一 前言
因为CPU要操作的数据都在CPU Cache中的话,就不用再从内存中读取数据了,这样就提高了效率,访问的数据在CPU Cache中越多,有个专业名词称为缓存命中率高,所以说,缓存命中率越高,自然执行代码就快了。 总结:所以说写出CPU跑得更快的代码就是写出缓存命中率高的代码。
二 如何提升数据的缓存命中率?
下列哪种方式更快呢?

经过测试,形式一 array[i][j] 执行时间比形式二 array[j][i] 快好几倍。
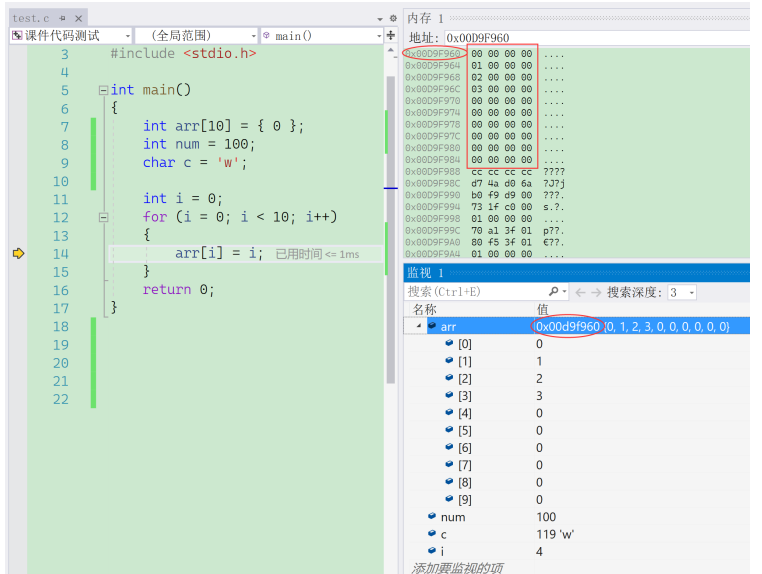
1.之所以有这么大的差距,是因为二维数组 array 所占用的内存是连续的,比如长度 N 的指是 2 的话,那么内存中的数组元素的布局顺序是这样的:

形式一用 array[i][j] 访问数组元素的顺序,正是和内存中数组元素存放的顺序一致。当 CPU 访问 array[0][0] 时,由于该数据不在Cache 中,于是会「顺序」把跟随其后的 3 个元素从内存中加载到 CPU Cache,这样当 CPU 访问后面的 3 个数组元素时,就能在 CPU Cache 中成功地找到数据,这意味着缓存命中率很高,缓存命中的数据不需要访问内存,这便大大提高了代码的性能。
1.而如果用形式二的 array[j][i] 来访问,则访问的顺序就是:
1.你可以看到,访问的方式跳跃式的,而不是顺序的,那么如果 N 的数值很大,那么操作 array[j][i] 时,是没办法把 array[j+1][i] 也读入到 CPU Cache 中的,既然 array[j+1][i] 没有读取到 CPU Cache,那么就需要从内存读取该数据元素了。很明显,这种不连续性、跳跃式访问数据元素的方式,可能不能充分利用到了 CPU Cache 的特性,从而代码的性能不高。那访问 array[0][0] 元素时,CPU 具体会一次从内存中加载多少元素到 CPU Cache 呢?这个问题,在前面我们也提到过,这跟 CPU Cache Line 有关,它表示 CPU Cache 一次性能加载数据的大小,可以在 Linux 里通过 coherency_line_size 配置查看 它的大小,通常是 64 个字节。
1.也就是说,当 CPU 访问内存数据时,如果数据不在 CPU Cache 中,则会一次性会连续加载 64 字节大小的数据到 CPU Cache,那么当访问 array[0][0] 时,由于该元素不足 64 字节,于是就会往后顺序读取 array。
总结:按照内存布局顺序访问,可以有效提高缓存命中率。因为数据被访问时,是先从内存加载到Cache中的,每次加载一个Cache line(缓存行),大小一般64byte,有指令可以查看具体大小。尽可能的按照数据在内存的顺序访问,就可以提高命中率。
三 如何提升L1 Cache中的指令缓存的命中率?
补充一个内容:分支预测器,预测遇到if-else等跳转式指令时,预测接下来是要执行if还是else指令,就可以提前把这些指令加载到L1 Cache的指令缓存中。
提升数据的缓存命中率的方式,是按照内存布局访问。那针对指令如何提升呢,其实也是如此。按照顺序使用内存,分支预测器就可以根据历史命中数据并对未来进行预测,就可以提高命中率。
四 如何提升多核心CPU的缓存命中率?
不论是单核心CPU还是如今常用的多核心CPU,操作系统给没每个进程分配的时间片是一样的,时间片一到,切换进程。宏观看起来是并行。
对于多核心CPU,进程可能在不同的CPU核心来回切换,这对Cache是不利的,如果一个进程在不同的核心间切换,各个核心的缓存命中率就会受到影响,如果进程一直在一个CPU的一个核心执行,就不会受到影响。可以将线程绑定到固定的一个CPU的一个核心,就可以非常可观的提升命中率。