特征:在结合CLIP和UNet时,CLIP提取的文本特征可以与UNet处理的图像特征进行交互。例如,文本特征可以作为注意力机制的一部分,引导UNet在图像生成过程中关注与文本描述相关的图像区域。
-
迭代优化:在生成过程中,UNet可能会进行多次迭代,每次迭代都会根据CLIP提供的文本特征来优化图像。这可以通过交叉注意力(cross-attention)机制实现,其中文本特征作为注意力的键(key)和值(value),而UNet的特征作为查询(query)。
-
生成图像:通过这种结合,模型能够生成与文本提示语义上一致的图像。在迭代过程中,模型不断调整图像,直到生成的图像与文本描述相匹配。
clip skip是什么意思
Stable Diffusion的应用中,Clip Skip是一个参数,它用于控制图像生成过程中的细分程度。这个参数允许用户在生成图像时跳过CLIP模型中的一些层,从而影响生成图像的细节和风格。
具体来说,Clip Skip的作用包括:
-
控制生成速度:
Clip Skip的值越大,Stable Diffusion在生成图像时会跳过更多的层,这可以加快图像生成的速度。但是,这可能会牺牲图像的质量,因为跳过的层可能包含了对生成细节重要的信息。 -
调整图像质量:较低的
Clip Skip值意味着生成过程中会使用更多的层,这通常会导致更详细和精确的图像。相反,较高的Clip Skip值可能会导致图像质量下降,因为模型在生成过程中省略了一些细节。 -
灵活性和多样性:通过调整
Clip Skip的值,用户可以根据他们的需求和偏好来控制生成图像的风格和细节程度。这为用户提供了在速度和质量之间做出权衡的灵活性。
在实际应用中,用户可能需要通过实验来找到最佳的Clip Skip值,以便在保持所需图像质量的同时,实现合理的生成速度。例如,如果用户需要快速生成草图或概念图,可能会选择较高的Clip Skip值;而如果用户追求高质量的艺术作品,可能会选择较低的Clip Skip值。
这里是聚梦小课堂,如果对你有帮助的话,记得点个赞哦~