聚类分析 | Matlab实现基于PCA+DBO+K-means的数据聚类可视化
目录
- 聚类分析 | Matlab实现基于PCA+DBO+K-means的数据聚类可视化
- 效果一览
- 基本介绍
- 程序设计
- 参考资料
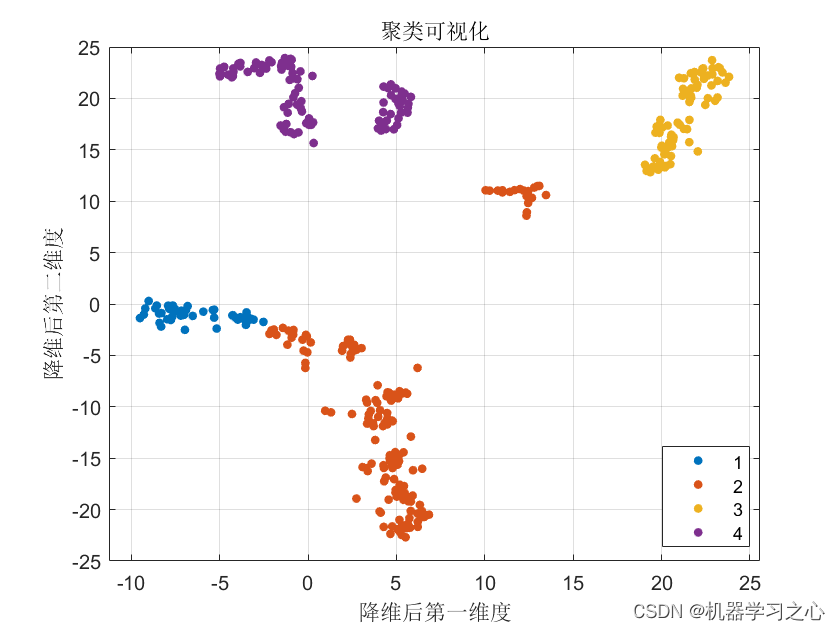
效果一览
基本介绍
PCA(主成分分析)、DBO(蜣螂优化算法)和K-means聚类是三种不同的数据处理和优化的方法,它们可以结合起来使用以改进聚类效果。下面是对这三种方法的简要介绍以及如何将它们结合使用的说明。
PCA(主成分分析)
PCA 是一种常用的数据降维方法。它通过对原始特征空间进行线性变换,找到一组新的正交特征(即主成分),这些主成分能够最大程度地保留原始数据中的方差。PCA 可以帮助去除数据中的噪声和冗余,提高后续聚类等任务的效果。
K-means聚类
K-means 是一种经典的聚类算法,它通过将数据划分为 K 个簇来工作。每个簇由其质心(即簇中所有点的均值)表示。K-means 算法通过迭代优化每个点的簇分配和簇质心的位置来工作,直到达到收敛或满足其他停止条件。
DBO(蜣螂优化算法)
DBO 是一种基于蜣螂觅食行为的优化算法。它模拟了蜣螂在寻找食物过程中的行为,通过不断滚动粪球(即优化问题的解)来寻找最优解。DBO 具有全局搜索能力强、收敛速度快等优点,适用于解决各种优化问题。
结合使用
将 PCA、DBO 和 K-means 结合使用可以进一步提高聚类的效果和效率。具体的步骤可能如下:
数据预处理与PCA降维:首先,对数据进行预处理,如去除异常值、填充缺失值等。然后,使用 PCA 对数据进行降维,以消除噪声和冗余,并提取主要特征。
K-means聚类初始化:使用降维后的数据进行 K-means 聚类。在这个阶段,可以使用 DBO 来优化 K-means 的初始化过程。具体来说,可以将 K-means 的初始质心作为优化问题的解,通过 DBO 算法来寻找更好的初始质心位置。
DBO优化K-means迭代:在 K-means 的迭代过程中,可以使用 DBO 来优化簇的分配和质心的位置。具体来说,可以将每个点的簇分配和簇质心的位置作为优化问题的解,通过 DBO 算法来寻找更好的解。
聚类结果评估与优化:最后,对聚类结果进行评估,如使用轮廓系数、Calinski-Harabasz 指数等指标。如果聚类效果不理想,可以调整 PCA 的参数、DBO 的参数或 K-means 的参数,并重复上述步骤进行优化。
通过这种方式,PCA 可以帮助减少数据的维度和噪声,DBO 可以优化 K-means 的初始化和迭代过程,从而提高聚类的效果和效率。然而,需要注意的是,这种结合使用的方法可能会增加计算的复杂性和时间成本,因此在实际应用中需要根据具体情况进行权衡和调整。
程序设计
- 完整源码和数据获取方式私信博主回复Matlab实现基于PCA+DBO+K-means的数据聚类可视化。
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行版权声明:本文为CSDN博主「机器学习之心」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/kjm13182345320/article/details/119920826
————————————————
版权声明:本文为CSDN博主「机器学习之心」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/kjm13182345320/article/details/119920826
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/129215161
[2] https://blog.csdn.net/kjm13182345320/article/details/128105718