Oracle内存结构与参数调优
- Oracle 内存结构概览
- oracle参数配置概览
- 重要参数(系统运行前配置):
- 次要参数(可在系统运行后再优化调整):
- Oracle数据库服务器参数如何调整
- OLTP内存分配
- 操作系统核心参数配置
- Disabling ASMM(禁用自动共享内存管理)
- PGA(Program Global Area)
- PGA_AGGREGATE_TARGET
- PROCESSES
- OPEN_CURSORS & SESSION_CACHED_CURSORS
- 不用重新启动而修改初始参数文件
- 启动大页(vm.nr_hugepages)
Oracle 内存结构概览
oracle 体系结构:
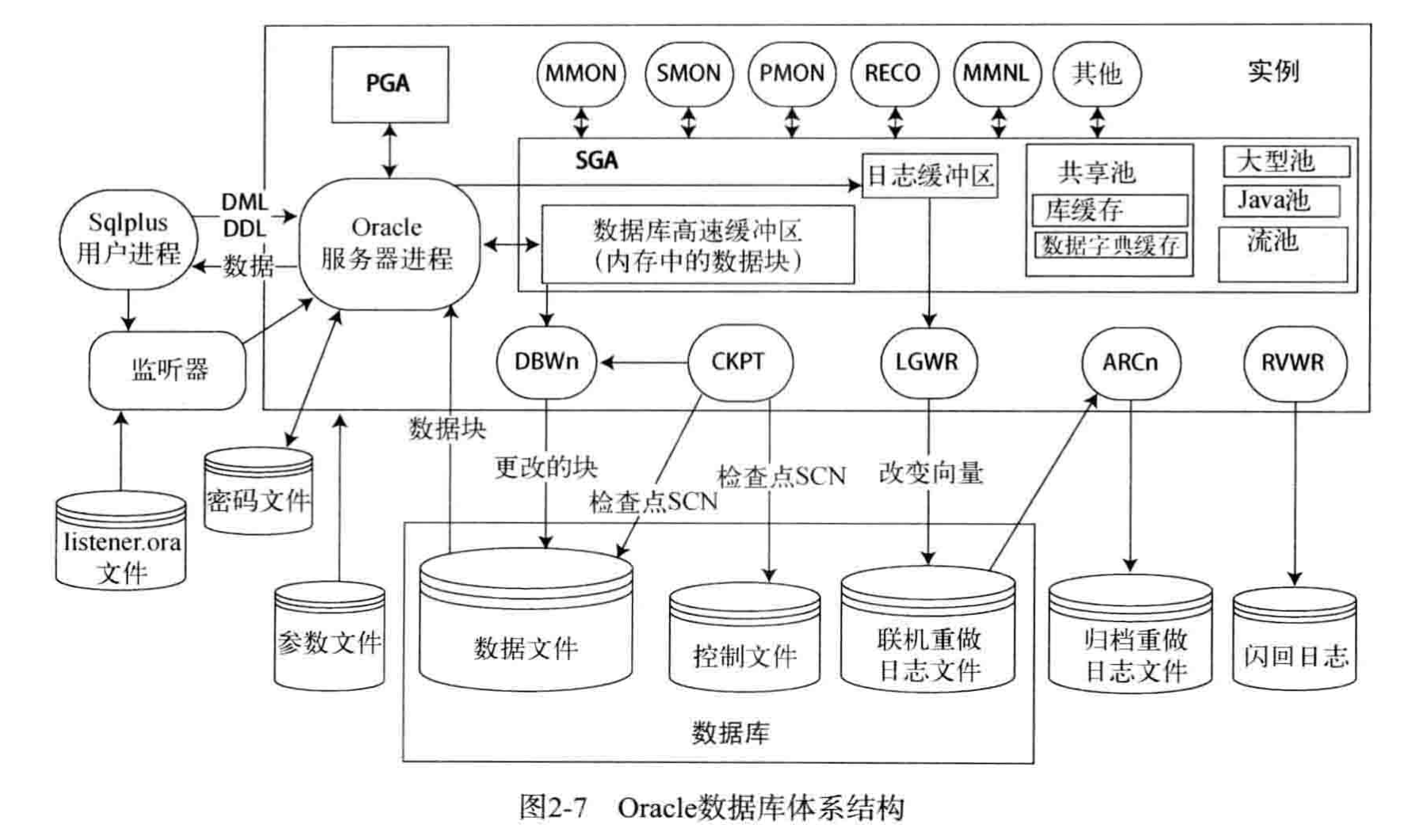
Oracle 内存结构:
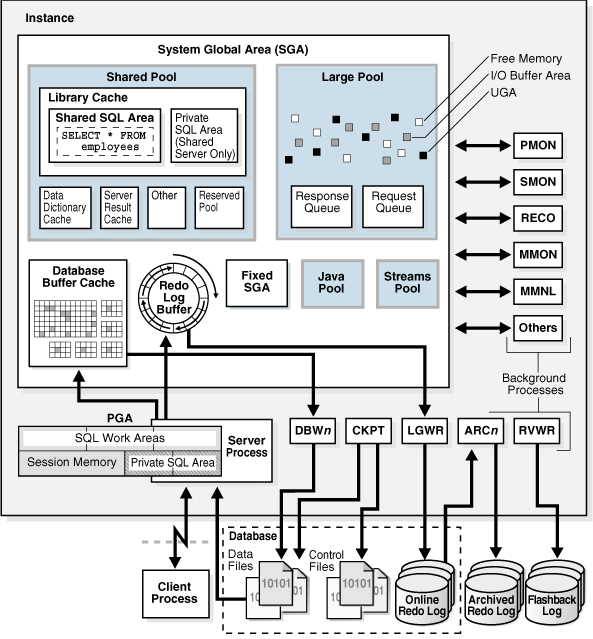
- System Global Area (SGA,系统全局区)
- Share Pool (共享池)
- Database Buffer Cache (数据库缓冲区缓存)
- Redo Log Buffer (重做日志缓冲区)
- Large Pool (大池)
- Java Pool(Java池)
- Streams Pool(流池)
- Fixed SGA(固定SGA区域)
- Program Global Area (PGA,程序全局区域)
- User Global Area(UGA,用户全局区域)
- Cursor Area(游标区)
- User Session Data Storage_Area (用户会话数据存储区)
- SQL Work Areas(SQL工作区)
- 1). Sort Area(排序区)
- 2). Hash Area(哈希区)
- 3). Create Bitmap Area(位图索引创建区)
- 4). Bitmap Merge Area (位图索引融合区)
- Stack Space(堆栈空间)
- User Global Area(UGA,用户全局区域)
oracle参数配置概览
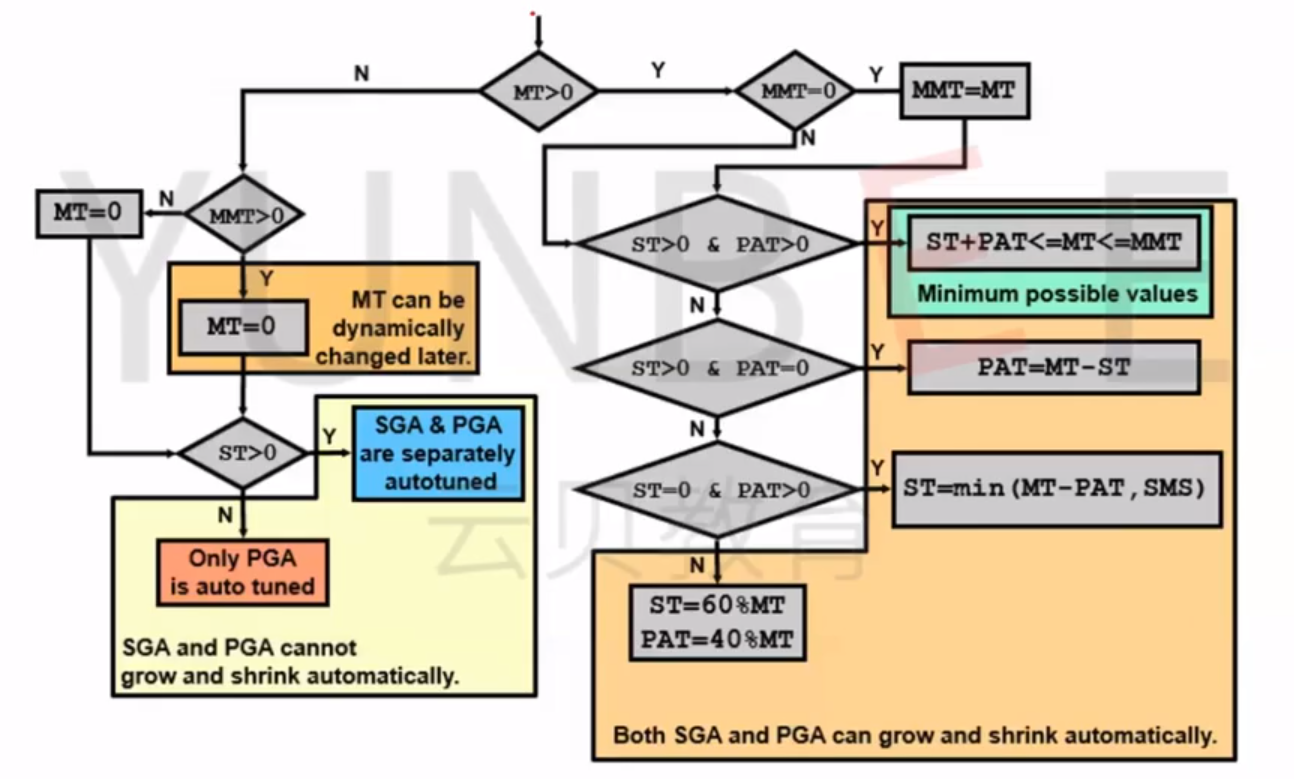
重要参数(系统运行前配置):
带MAX的参数不能在线修改,需要重启后才生效,所以一定要提前规划好
-
内存管理参数:
MEMORY_MAX_TARGET(11g): 定义了Oracle数据库实例允许使用的最大内存量,包括SGA和PGA。动态调整可用内存,无需重启实例。
MEMORY_TARGET(11g): 指定数据库实例使用的内存目标,包括SGA和PGA。与MEMORY_MAX_TARGET结合使用,实现动态内存管理。 -
SGA参数:
SGA_TARGET(10g): 自动管理SGA的总内存大小,包括共享池、数据缓存等。通过自动调整子组件大小,适应变化的工作负载需求。 -
PGA参数:
PGA_AGGREGATE_TARGET(9i): 指定PGA的目标大小,由系统动态调整,根据工作负载需求自动分配内存给各个会话的PGA。 -
数据缓存参数:
DB_CACHE_SIZE(10g): 指定数据库缓存的大小,用于缓存数据块,影响数据的读取性能。 -
共享池参数:
SHARED_POOL_SIZE(10g): 定义共享池的大小,用于缓存SQL语句、PL/SQL块和执行计划。影响SQL执行性能。 -
连接和进程参数:
PROCESSES(10g): 控制并发用户连接的最大数量。
OPEN_CURSORS(10g): 设置一个会话可以打开的最大游标数。
SESSION_CACHED_CURSORS(10g): 缓存在会话中的游标数,减少游标重新解析的开销。
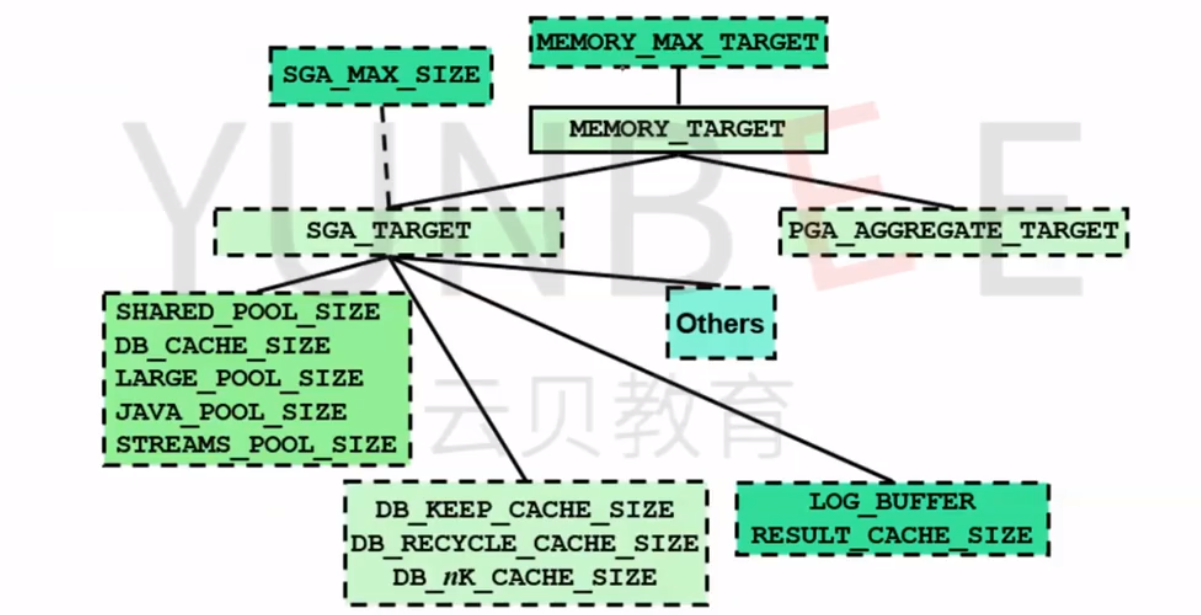
次要参数(可在系统运行后再优化调整):
-
大池参数:
LARGE_POOL_SIZE: 用于备份和并行操作的大型I/O的合并。适用于特定工作负载需求。 -
Java虚拟机参数:
JAVA_POOL_SIZE: 指定Java虚拟机使用的内存大小。影响Java相关操作的性能。 -
数据流参数:
STREAMS_POOL_SIZE: 为Oracle Streams提供的内存池,用于处理数据流操作。 -
保留缓存参数:
DB_KEEP_CACHE_SIZE: 为频繁访问的对象提供的保留缓存,提高这些对象的性能。 -
循环缓存参数:
DB_RECYCLE_CACHE_SIZE: 为一次性或不经常访问的对象提供的循环缓存。 -
日志缓冲区参数:
LOG_BUFFER: 控制数据库日志缓冲区的大小,适应不同的日志写入需求。 -
结果缓存参数:
RESULT_CACHE_SIZE: 指定结果集缓存的大小,用于缓存SQL查询结果,提高重复查询性能。 -
自动PGA管理:
PGA_AGGREGATE_LIMIT(11g R2以后):指定PGA的硬限制,防止PGA使用过多内存。 -
自动诊断和调整:
ADDM(Automatic Database Diagnostic Monitor):自动数据库诊断监控,提供关于性能问题和建议的报告。
AWR(Automatic Workload Repository):自动工作负载存储库,用于存储性能统计信息。 -
SQL执行计划管理:
OPTIMIZER_CAPTURE_SQL_PLAN_BASELINES:启用或禁用自动捕获SQL执行计划基线的功能。
OPTIMIZER_USE_SQL_PLAN_BASELINES:启用或禁用使用SQL执行计划基线的功能。 -
自动调整:
ADAPTIVE_PLAN_MANAGEMENT:启用或禁用自适应计划管理,允许数据库自动调整执行计划。 -
分区表和分区索引:
PARTITION_TABLE:用于启用或禁用分区表。
PARTITION_INDEX:用于启用或禁用分区索引。 -
数据压缩:
COMPATIBLE:指定数据库版本,决定数据库是否支持特定的功能,例如表级数据压缩。 -
连接管理:
SHARED_SERVERS:指定共享服务器的数量,用于连接管理。 -
并行执行:
PARALLEL_DEGREE_POLICY:用于设置并行度策略,可以是 MANUAL(手动)或 AUTO(自动)。
PARALLEL_MIN_SERVERS和PARALLEL_MAX_SERVERS:用于设置最小和最大并行服务器的数量。 -
数据库缓存:
DB_nK_CACHE_SIZE:根据不同块大小设置数据库缓存大小。 -
RAC (Real Application Clusters) 参数:
CLUSTER_DATABASE_INSTANCES:指定在RAC环境中的数据库实例数量。
CLUSTER_DATABASE:用于启用或禁用RAC功能。
Oracle数据库服务器参数如何调整
以 IBM3850 服务器为例,在安装好oracle软件且数据库建好之后,投入使用之前需要调整好相关参数
- CPU数量:4颗
- 内存容量:64G

OLTP内存分配
-
工作区(Work Area,排序、Hash Join、位图连接):6G
在OLTP(联机事务处理)环境下,数据库工作区用于临时存放排序、哈希连接、位图连接等操作产生的中间数据。这里的6GB是指为这些操作预留的内存空间,确保在处理复杂查询时有足够的内存供运算使用,减少对磁盘I/O的需求,从而提高系统性能。 -
Oracle服务器进程:一个连接 5M~10M,processes参数 * 10M,2000 * 10M=20G
在Oracle数据库中,每个客户端连接都会对应一个服务器进程。这里假定每个服务器进程需要5MB至10MB的内存。如果数据库参数processes设置为可以同时接受2000个并发连接,那么所有服务器进程所需的总内存大约在10M * 2000 = 20GB左右。这部分内存是为了支持并发用户的活动,包括处理SQL查询、事务管理等操作。 -
OS系统自用:6G
这里的6GB内存是留给操作系统自己使用的,包括内核内存、缓存、以及其他系统组件的内存需求。这部分内存确保操作系统稳定运行,并可以处理各种系统级别的任务。 -
SGA = 64 - 6G - 20G - 6G = 32G
SGA(系统全局区)是Oracle数据库中用于存储共享数据结构的一个内存区域,包括数据缓冲区、重做日志缓冲区、共享池、大池等。根据给定的内存分配,64GB总内存减去工作区的6GB、服务器进程所需的20GB以及系统自用的6GB之后,剩余的32GB内存会被分配给SGA,以确保数据库的高效运作。
操作系统核心参数配置
cp /etc/sysctl.conf /etc/sysctl.conf.bak # 将当前的sysctl配置文件做一个备份,以防万一需要回滚MemTotal=`grep MemTotal /proc/meminfo | awk '{print $2}'` # 从/proc/meminfo中提取系统总的内存大小(以KB为单位)
PAGE_SIZE=`getconf PAGE_SIZE` # 获取操作系统中一页内存的大小(以字节为单位)shmmax=`expr $MemTotal \* 1024` # 根据总内存大小计算 shmmax 参数的最大值,此处将其设为总内存的四倍(转换为KB后再乘以1024转为字节)
shmall=`expr $shmmax / $PAGE_SIZE` # 计算 shmall 参数的值,表示系统范围内共享内存段的总页数上限,这里的计算方法是将 shmmax 值除以一页的大小得出cat >> /etc/sysctl.conf << EOF # 向sysctl配置文件追加以下配置项
fs.file-max = 6815744 # 设置系统允许的最大文件句柄数
kernel.sem = 10000 10240000 10000 1024 # 设置信号量参数,分别代表SEMMSL(一个信号集中的信号量最大数)、SEMMNS(系统信号量总数)、SEMOPM(一次操作中的信号量操作数)、SEMMNI(系统信号集总数)
kernel.shmmni = 4096 # 设置系统范围内共享内存段标识符的最大数目
kernel.shmall = $shmall # 设置共享内存段页数上限,参考前面计算的结果
kernel.shmmax = $shmmax # 设置共享内存段的最大大小,参考前面计算的结果
net.ipv4.ip_local_port_range = 9000 65500 # 设置本地TCP/UDP端口范围
net.core.rmem_default = 16777216 # 设置接收缓冲区的默认大小
net.core.rmem_max = 16777216 # 设置接收缓冲区的最大大小
net.core.wmem_max = 16777216 # 设置发送缓冲区的最大大小
net.core.wmem_default = 16777216 # 设置发送缓冲区的默认大小
fs.aio-max-nr = 6194304 # 设置异步I/O请求数量上限
vm.dirty_ratio=20 # 设置脏页比例阈值,当系统中脏页占总内存的比例超过这个值时,开始写入磁盘
vm.dirty_background_ratio=3 # 设置后台脏页刷新比率,后台线程开始刷新脏页前,系统中脏页占总内存的比例
vm.dirty_writeback_centisecs=100 # 设置脏页写回时间间隔(以百分秒计)
vm.dirty_expire_centisecs=500 # 设置脏页过期时间间隔(以百分秒计)
vm.swappiness=10 # 控制系统换出内存到硬盘的速度,值越低,尽量避免换出,值越高,倾向于换出
vm.min_free_kbytes=524288 # 设置系统试图保留的最小空闲内存(以KB为单位)
net.core.netdev_max_backlog = 30000 # 设置网络设备接收数据包的最大队列长度
net.core.netdev_budget = 600 # 设置每次软中断处理的数据包数量
net.ipv4.conf.all.rp_filter = 2 # 开启IPv4反向路径过滤(RFC 3704),防止IP欺骗攻击
net.ipv4.conf.default.rp_filter = 2 # 对新建的网络接口开启默认的反向路径过滤# vm.nr_hugepages =16384 # 若物理内存太小(<64G),则不需要开启大页,可以直接注释掉该行
# 注意:此处暂时先注释掉,后面启动大页会解释,需要根据实际需求和内存使用情况决定是否启用和设置正确的 HugePages 数量
EOF# 配置生效
sysctl -p # 执行sysctl命令使得配置文件中所做的更改立即生效#kernel.shmall:系统任意时刻可以分配的所有共享内存段的总和的最大值(以页为单位),其值应不小于shmmax/page_size,推荐设置为物理内存大小除以分页大小。
#kernel.shmmax:单个内存段最大,设置为内存大小
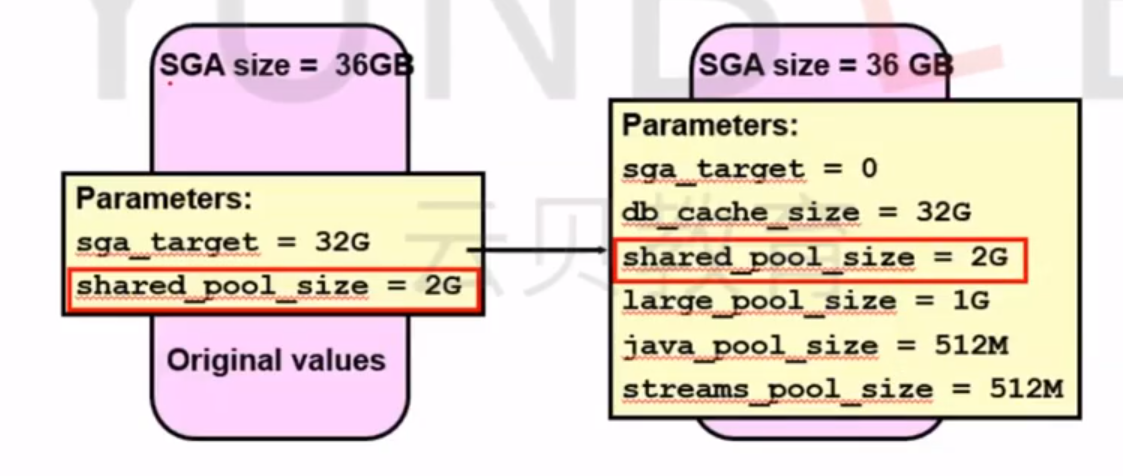
Disabling ASMM(禁用自动共享内存管理)
- SGA_TARGET 设置为0时,将禁用自动调优
- 自动调优参数设置为当前大小
- SGA的大小作为一个整体不受影响
PGA(Program Global Area)
PGA是Oracle数据库中每个服务器进程独有的内存区域,用于存储会话数据、排序区、临时变量以及其他与特定会话相关的数据结构。
PGA_AGGREGATE_TARGET
- 在OLTP系统中,典型PGA内存设置应该是总内存(物理内存)的较小部分(例如20%),剩下80%分配给SGA 。OLTP:PGA_AGGREGATE_TARGET = (total_mem * 80%) * 20%
- 在DSS系统中,由于会运行一些很大的查询,典型的PGA内存最多分配70%的内存。DSS:PGA_AGGREGATE_TARGET = (total_mem * 80%) * 50%
- 设置 PGA 自动分配
alter system set workarea_size_policy = auto scope = both;
alter system set pga_aggregate_target = 2048M scope = both;
show parameter pga
show parameter area
show parameter work
- 监控 PGA
select * from v$pgastat;
# 看 over allocation count(排序时,PGA不够用时需要换页,这个值就是换页次数):如果=0 就正常 PGA够用;若 >0 则PGA不够用需要调整
PROCESSES
- 在Oracle数据库中,设置参数 PROCESSES 和 SESSIONS 是非常重要的,以确保系统能够处理足够的并发连接。这只是一个基本的起点,实际的设置应该根据你的具体应用、系统硬件和负载情况来调整。建议在设置参数之前先进行性能测试,确保系统能够处理预期的并发连接数。
典型的设置是:
10g: sessions = processes + 10% * processes + 5
11g+: sessions = processes + 15 % * processes + 22 - 查看内存使用情况
select p.spid from v$session s,v$process p where p.addr=s.paddr and s.sid in (select sid from v$mystat where rownum=1);
select pga_used_mem,pga_alloc_mem,pga_freeable_mem from v$process where spid = &spid;
- Processes参数优化
create pfile='/tmp/pfileORCL_20240307.ora' from SPFILE; --备份配置文件
alter system set processes = 200 scope = spfile;
OPEN_CURSORS & SESSION_CACHED_CURSORS
- OPEN_CURSORS
- 指定了保存(打开)用户语句的专用区域的大小。如果获得“ORA-01000:maximun open cursors exceeded” 错误,则可能需要增大该参数,但是要确保关闭不在需要的游标。
- 如果 OPEN_CURSORS 设置得过高,则有时也会造成问题:ORA-4031错误(共享池)
- SESSION_CACHED_CURSORS
- 不要将参数 SESSION_CACHED_CURSORS 设置的和 OPEN_CURSORS 一样高,否则就可能产生 ORA-4031 或 ORA-7445 错误(软软解析)
不用重新启动而修改初始参数文件
- spfile<SID>.ora (大部分不需要重启)
- spfile.ora (用的少)
- init<SID>.ora (一定要重启)
- v$parameter 视图
ISSES_MODIFIABLE 表名拥有 ALTER SESSION 特权的用户是否可以修改这个参数
ISSYS_MODIFIABLE 表名拥有 ALTER SYSTEM 特权的用户是否可以修改这个参数
启动大页(vm.nr_hugepages)
什么是大页?
在操作系统层面,默认情况下内存页大小通常为4KB。大页是一种内存管理机制,将标准内存页尺寸增大,例如从4KB改为2MB。使用大页可以减少TLB(Translation Lookaside Buffer)未命中的情况,从而降低页交换频率和I/O开销,提高系统的性能,特别是在大规模内存管理和Oracle数据库等场景下。
什么时候需要启动大页?
当服务器物理内存>=64GB,启用大页可以带来显著的性能提升。
如何启动大页?
-
关闭Oracle Database中的AMM(Automatic Memory Management)
如果尚未手动管理内存,请确保禁用自动内存管理功能。 -
计算hugepages的大小
根据SGA_MAX_SIZE的值来决定hugepages的数量。hugepages的总量应略大于SGA的需求量,同时也要注意避免过大导致内存浪费。例如,如果SGA_MAX_SIZE为32G,而每个大页是2MB,那么至少需要16384个大页(32GB / 2MB)。 -
设置hugepages
编辑内核参数文件/etc/sysctl.conf,加入以下行:vi /etc/sysctl.conf vm.nr_hugepages = 16384 #<计算得出的大页数量>然后执行
sysctl -p命令使更改生效。 -
设置用户进程内存锁定限制
在/etc/security/limits.conf文件中为Oracle数据库用户设置内存锁定限制,确保其能够锁定足够大的内存以支持大页。[root@mydb ~]# vi /etc/security/limits.conf oracle soft memlock 2056000 oracle hard memlock 2056000 -
重启数据库
重启Oracle数据库以便新的内存设置生效。 -
查看大页使用情况
使用如下命令实时监控大页的使用情况:[root@mydb ~]# watch -n1 'cat /proc/meminfo | grep -i HugePages' -
设置pre_page_sga参数
需要在数据库实例启动前预分配并初始化SGA,以利用大页优化性能:alter system set pre_page_sga = true scope = spfile;
参考链接:
- Oracle 23c 官方文档
- 【Oracle】内存结构详解(万字长文,建议收藏,蚕食为佳)