一、什么是爬虫?
爬虫是网络爬虫的简称,指的是一种自动化程序,用于在互联网上抓取信息。爬虫的核心工作包括爬取网页、解析数据和存储数据。
通俗来说就是:通过一个程序,根据url(http://taobao.com)进行爬取网页,获取有用信息。或者使用程序模拟浏览器,去向服务器发送请求,获取响应信息。
二、爬虫的核心

1、爬取网页
爬虫需要获取网络上的数据来进行后续的处理,这个过程被称为“爬取”。在实际的操作中,通常使用 HTTP 协议进行数据交换。爬虫通过向目标服务器发送 HTTP 请求,并解析返回的 HTML 数据来获得所需的信息。在这个过程中,爬虫需要考虑到以下问题:
●安全性:爬虫需要尽可能地避免对目标服务器造成不必要的负担,因此需要进行合理的请求频率控制。
●可靠性:由于网络环境的不稳定性,爬虫需要具有重试机制以保证数据的完整性和可靠性。
●速度优化:爬虫需要适当地选择请求方式,以及优化请求参数和请求体等内容,以提高爬取效率。
2、解析数据
爬虫获取到的数据通常并不是直接可用的信息,需要进行解析和清洗。数据解析是将爬取到的 HTML 数据转换为可用数据的过程。解析数据时需要解决以下的难点:
●数据格式:HTML中包含了大量的标签和属性信息,需要对其进行解析和提取,转换成可用的数据格式。
●数据清洗:爬虫获取到的数据中可能包含无用的信息、空白字符等,需要进行清洗和处理。
●编码问题:由于不同网站使用的编码方式不同,因此在进行数据解析时需要考虑编码问题。
3、爬虫与反爬虫之间的博弈
爬虫和反爬虫是一种典型的博弈关系。反爬虫指的是针对爬虫的防御机制,旨在保护数据安全和私密性。常见的反爬虫技术包括:
●代理:使用代理 IP 来隐藏真实 IP 地址,以免被封禁。
●伪装User-Agent:通过改变请求头中的User-Agent字段,模拟浏览器发送请求,以绕过User-Agent识别。
●分布式爬取:将任务分散给多个爬虫节点,降低单个IP被封禁的风险。
●解析JavaScript:针对动态页面,使用Selenium等工具解析JavaScript。
针对这些反爬虫技术,爬虫需要采用相应的策略来规避或者绕过防御措施,例如:
对应措施:
●使用代理:使用代理 IP 来隐藏真实 IP 地址,以免被封禁。
●伪装User-Agent:通过改变请求头中的User-Agent字段,模拟浏览器发送请求,以绕过User-Agent识别。
●分布式爬取:将任务分散给多个爬虫节点,降低单个IP被封禁的风险。
●解析JavaScript:针对动态页面,使用Selenium等工具解析JavaScript。
三、爬虫的用途
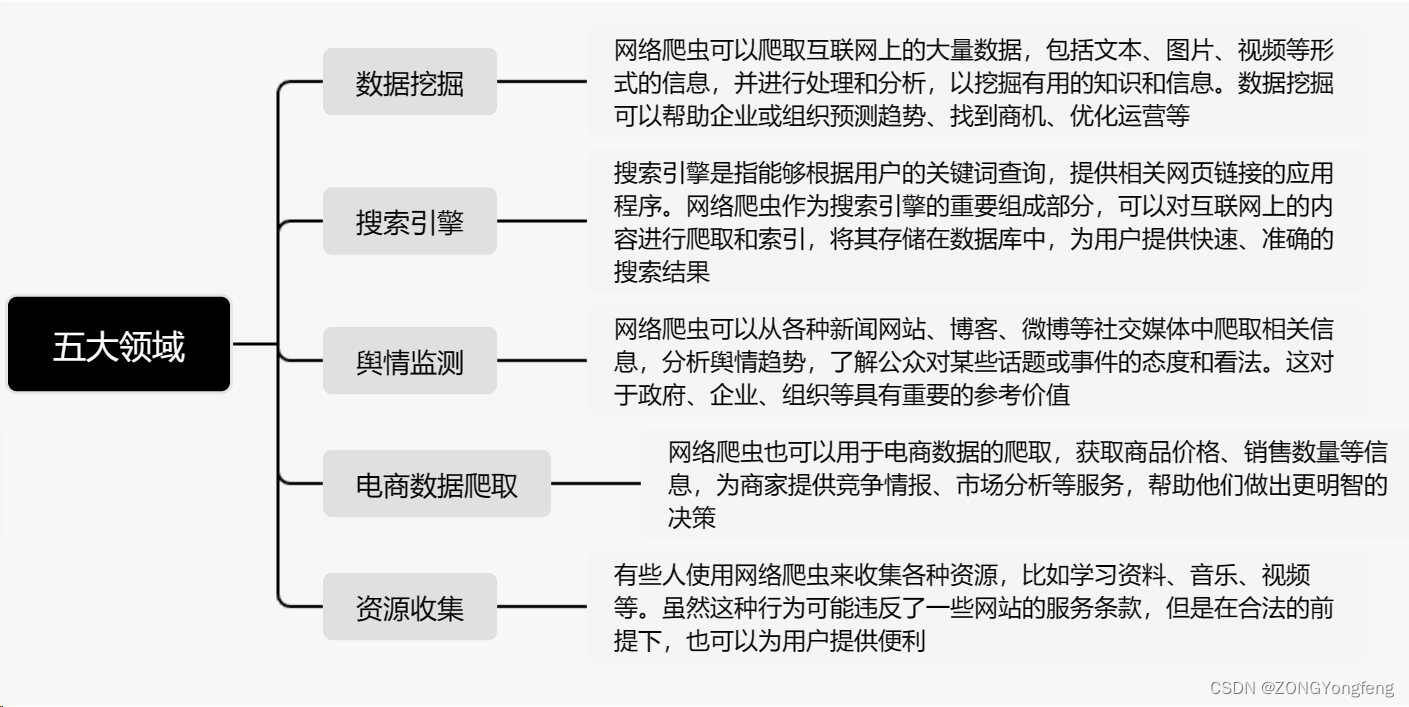
网络爬虫被广泛应用于以下几个领域:数据挖掘、搜索引擎、舆情监测、电商数据爬取、资源收集。
四、爬虫的分类
在爬虫的分类中,通用爬虫和聚焦爬虫是两种广泛应用的爬虫类型
1、通用爬虫:
通用爬虫(也称为全网爬虫)是一种能够自动化地抓取互联网上所有可访问的网页的爬虫。它会从一个起始点开始,通过不断地跟踪链接、解析 HTML 等方式,遍历整个互联网,获取尽可能多的信息。
优点:
能够收集大量的数据,但同时也存在着一些问题。首先,通用爬虫需要很长时间才能完成任务,因为它需要遍历整个互联网。其次,由于互联网上存在大量的非常规页面、重定向页面等,通用爬虫可能会受到反爬虫机制的限制
2、聚焦爬虫
聚焦爬虫(也称为增量式爬虫)是一种只抓取特定内容的爬虫。与通用爬虫不同,聚焦爬虫通过设定爬取目标、规则等方式,有针对性地抓取满足规则的内容。这样可以节省时间和计算资源,提高效率。
优点
它能够更快地获取所需的信息,并且不容易受到反爬虫机制的限制。但是,由于聚焦爬虫只针对特定内容进行抓取,可能会遗漏一些与目标相关的信息
3、区别:
两者区别爬取的范围和方式不同。通用爬虫旨在遍历整个互联网,通过自动化的方式收集尽可能多的信息。而聚焦爬虫则更加关注特定内容,只针对符合规则的网页进行抓取
此外,通用爬虫需要存储所有爬取到的数据,因此需要更多的存储空间和计算资源。而聚焦爬虫只需要针对性地抓取目标内容,可以节省很多计算和存储资源
五、robots协议
Robots协议是一种基于文本的协议,用于指示网络爬虫哪些页面可以访问、哪些页面不能访问。它是由网站管理员在网站根目录下创建名为 robots.txt 的文件,并在其中编制一系列规则。通过识别此文件中的规则,网络爬虫就可以遵循这些规则来访问网站。
Robots协议有以下几个重要部分:
1、User-agent
User-agent是指爬虫的名称或标识符。当爬虫访问网站时,它会向服务器发送一个包含自己标识符的请求头,网站服务器就可以根据这个标识符来区分爬虫和真实用户。
2、Disallow
Disallow是指禁止访问的URL列表。如果某个URL被列在了Disallow列表中,那么爬虫就不应该访问这个URL。值得注意的是,Disallow列表只适用于相对路径,而不适用于绝对路径。
3、Allow
Allow是指允许访问的URL列表。如果某个URL被列在了Allow列表中,那么爬虫可以访问这个URL和Disallow一样,Allow也只适用于相对路径。
4、Sitemap
Sitemap是指网站地图的URL地址。它提供了一个包含所有页面的列表,可以帮助爬虫更快地发现网站的内容。
Robots协议的作用在于保护网站的隐私和安全,同时也可以控制网络爬虫对网站访问的范围。通过设置Robots协议,网站管理员可以防止爬虫访问敏感信息、减轻服务器负担等。但是,需要注意的是,Robots协议并不能防止所有的网络爬虫,只有那些遵循协议规则的爬虫才会受到限制。
总之,Robots协议是一种基于文本的协议,用于指示网络爬虫哪些页面可以访问、哪些页面不能访问。它是网站管理员维护网站安全和隐私的重要工具,同时也可以控制网络爬虫的访问范围。