一、摘要

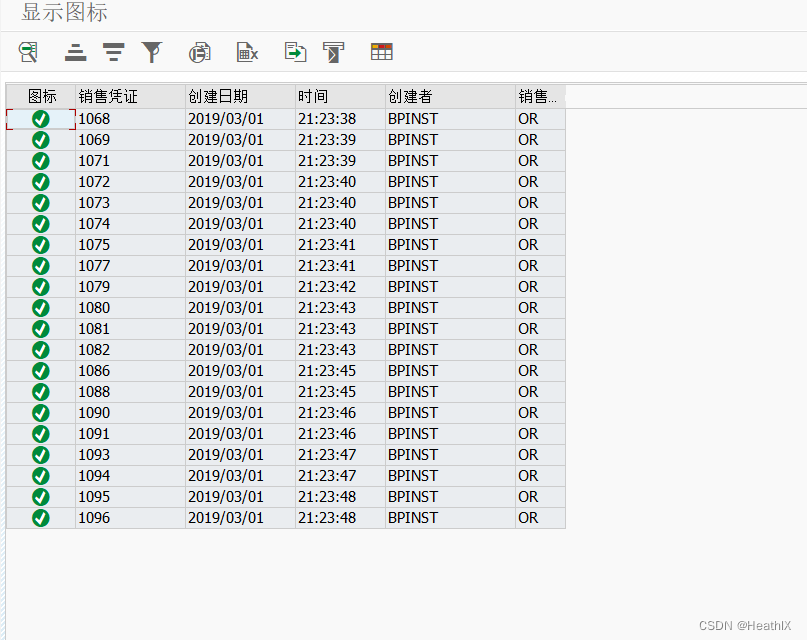
图1 图档示例
本篇代码目的是从指定文件夹下的PDF文件中提取物料编码等相关信息,并将这些信息存储在列表中输出。这段代码主要实现了以下功能:
-
定义一个
file_name函数,用于获取指定文件夹下所有文件的完整路径。通过遍历文件夹和子文件夹,将每个文件的路径添加到列表中并返回。 -
定义一个
Extract_material_code函数,用于从PDF文件中提取物料编码、零件名称和材料名称。该函数首先获取PDF文件的文件名,然后读取PDF文档中的文本内容。接着,使用正则表达式从文本中匹配物料编码和材料名称,并返回零件名称、物料编码和材料名称的元组。如果匹配失败,则返回零件名称和两个空字符串。 -
在主程序中,首先定义一个空列表
information_list用于存储提取的信息。然后,调用file_name函数获取指定文件夹下所有文件的路径列表。接着,遍历路径列表,筛选出PDF文件,并调用Extract_material_code函数提取每个PDF文件的物料编码等信息,将结果添加到information_list中。最后,打印出information_list的内容。
二、架构流程
-
导入所需的模块: 虽然代码中没有明确地导入,但该脚本需要
os,fitz, 和re模块。os用于文件和目录操作,fitz用于处理 PDF 文件,而re用于正则表达式匹配。 -
定义
file_name函数: 该函数接受一个文件夹路径作为参数,并返回该文件夹及其所有子文件夹中所有文件的路径列表。它使用os.walk遍历给定目录及其所有子目录,并收集每个子目录中的文件路径。 -
定义
Extract_material_code函数: 这个函数接受一个 PDF 文件的路径作为参数,并尝试从中提取物料编码和材料名称。它首先从文件名中提取零件名称,然后打开 PDF 文件并提取所有文本。接着,它使用正则表达式查找特定的文本模式以提取物料编码和材料名称。如果找不到这些信息,则返回空字符串。 -
主执行部分:
- 首先,创建一个空列表
information_list,用于存储从每个 PDF 文件中提取的信息。 - 然后,调用
file_name函数来获取指定文件夹中所有文件的路径列表。 - 对于
archives_path_list中的每个文件路径,调用Extract_material_code函数以提取信息。提取的信息(零件名称、物料编码、材料名称)被添加到information_list中。 - 最后,打印
information_list,该列表现在包含从所有 PDF 文件中提取的信息。
- 首先,创建一个空列表
这个脚本的主要目的是从特定文件夹中的所有 PDF 文件中提取物料编码和材料名称,并将这些信息以列表的形式输出。
三、完整代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023-08-26 16:51
# @Author : Leuanghing Chen
# @File : 提取pdf图档物料编码.py
# @Software : PyCharmimport fitz # pip install PyMuPDF
import re
import os# 获取当前文件夹下所有文件名
def file_name(file_dir):# print(root) # 当前目录路径# print(dirs) # 当前路径下所有子目录# print(files) # 当前路径下所有非目录子文件path_list = []for root, dirs, files in os.walk(file_dir):for i in range(len(files)):path = root + '\\' + files[i]path_list.append(path)return path_list# 提取pdf图档上的物料编码
def Extract_material_code(pdf_path):# 获取零件名称filename = pdf_path.split('\\')[-1]part_name = filename.replace('.pdf', '')text = ""pdf_document = fitz.open(pdf_path)# 提取pdf文字for page_num in range(pdf_document.page_count):text += pdf_document[page_num].get_text()try:# 物料编码regex_material_code = r'物料编码:(.*?)\n'material_code = re.findall(regex_material_code, text, re.S)[0]# 材料regex_material_name = r'.*:.*\n(.*?)\n共.*张 第.*张'material_name = re.findall(regex_material_name, text, re.S)[0]return part_name, material_code, material_nameexcept IndexError:return part_name, "", "" # 对齐格式if __name__ == '__main__':information_list = []archives_path_list = file_name(r'D:\python_demo\读取pdf文件\temp') # 读取文件夹中的所有文件for archives_path in archives_path_list:# 筛选pdf文件if archives_path.split(".")[-1].lower() == 'pdf':code_name_list = Extract_material_code(archives_path)information_list.append(code_name_list)print(information_list)