MQ
用处
一、异步。可提高性能和吞吐量
二、解耦
三、削峰
四、可靠。常用消息队列可以保证消息不丢失、不重复消费、消息顺序、消息幂等
选型
一Kafak:吞吐量最大,性能最好,集群高可用。缺点:会丢数据,功能较单一。
二RabbitMQ:可靠性高,功能全面。缺点:吞吐量低,可能消息积累影响性能。
三RocketMQ:高吞吐、高性能、高可用、事务性消息。缺点:生态相对不成熟。
如何保证消息不丢失
可能会丢失消息的环节
生产者->MQ MQ主从复制 MQ存磁盘 MQ->消费者
依次解决
一、生产者发送消息到MQ:
Kafak:回调。RocketMQ:回调、事务性消息。RobbitMQ:回调、手动事务、事务性消息(不细腻)
回调:生产者发送消息之后会注册一个回调函数,MQ收到消息返回ack,表示已收到。
二、消息同步不丢失:
RocketMQ:
普通集群中,异步同步性能高,可能丢消息。同步同步相反。
同步同步是指master结点拿到消息后从节点发送消息,从节点存盘后返回生产者ack。
异步同步是指master结点收到消息后往从节点同步消息,并直接返回生产者ask。
Dledger集群-两阶段提交。类似于ZAB协议同步数据。
RabbitMQ:
普通集群中,消息分散存储,结点不主动进行消息同步,可能丢消息。
镜像集群中,会在集群之间主动进行消息同步,安全性较高。
Kafak:
通常用在允许消息少量丢失的场景。
三、MQ消息内存到磁盘消息不丢失:
RocketMQ:使用同步刷盘安全性高,性能低。异步刷盘相反。
broker收到消息后,消息在内存中,需要其他线程将消息刷新到磁盘。
RabbitMQ:将消息配置为持久化队列,新增的Quorum类型的队列,用Raft协议进行消息同步。
四、MQ消费者消费消息不丢失:
分析:消息队列中有消息的偏移量,一般是在本地事务执行完成后移动。异步可能会丢失消息
RocketMQ:使用默认方式消费即可,不要采用异步的方式。
RabbitMQ:autoCommit->手动提交offset。
Kakfa:手动提交offset
原则:采用同步的方式,在消息被消费完成,也就是本地事务执行完后提交消息,移动偏移量。
如何保证消息幂等
MQ产品并没有主动提供解决幂等的机制,需要由消费者自行控制。
RocketMQ中可以给每条消息分配一个ID,作为判断依据,但不保证全局唯一,不推荐。
建议使用带业务标识的ID,来进行幂等判断,如OrderID,统一ID分配。
如何保证消息有序
MQ只需保证局部有序,不需要保证全局有序。例如一个聊天窗口和整个QQ消息。
关键在于,单机下,队列可以先进先出保证有序,但在分布式状态下,有多个队列。
所以要保证生产者把一组消息放到同一个队列中,而消费者依次消费该消息组的所有消息
RockeMQ:
有完整设计,生产者中MessageSelevtor可保证,消费者需要注册一个registerMessageListener
RabbitMQ:要保证一组消息只对应一个队列,并且一个队列只对应一个消费者
Kafak:生产者可以将消息分配到同一个partition。Topic下只由同一个消费者消费
什么是?
Elasticsearch是一个开源的分布式全文搜索和分析引擎,它能够快速地处理大量的数据,并具有高度可扩展性和可靠性。Elasticsearch最初是在Lucene搜索引擎的基础上开发的,它提供了一个RESTful API,可以通过HTTP来访问。
以下是Elasticsearch的主要特点:
-
分布式架构:Elasticsearch采用分布式架构,可以将数据分片存储在多个节点上,从而提高数据的处理能力和可靠性。
-
实时搜索:Elasticsearch能够快速地搜索和分析数据,支持实时搜索,可以在毫秒级别内返回搜索结果。
-
多种查询方式:Elasticsearch支持多种查询方式,包括全文搜索、精确匹配、模糊匹配、范围查询等。
-
自动负载均衡:Elasticsearch可以自动将数据分配到集群中的不同节点上,并实现负载均衡,从而提高系统的可用性和性能。
-
可扩展性:Elasticsearch可以通过添加新节点来扩展集群的处理能力,同时也支持水平扩展和垂直扩展。
-
多种数据类型:Elasticsearch支持多种数据类型,包括文本、数字、日期、地理位置等。
-
多语言支持:Elasticsearch支持多种语言,包括Java、Python、PHP等。
-
数据安全性:Elasticsearch支持数据加密和访问控制,可以保障数据的安全性。
总的来说,Elasticsearch是一个功能强大、可靠性高、可扩展性好、易于使用的搜索引擎和分析工具,被广泛应用于各种大规模的数据处理和搜索分析场景。
什么是倒排索引
倒排索引(Inverted Index)是一种常用的文本索引技术,用于快速地查找包含特定词语的文档。在倒排索引中,每个词语都对应着一组文档,这些文档包含了该词语出现的位置信息。
倒排索引的构建过程包括以下几个步骤:
-
分词:将文本内容按照一定的规则进行分词,形成一组词语。
-
建立索引:对每个词语建立一个索引,索引中包含了该词语出现的文档列表。
-
存储位置信息:对于每个文档,记录该词语出现的位置信息,以便后续的检索和排名。
倒排索引的查询过程包括以下几个步骤:
-
输入查询词语:用户输入要查询的词语。
-
查找索引:根据查询词语,在倒排索引中查找对应的文档列表。
-
进一步筛选:根据查询词语在文档中出现的位置信息,进一步筛选出符合查询条件的文档。
-
返回结果:返回符合条件的文档列表,可以按照相关性进行排序。
倒排索引的优点包括:
-
快速查找:倒排索引可以快速地查找包含特定词语的文档,减少了搜索的时间和计算量。
-
精确匹配:倒排索引可以实现精确的词语匹配,避免了模糊匹配和错误匹配。
-
支持多种查询方式:倒排索引支持多种查询方式,包括全文搜索、短语搜索、通配符搜索、范围搜索等。
-
支持高效的排名:倒排索引可以根据词语在文档中出现的位置信息,计算出文档的相关性,从而实现高效的排名。
总的来说,倒排索引是一种高效、精确、灵活的文本索引技术,被广泛应用于各种搜索引擎和文本处理系统中。
BoolQueryBuilder
BoolQueryBuilder是Elasticsearch Java API中的一个类,用于构建布尔查询,即使用多个查询条件进行组合查询的操作。除了must、should和must_not三种查询之外,BoolQueryBuilder还提供了一个filter方法,用于添加过滤条件。
与查询条件不同的是,过滤条件不会影响搜索结果的相关性得分,它只是根据条件过滤掉不符合要求的文档,从而提高搜索效率。因此,过滤条件通常用于一些不需要考虑相关性得分的场景,例如范围查询、精确匹配等。
使用filter方法时,需要先创建一个实例对象,然后通过方法链式调用来添加过滤条件。例如:
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery().must(QueryBuilders.termQuery("field1", "value1")).should(QueryBuilders.termQuery("field2", "value2")).mustNot(QueryBuilders.termQuery("field3", "value3")).filter(QueryBuilders.rangeQuery("field4").gte(10).lte(20));
以上代码构建了一个bool查询,包含了三个查询条件和一个过滤条件:field1=value1(必须满足)、field2=value2(可以满足)、field3=value3(不能满足)、field4的值必须在10到20之间(过滤条件)。
构建完bool查询后,可以将其作为参数传递给SearchRequestBuilder的setQuery方法,用于进行搜索操作。例如:
SearchResponse response = client.prepareSearch("index").setQuery(boolQuery).execute().actionGet();
以上代码将bool查询作为参数传递给SearchRequestBuilder的setQuery方法,执行搜索操作,并返回搜索结果。
总之,BoolQueryBuilder是Elasticsearch Java API中一个非常常用的类,可以方便地构建复杂的布尔查询和过滤条件,提高搜索的精确度和效率。
filter和must有什么区别?
过滤条件和must条件都是BoolQueryBuilder类中的方法,用于构建布尔查询。两者的区别在于,过滤条件不会影响搜索结果的相关性得分,而must条件会影响搜索结果的相关性得分。
过滤条件主要用于过滤掉不符合条件的文档,从而提高搜索效率。过滤条件通常用于一些不需要考虑相关性得分的场景,例如范围查询、精确匹配等。在搜索时,过滤条件会被应用到搜索结果上,从而过滤掉不符合条件的文档。
must条件主要用于筛选符合条件的文档,并影响搜索结果的相关性得分。must条件可以包含多个子条件,表示所有子条件都必须满足,相当于“AND”操作。在搜索时,must条件会被应用到搜索结果上,从而筛选出符合条件的文档,并对搜索结果的相关性得分进行加权。
例如,假设我们要搜索商品名称包含“手机”且价格在1000到2000之间的商品,可以使用以下bool查询:
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("name", "手机")).filter(QueryBuilders.rangeQuery("price").gte(1000).lte(2000));
以上代码使用must条件筛选出商品名称包含“手机”的文档,并使用filter条件过滤掉价格不在1000到2000之间的文档。在搜索时,must条件会影响搜索结果的相关性得分,而filter条件不会影响搜索结果的相关性得分,从而提高搜索效率。
总之,过滤条件和must条件都是BoolQueryBuilder类中的方法,用于构建复杂的布尔查询。两者的区别在于,过滤条件不会影响搜索结果的相关性得分,而must条件会影响搜索结果的相关性得分。在实际应用中,我们需要根据具体场景选择合适的条件,以获得更好的搜索效果。
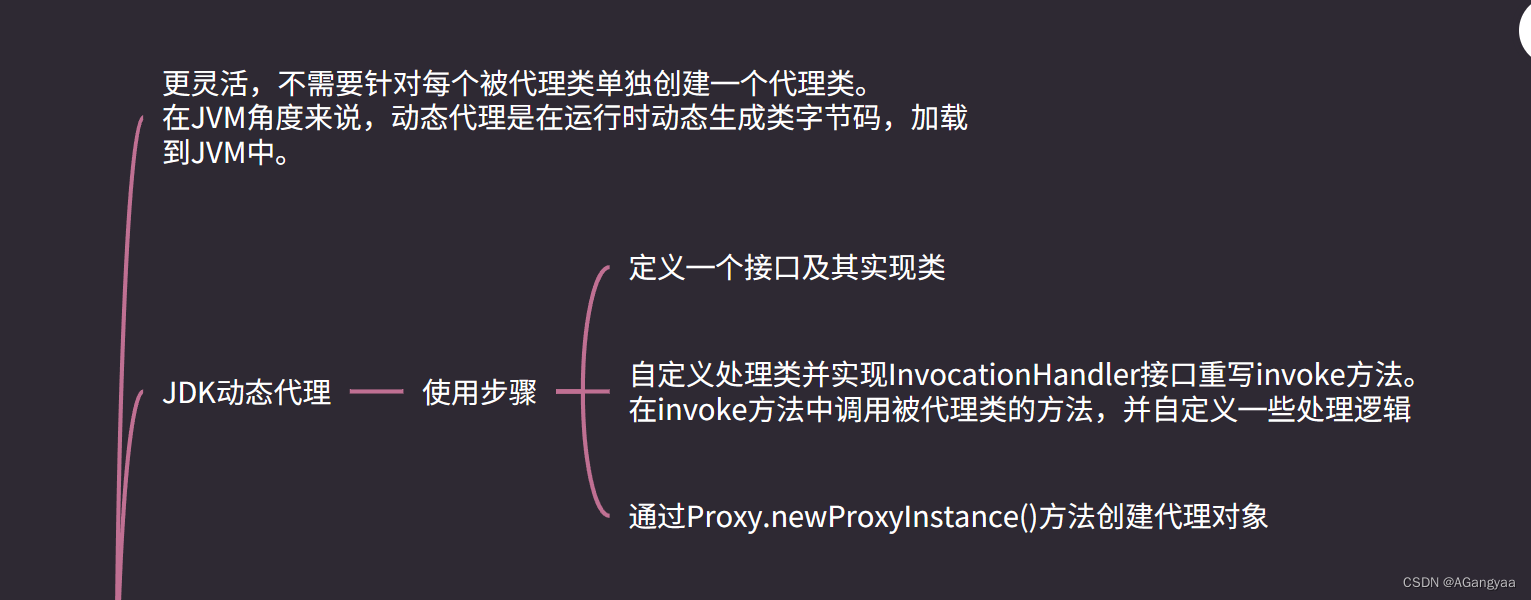
代理模式


工厂模式



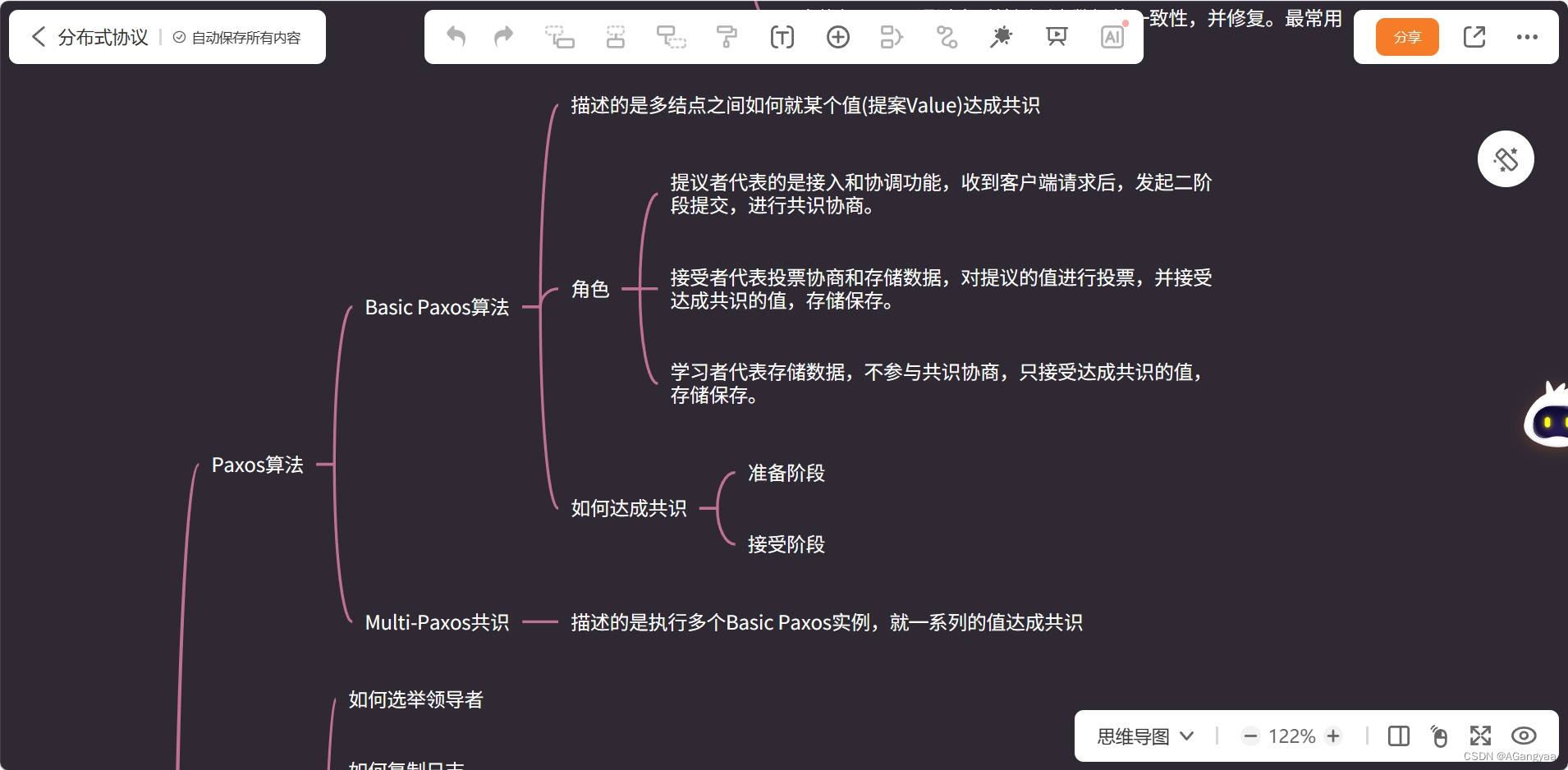
CAP


BASE理论


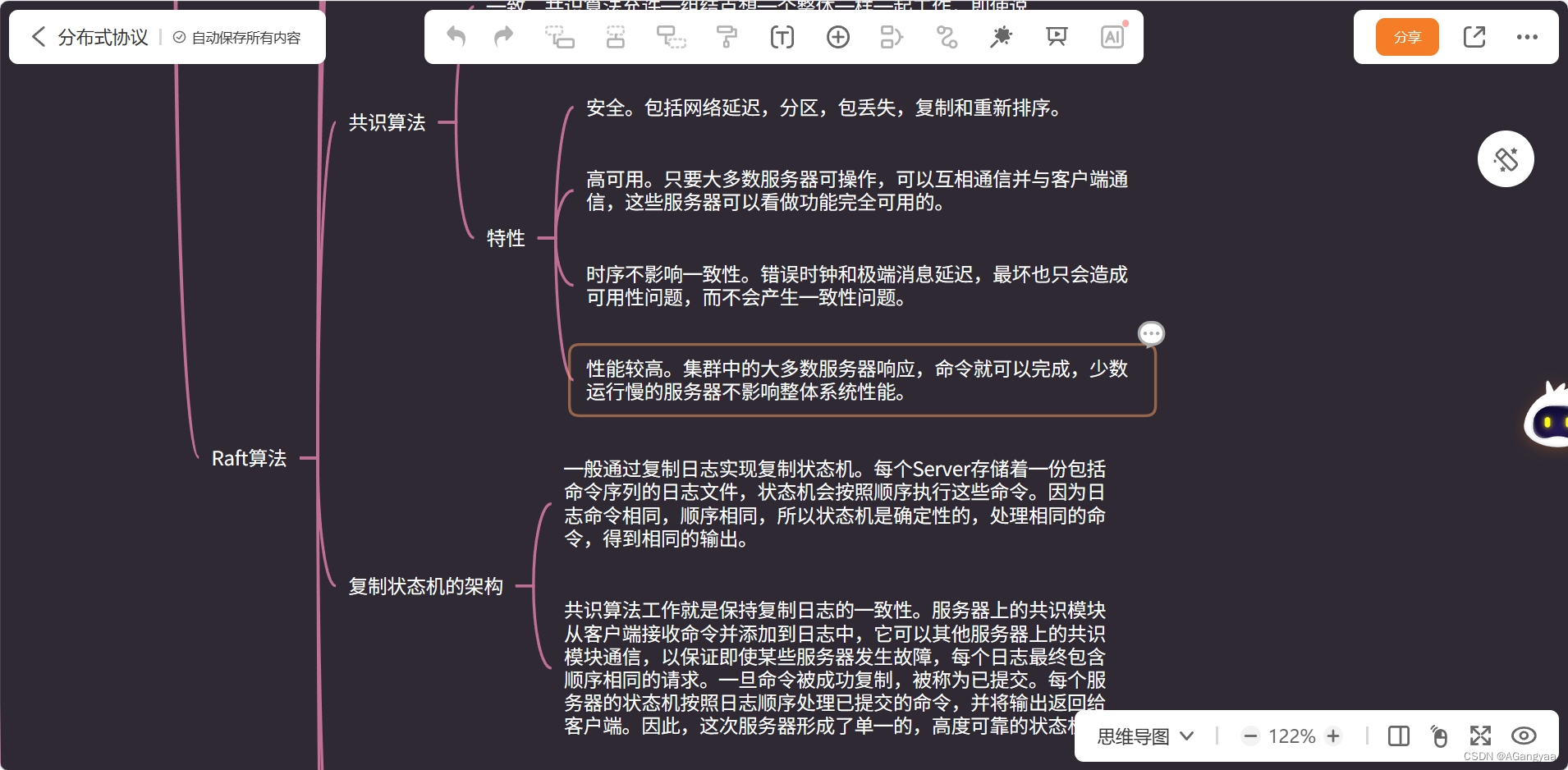
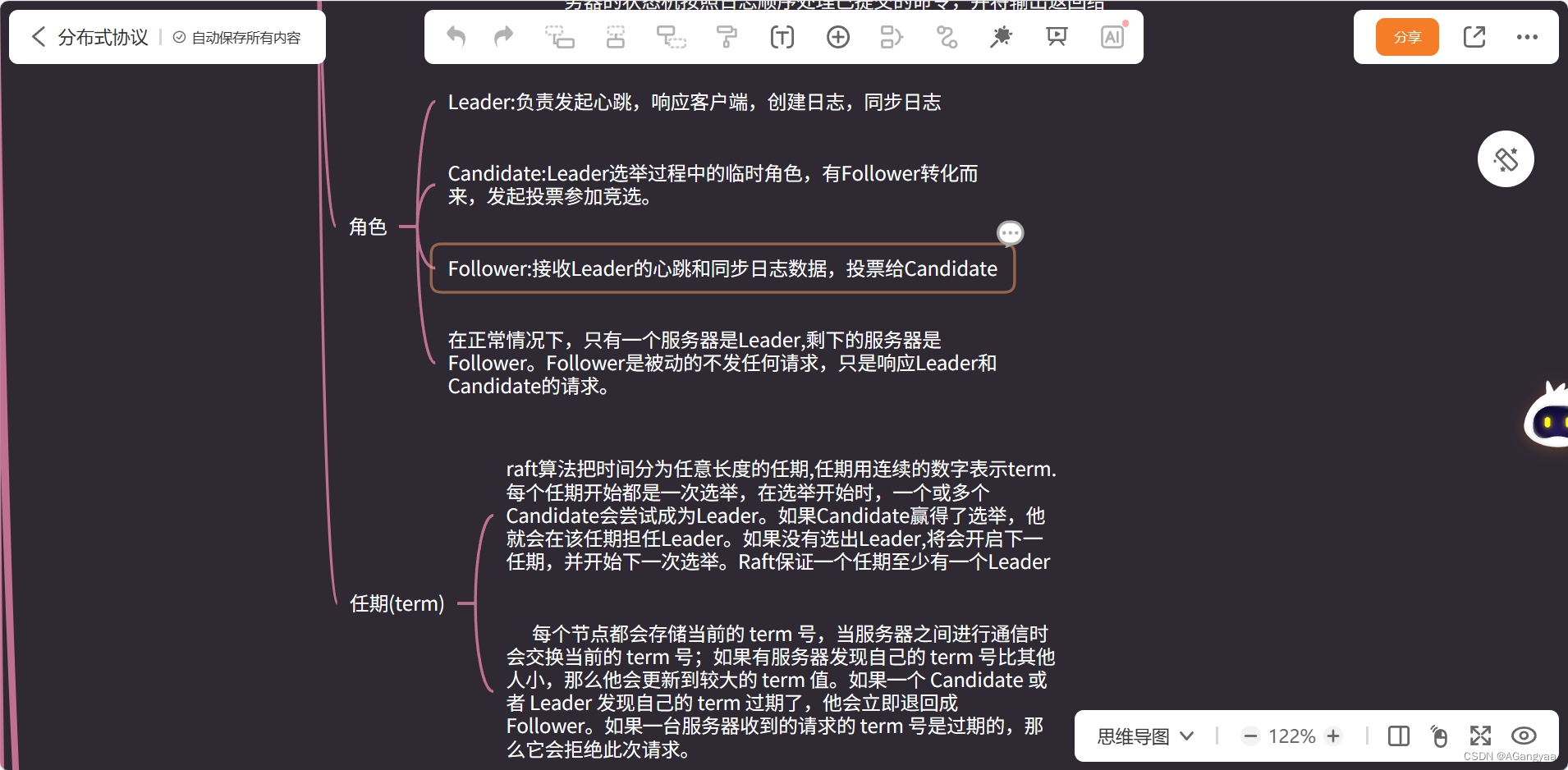
Raft算法

Stomp协议
STOMP(Simple Text-Orientated Messaging Protocol) 面向消息的简单文本协议
WebSocket是一个消息架构,不强制使用任何特定的消息协议,它依赖于应用层解释消息的含义;
与处在应用层的HTTP不同,WebSocket处在TCP上非常薄的一层,会将字节流转换为文本/二进制消息,因此,对于实际应用来说,WebSocket的通信形式层级过低,因此,可以在 WebSocket 之上使用 STOMP协议,来为浏览器 和 server间的 通信增加适当的消息语义。
如何理解 STOMP 与 WebSocket 的关系:
- HTTP协议解决了 web 浏览器发起请求以及 web 服务器响应请求的细节,假设 HTTP 协议 并不存在,只能使用 TCP 套接字来 编写 web 应用,你可能认为这是一件疯狂的事情;
- 直接使用 WebSocket(SockJS) 就很类似于 使用 TCP 套接字来编写 web 应用,因为没有高层协议,就需要我们定义应用间所发送消息的语义,还需要确保连接的两端都能遵循这些语义;
- 同 HTTP 在 TCP 套接字上添加请求-响应模型层一样,STOMP 在 WebSocket 之上提供了一个基于帧的线路格式层,用来定义消息语义;
WebSocket协议定义了两种消息类型(文本类型和二进制类型),但是消息内容却是未定义的,下面我们介绍一下STOMP协议。
STOMP (Simple Text Oriented Messaging Protocol) 起源于脚本语言,比如Ruby、Python和Perl,用于连接企业消息代理,它可以用于任何可靠的双向网络协议中,如TCP和WebSocket。尽管STOMP是一个面向文本的协议,但消息负载可以是文本或者二进制。
STOMP基于WebSocket在客户端和服务端之间定义了一种机制,协商通过子协议(更高级的消息协议)来定义可以发送何种消息,每条消息的内容是什么,等等。