文章目录
- fork函数
- fork如何返回两个值(fork的工作原理)
- 如何解释父子进程相互输出printf
- 写时拷贝
fork函数
#include <unistd.h>
pid_t fork(void);
返回值:自进程中返回0,父进程返回子进程id,出错返回-1
fork函数是一个Unix/Linux系统中常用的系统调用,用于创建一个新的进程,新进程称为子进程,原进程称为父进程。fork函数的工作原理是将父进程的内存空间完全复制一份给子进程,包括代码段、数据段、堆栈等,但是子进程会有自己独立的进程ID(PID)。
fork函数会 返回两次 ,在父进程中返回子进程的PID,在子进程中返回0。如果创建失败则返回一个-1。返回值的类型为pid_t,实质是int.
一个函数调用一次但是可以返回两次值,这是令人感到奇怪的,我们可以通过代码来观察该现象
观察以下代码:
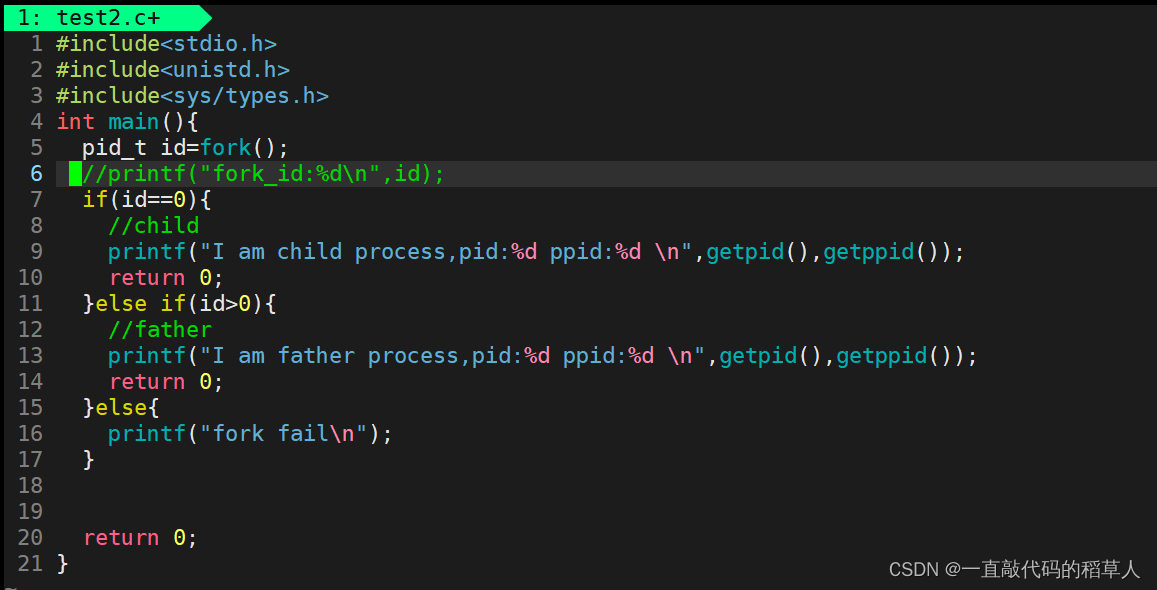

我们可以发现,fork函数确实返回了两个值,对于父进程而言,拿到的的就是子进程的pid.对于新建立出来的子进程来说,fork返回值就是0.(27502是bash进程)
对于该相象,我们提出疑问:
fork如何返回两个值(fork的工作原理)
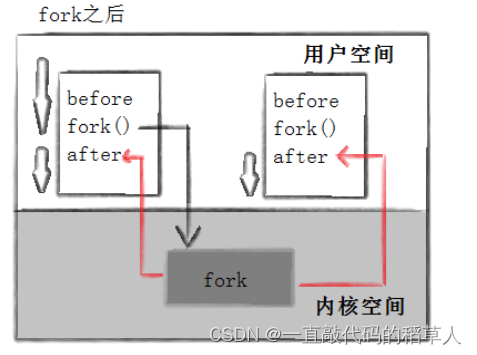
我们将代码以fork函数为界限,划分为上下两个部分,before和after。创建子进程后子进程会向下开始执行after代码,并不会执行before。在fork内部,执行了一部分代码的时候,子进程已经被建立。几乎是瞬间,子进程被调度,父子进程并发往后执行代码,所以return会执行两次。
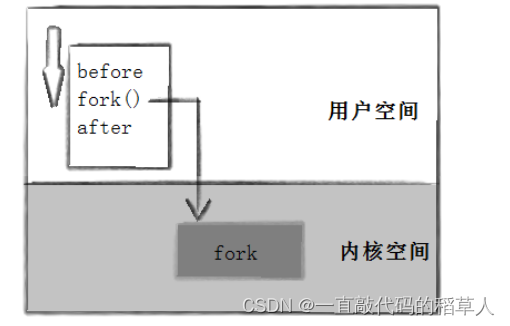
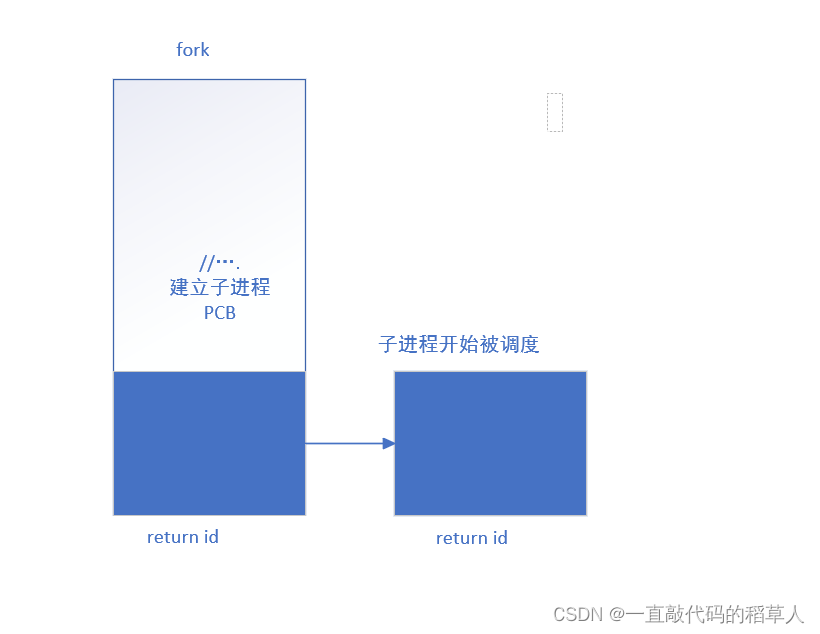
当代码执行到fork函数时,由于fork函数是一个系统调用,这个时候需要由linux内核来创建一个子进程,子进程获得与父进程用户级虚拟地址空间相同的(但是独立的)一份副本,包括父进程的栈、数据段、堆和代码,并申请一个PCB。
完成这个工作后,子进程也就有了自己的一个PID,fork函数就会将这个PID立即返回给父进程。因为子进程的PID总是非0的,返回值就提供一个明确的方法来分辨程序是在父进程还是在在子进程中执行。所以给子进程返回一个0.
注意,父进程和子进程是并发运行的独立进程,执行的先后顺序由系统的调度算法决定。虽然上述例子是先执行父进程的printf,但是在其它系统上可能不一样
如何解释父子进程相互输出printf
用fork创建出来的子进程与父进程共享文件。我们注意到以上例子中,父进程和子进程程都把他们的输出显示在屏幕文件中。原因是子进程继承了父进程的所有的打开文件。当父进程调用fork时,stdout(标准输出流)文件是打开的,并指向屏幕。子进程继承了这个文件,因此它的输出也是指向屏幕的。
我们可以画进程图来帮助我们理解
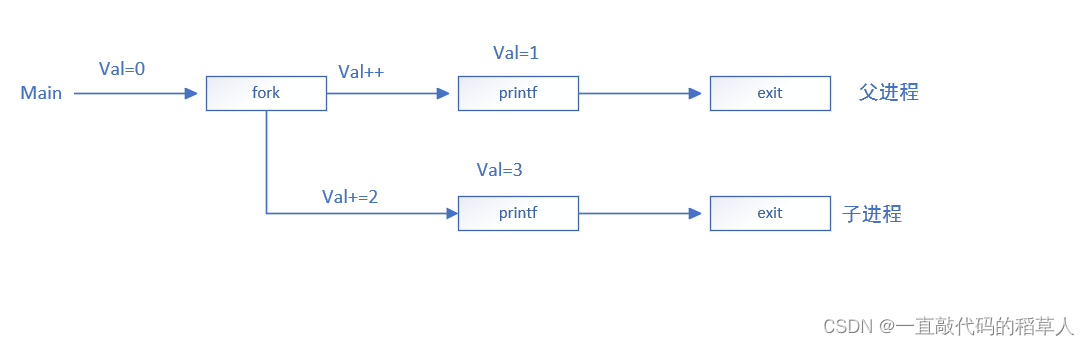
观察现象2:
观察以下代码
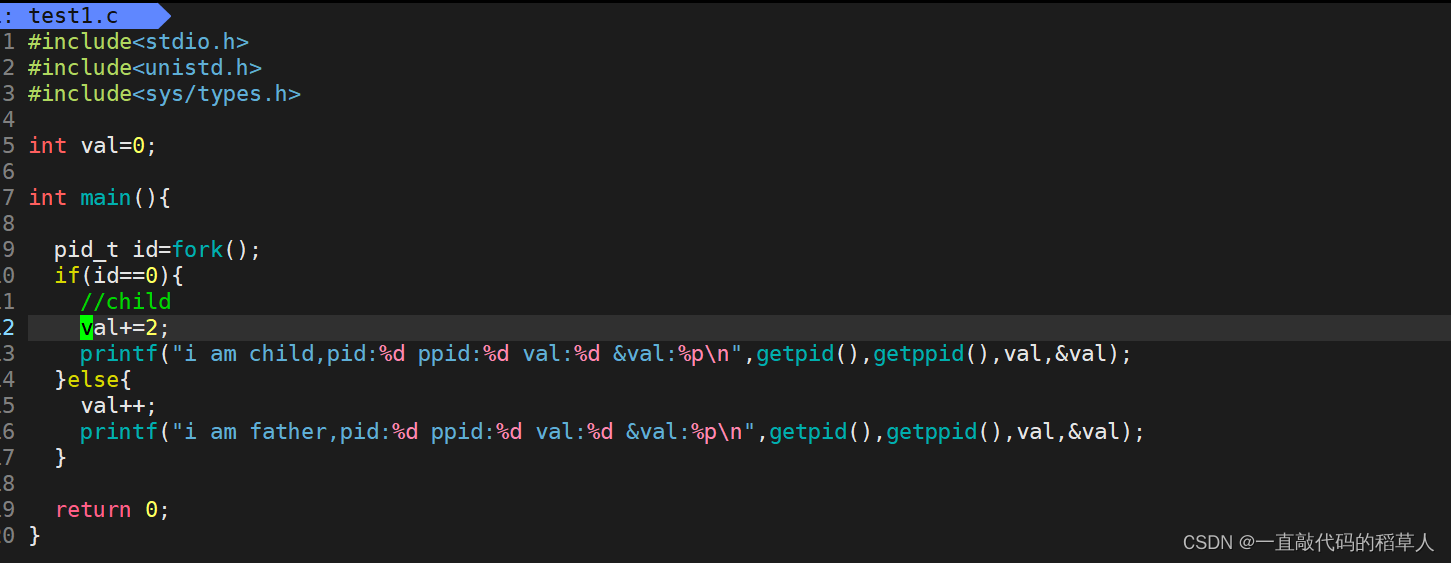

通过以上例子我们可以得到结论:
1.父子进程的具有相同但是独立的地址空间。在创建子进程时,本地变量val在父进程中和在子进程中都是0。后面因为父进程和子进程是独立的进程,它们都有自己私有的地址空间。无论是父进程还是子进程对val的任何改变都是独立的,不会放映到另一个进程的内存中。这也可以解释为什么父进程和子进程调用它们各自的printf语句时,他们的变量val会有不同的值。
2.虽然父子进程的变量的虚拟地址相同,但是映射的物理地址不同。这也是为什么父子进程的val地址相同,值却不同。发生了写时拷贝。
写时拷贝
写时拷贝,又叫写时复制(Copy-on-write,简称COW)。是一种计算机程序设计领域的优化策略。其核心思想是,如果多个调用者同时请求同一个资源,比如内存中的存储数据,它们会获得相同的指针来指向相同的资源。如果有一个进程想要修改其内容,为了避免影响其它进程,系统这个时候才会真正的复制一份相同的资源给该进程。其它进程所指向的该资源依旧保持不变。这种机制一定程度上减少了系统拷贝资源的次数。只要进程没有修改该资源,就不会有副本被创建,因此多个调用者只是读取操作时可以共享同一份资源。
再次回到第二个例子中:
当使用fork创建子进程的时候,子进程获得父进程的一份用户级的虚拟地址空间相同的一份副本。根据写时拷贝的机制,此时系统并不会马上给子进程深拷贝父进程的资源,而是先给子进程共享同一片地址空间,并将该页面标记为只读。一旦父进程或者是子进程对该空间进行写入操作,系统才会真正的拷贝一份副本。