Note:本博客更多是关于自己的感悟,没有翻阅文件详细查证,如果存在错过,也请提出指正。
1. 半监督回归
相比于半监督分类,半监督回归相对冷门。回归和分类之间有着难以逾越的天谴,预测精度。分类中的类别是可数的,有限的;而在回归中可以认为类别是无限的(可以通过离散化将回归任务转化成分类任务,但是这样回归精度就会极具下降)。BEL 试图打破分类与回归之间的天谴,参见。Deep Imbalanced Regression 认为回归任务中同样存在不平衡的问题。其实,这一点在半监督语境下的回归任务中更加突出。
半监督回归则是想要利用无标记数据来提升模型性能。一种简单且有效的方法是打伪标签。值得注意的是,半监督分类中的伪标签包含的噪声更小。可以考虑在一个猫狗分类的任务中,随机标记一个伪标签都有百分之五十的概率标记正确。而在一个预测西瓜甜度,假设范围是 [ 0 , 1 ] [0, 1] [0,1], 很难预测一个一摸一样的标签。
正是因为伪标签很难预测正确,所以需要一个量化置信度的策略。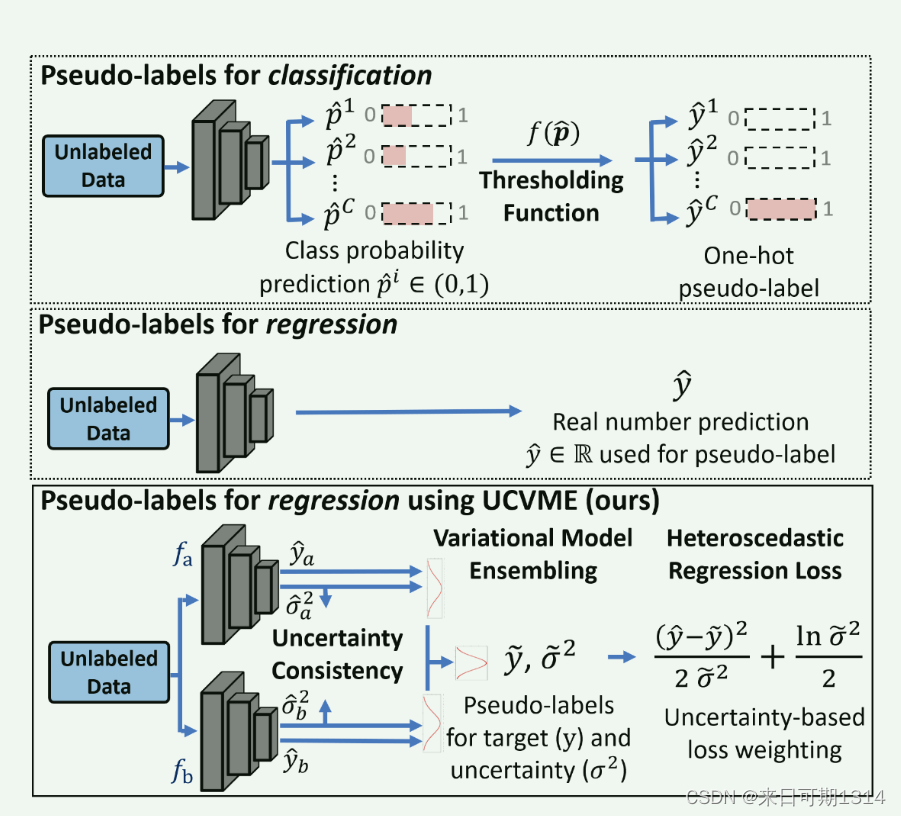 图1. 伪标签策略在分类和回归任务中的差异图。来自《Semi-Supervised Deep Regression with Uncertainty Consistency and Variational Model Ensembling via Bayesian Neural Networks》
图1. 伪标签策略在分类和回归任务中的差异图。来自《Semi-Supervised Deep Regression with Uncertainty Consistency and Variational Model Ensembling via Bayesian Neural Networks》
目前的工作中提出的是启发式策略,即不能证明这样一定是对的,但是感觉是对的。
COREG 提供了一个量化置信度,
δ x u = ∑ x i ∈ Ω u ( ( y i − h ( x i ) ) 2 − ( y i − h ′ ( x i ) ) 2 ) \delta_{\mathbf{x}_u} = \sum_{\mathbf{x}_i \in \Omega_u}((y_i-h(\mathbf{x}_i))^2-(y_i - h'(\mathbf{x}_i))^2) δxu=xi∈Ωu∑((yi−h(xi))2−(yi−h′(xi))2)。师兄的论文也基于这样的一个启发式置信度策略来设计。
MSSRA 也提供了一个置信度:由多个回归器对于样本预测的极值(最大值减去最小值)确定。其实这里还有一个问题,伪标签应该添加多少呢,COREG 设计了一个最大的迭代次数,如果没有能带来正提升的无标记样本,则提前停止。这里涉及到数量与质量的权衡,其实可以设计一个伪标签数量控制的策略。
其实,还有一种量化伪标签置信度的方法,不确定性。在聊不确定性之前,可以先了解一下点估计与区间估计。分类问题其实可以相当于点估计,那么回归问题相当于区间估计。
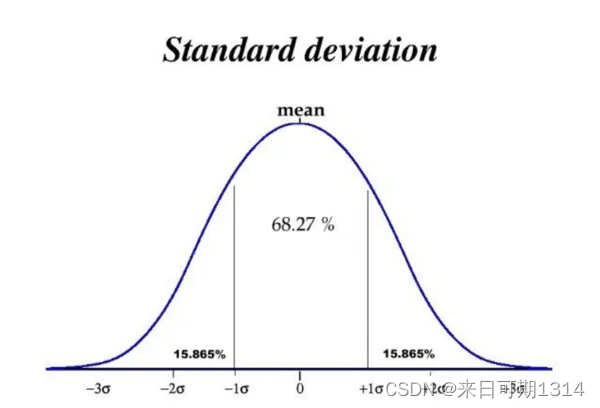
- 68% 的数据会落在 μ ± σ \mu \pm \sigma μ±σ 内,即数据分布在处于 ( μ − σ , μ + σ ) (\mu−\sigma, \mu+\sigma) (μ−σ,μ+σ)中的概率是 0.68
- 95% 的数据会落在 μ ± 2 σ \mu \pm 2\sigma μ±2σ 内,即数据分布在处于 ( μ − 2 σ , μ + 2 σ ) (\mu−2\sigma, \mu+2\sigma) (μ−2σ,μ+2σ)中的概率是 0.95
- 99% 的数据会落在 μ ± 3 σ \mu \pm 3\sigma μ±3σ 内,即数据分布在处于 ( μ − 3 σ , μ + 3 σ ) (\mu−3\sigma, \mu+3\sigma) (μ−3σ,μ+3σ)中的概率是 0.99
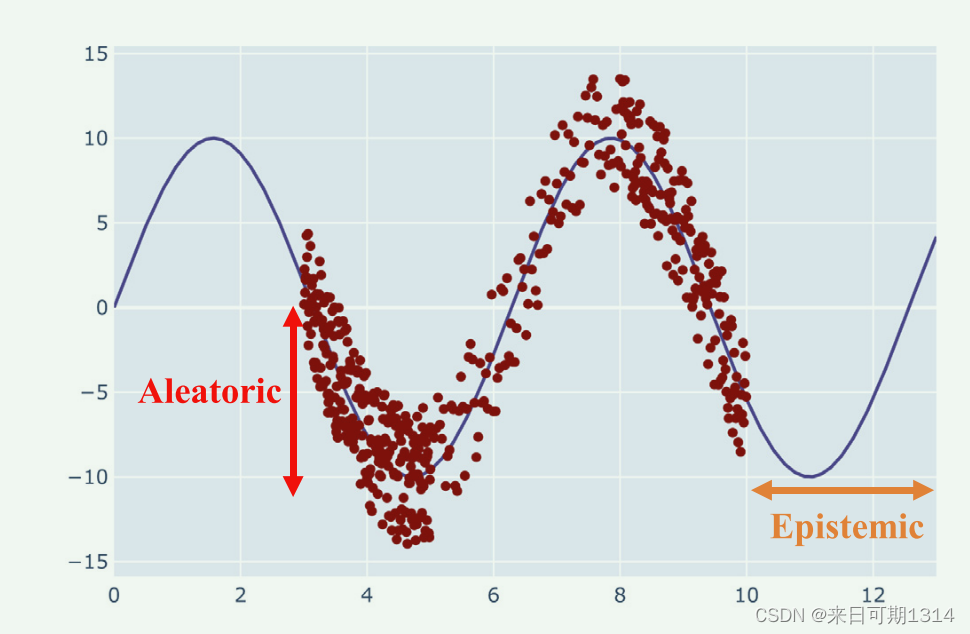
图3. 不确定性。来自《A review ofuncertainty quantification in deep learning: Techniques, applications and challenges》
这里就不细讲下去了,内容太多了。
除了刚刚讲到的伪标签,在半监督分类问题中一致性正则表现优秀。目前还没有找到有基于一致性正则的半监督回归工作。
C ( D u , w ) = 1 ∣ D u ∣ ∑ x i ∈ D u d ( f ( x i , w ) , T ( x ^ i ) ) \mathcal{C}(D_u, \mathbf{w}) = \frac{1}{|D_u|} \sum_{x_i \in D_u}d(f(x_i,\mathbf{w}), T(\hat{x}_i)) C(Du,w)=∣Du∣1xi∈Du∑d(f(xi,w),T(x^i))
其中, T ( x ^ i ) T(\hat{x}_i) T(x^i) 我更喜欢称为锚点,其实也相当于是伪标签,但是没有置信度的概念,相对于质量,更倾向于使用所有的无标记数据。由于 C ( D u , w ) \mathcal{C}(D_u, \mathbf{w}) C(Du,w) 没有携带标签信息,所有称之为正则。
2. 读论文技巧
三不读:
- 水刊论文不读
- 太难的论文也不读
- 同门师兄的论文不读
Trick1: 精读摘要。有时候只需要读完摘要就够了。
Trick2:Introduction 一般不用读,毕竟老板的八股指南说 Introduction 是摘要的详细描述,读了摘要就没必要读了。
Trick3:读完摘要带着问题去读。
Trick4:读最新的论文,即使和自己课题不是太相关。这一点主要是找idea的时候可以挂靠的理论。我们的创新主要是缝合(e.g. 李师兄就是将自步学习和协同训练结合在一起)。
3. 写论文技巧
-
老板的八股指南。
-
我的经验
-
写论文最大的难点就是有话说,其实我觉得老板说的对,先写下来,即使是废话。不用担心是废话,在论文的打磨过程会逐渐消失的。
-
每话说还有一个就是对自己处理的问题理解不够深刻。这一点可能有点解决方案:
- 可以读综述论文,增加对课题的整体了解。
- 组内讨论。
- 每周读一篇高质量论文,厚积薄发。
-
写论文时间安排不要阻塞。在实际情况中,跑实验会持续两周,不用等着实验结果在开始写论文。毕竟实验结果并不影响你描述你的算法,可以在编写算法描述章节边跑实验。
4. 代码工具
Experiment_SSR_k_fold断电重跑,解决实验室每天晚上断点问题,持久化实验跑的进度。StaticTestUtil.pyfridman 检验FileUtil.py/summaryCSVFilePlus汇总多个对比算法的实验结果。FileUtil.py/csv2LatexTablePlusPlus生成latex表格代码,剩去手动填写数据的时间。- 对比算法,COREG, SAFER,MSSRA,BHD,Self-kNN,S3VR
代码比较乱,主要是日常自己使用,后续没有考虑维护的问题。
5. 杂项
-
怎么给论文guanshui?
可以细读一下老板的八股指南。老板认为写论文就像是填写模板一样,每个地方都有应该要填写的东西。主要是有一个理论自洽的方案,比如说半监督学习,就是有一个利用无标记数据的方案。至于三点贡献,这也可以让老板帮你找,抱紧大腿总是没有问题的。 -
写论文需要公式,自己创造存在困难?
实际上是不用自己创造的。自己创造很难,那一般是前沿学者的工作。如果确实要到创造公式的地步,怀疑一下自己是不是没有挂靠成熟的理论。抛开前面的那些,写公式要先看别人的,在别人的基础上进行改动。存在一种情况,自己想表达的意思很简单,用语言两三句话就表述出来了,但是用数学语言表达困难,这就需要老板帮助了。
6. 总结
研究生生涯时间过得很快,有效时间其实只有研二的一年。最开始入学的时候很迷茫,不知道做些什么,伴随着还有很多课程,考试,留给自己的学习时间很少。最主要的是迷茫,没有目标体现出来就是这也想做那也想做,结果什么都没有做。这很可怕,研一应该快速的确定自己的课题,最好的是跟着老师,不然就是师兄,自己一个人单干难度加加(我就是这种情况,该踩的坑一个也没少)。研二就主要靠自觉了,早上的时间不能荒废(睡懒觉可不好),多读与课题相关的论文,同时写博客,不然容易忘记(白读)。尽量研二上学期就把小论文初稿写出来,但是这很难,但是不逼自己一把可不行。如果实在没有也应该放松心态,急也没用,只有慢慢的积累,没有人能帮你写。研三,就要考虑自己的就业或者继续深造,同样充满了焦虑。如果没出意外,应该有修改意见了,当然如果已经中了那就太好了,压力骤降。一个普遍的认知是有了修改意见那么机会就很大,要紧紧地抓住,即使是大修机会也很大。我在写下这篇博客的时候在研三的最后阶段了,找工作也很难😂,毕竟时间和努力都用在小论文上,都没时间锻炼编程能力了,可恶!