内建函数
这篇我们来看看什么是内建函数欸?
什么是内建函数
内建函数,顾名思义,就是编译器内部实现的函数。**这些函数和关键字一样,可以直接调用,**无须像标准库函数那样,要先声明后使用。
**内建函数的函数命名,通常以__builtin开头。**这些函数主要在编译器内部使用,主要是为编译器服务的。内建函数的主要用途如下。
● 用来处理变长参数列表。
● 用来处理程序运行异常、编译优化、性能优化。
● 查看函数运行时的底层信息、堆栈信息等。
● 实现C标准库的常用函数。
因为内建函数是在编译器内部定义的,主要供与编译器相关的工具和程序调用,所以这些函数并没有文档说明,而且变动又频繁,对于应用程序开发者来说,不建议使用这些函数。
但有些函数,对于我们了解程序运行的底层机制、编译优化很有帮助,在Linux内核中也经常使用这些函数,所以我们很有必要了解Linux内核中常用的一些内建函数。
常用的内建函数
·常用的内建函数主要有两个:__builtin_return_address()和__builtin_frame_address()。
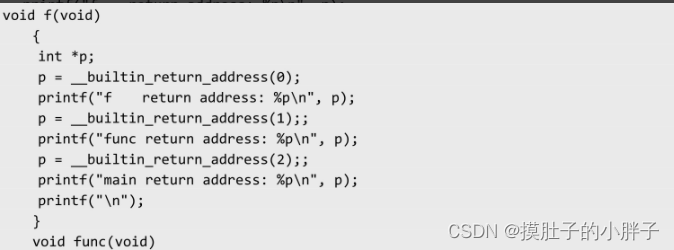
__builtin_return_address(LEVEL)
这个函数用来返回当前函数或调用者的返回地址。函数的参数LEVEL表示函数调用链中不同层级的函数。
● 0:获取当前函数的返回地址。
● 1:获取上一级函数的返回地址。
● 2:获取上二级函数的返回地址。
● ……
整个栗子看看

__builtin_frame_address(LEVEL)
在这个之前需要知道栈帧这个概念:
函数每调用一次,都会将当前函数的现场(返回地址、寄存器、临时变量等)保存在栈中,每一层函数调用都会将各自的现场信息保存在各自的栈中。
这个栈就是当前函数的栈帧,每一个栈帧都有起始地址和结束地址,多层函数调用就会有多个栈帧,每个栈帧都会保存上一层栈帧的起始地址,这样各个栈帧就形成了一个调用链。
很多调试器其实都是通过回溯函数的栈帧调用链来获取函数底层的各种信息的,如返回地址、调用关系等。
在ARM处理器平台下,一般使用FP和SP这两个寄存器,分别指向当前函数栈帧的起始地址和结束地址。
当函数继续调用其他函数,或运行结束返回上一级函数时,这两个寄存器的值也会发生变化,总是指向当前函数栈帧的起始地址和结束地址。
我们可以通过内建函数__builtin_frame_address(LEVEL)查看函数的栈帧地址。
● 0:查看当前函数的栈帧地址。
● 1:查看上一级函数的栈帧地址。
● ……


C标准库的内建函数
在GNU C编译器内部,C标准库的内建函数实现了一些与C标准库函数类似的内建函数。
这些函数与C标准库函数功能相似,函数名也相同,只是在前面加了一个前缀__builtin。
如果你不想使用C标准库函数,也可以加一个前缀,直接使用对应的内建函数。
常见的C标准库函数如下:
● 与内存相关的函数:memcpy()、memset()、memcmp()。
● 数学函数:log()、cos()、abs()、exp()。
● 字符串处理函数:strcat()、strcmp()、strcpy()、strlen()。
● 打印函数:printf()、scanf()、putchar()、puts()。
下面我们写一个小程序,使用与C标准库对应的内建函数。
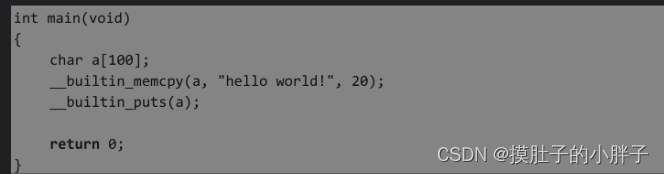
编译程序并运行,程序运行结果如下。

使用与C标准库对应的内建函数,同样能实现字符串的复制和打印,实现C标准库函数的功能。
内建函数:__builtin_constant_p(n)
编译器内部还有一些内建函数主要用来编译优化、性能优化。
__builtin_constant_p(n) 函数
该函数主要用来判断参数n在编译时是否为常量。如果是常量,则函数返回1,否则函数返回0。
该函数常用于宏定义中,用来编译优化。一个宏定义,根据宏的参数是常量还是变量,可能实现的方法不一样。
来看看内核源码中的花里胡哨的宏:


很多宏的操作在参数为常数时可能有更优化的实现,在这个宏定义中,我们实现了2个版本。
根据参数是否为常数,我们可以灵活选用不同的版本。
内建函数:__builtin_expect(exp,c)
内建函数__builtin_expect()也常常用来编译优化,这个函数有2个参数,返回值就是其中一个参数,仍是exp。
这个函数的意义主要是告诉编译器:参数exp的值为c的可能性很大,然后编译器可以根据这个提示信息,做一些分支预测上的代码优化。
参数c与这个函数的返回值无关,无论c为何值,函数的返回值都是exp。

这个函数的主要用途是编译器的分支预测优化。
现在CPU内部都有Cache缓存器件。CPU的运行速度很高,而外部RAM的速度相对来说就低了不少,所以当CPU从内存RAM读写数据时就会有一定的性能瓶颈。为了提高程序执行效率,CPU一般都会通过Cache这个CPU内部缓冲区来缓存一定的指令或数据,当CPU读写内存数据时,会先到Cache看看能否找到:如果找到就直接进行读写;如果找不到,则Cache会重新缓存一部分数据进来。CPU读写Cache的速度远远大于内存RAM,所以通过这种缓存方式可以提高系统的性能。
那么Cache如何缓存内存数据呢? **简单来说,就是依据空间相近原则。**如CPU正在执行一条指令,那么在下一个时钟周期里,CPU一般会大概率执行当前指令的下一条指令。如果此时Cache将下面的几条指令都缓存到Cache里,则下一个时钟周期里,CPU就可以直接到Cache里取指、译指和执行,从而使运算效率大大提高。
但有时候也会出现意外。如程序在执行过程中遇到函数调用、if分支、goto跳转等程序结构,会跳到其他地方执行,原先缓存到Cache里的指令不是CPU要执行的指令。此时,我们就说Cache没有命中,Cache会重新缓存正确的指令代码供CPU读取,这就是Cache工作的基本流程。
**有了这些理论基础,我们在编写程序时,遇到if/switch这种选择分支的程序结构,一般建议将大概率发生的分支写在前面。**当程序运行时,因为大概率发生,所以大部分时间就不需要跳转,程序就相当于一个顺序结构,Cache的缓存命中率也会大大提升。
内核中已经实现一些相关的宏,如likely和unlikely,用来提醒程序员优化程序。
Linux内核中的likely和unlikely
在Linux内核中,使用__builtin_expect()内建函数,定义了两个宏。
#define likely(x) __builtin_expect(!!(x),1);
#define unlikely(x) __builtin_expect(!!(x),0);
这两个宏的主要作用:告诉编译器某一个分支发生的概率很高,或者很低,基本不可能发生。编译器根据这个提示信息,在编译程序时就会做一些分支预测上的优化。
在这两个宏的定义中有一个细节,就是对宏的参数x做两次取非操作,这是为了将参数x转换为布尔类型,然后与1和0直接做比较,告诉编译器x为真或假的可能性很高。
在Linux内核源码中,你会发现很多地方使用likely和unlikely宏进行修饰。