作者:来自 Elastic Garson
Elasticsearch 内的索引 (index) 是你可以将数据存储在文档中的位置。 在使用索引时,如果你使用的是动态数据集,数据可能会很快变旧。 为了避免此问题,你可以创建一个 Python 脚本来更新索引,并使用 Google Cloud Platform (GCP) 的 Cloud Functions 和 Cloud Scheduler 进行部署,以便自动保持索引最新。
为了使索引保持最新,你可以首先设置一个 Jupyter Notebook 在本地进行测试,并创建一个脚本框架,该脚本框架将在出现新信息时更新你的索引。 你可以调整脚本以使其更具可重用性并将其作为云函数(Cloud function)运行。 使用 Cloud Scheduler,你可以将 Cloud Function 中的代码设置为使用 cron 类型格式按计划运行。
先决条件
- 本示例使用 Elasticsearch 版本 8.12; 如果你是新手,请查看我们的 Elasticsearch 快速入门。
- 如果你的计算机上尚未安装 Python,请下载最新版本。 此示例使用 Python 3.12.1。
- NASA API 的 API 密钥。
- 你将使用 Requests 包连接到 NASA API,使用 Pandas 操作数据,使用 Elasticsearch Python 客户端将数据加载到索引中并使其保持最新,并使用 Jupyter Notebooks 在测试时以交互方式处理数据。 你可以运行以下行来安装这些必需的软件包:
pip3 install requests pandas elasticsearch notebook加载和更新你的数据集
在 GCP 内运行更新脚本之前,你需要上传数据并测试用于保持脚本更新的流程。 你将首先从 API 连接到数据,将其保存为 Pandas DataFrame,连接到 Elasticsearch,将 DataFrame 上传到索引中,检查索引上次更新的时间,并在有新数据可用时更新索引。 你可以在此搜索实验室笔记本中找到本节的完整代码。
加载你的数据
让我们开始使用 Jupyter Notebook 进行本地测试,以交互方式处理你的数据。 为此,你可以在终端中运行以下命令。
jupyter notebook在右上角,你可以选择 “New” 来创建新的 Jupyter Notebook。
首先,你需要导入将要使用的包。 你将导入之前安装的所有软件包,以及用于处理 API 密钥等机密的 getpass 和用于处理日期对象的 datetime。
import requests
from getpass import getpass
import pandas as pd
from datetime import datetime, timedelta
from elasticsearch import Elasticsearch, helpers你将使用的数据集是近地天体 Web 服务 (NeoWs),这是一种提供近地小行星信息的 RESTful Web 服务。 该数据集可让你根据小行星最接近地球的日期搜索小行星、查找特定小行星并浏览整个数据集。
通过以下函数,你可以连接到 NASA 的 NeoWs API,获取过去一周的数据,并将响应转换为 JSON 对象。
def connect_to_nasa():url = "https://api.nasa.gov/neo/rest/v1/feed"nasa_api_key = getpass("NASA API Key: ")today = datetime.now()params = {"api_key": nasa_api_key,"start_date": today - timedelta(days=7),"end_date": datetime.now(),}return requests.get(url, params).json()现在,你可以将 API 调用的结果保存到名为 “response” 的变量中。
要将 JSON 对象转换为 pandas DataFrame,你必须将嵌套对象规范化为一个 DataFrame,并删除包含嵌套 JSON 的列。
def create_df(response):all_objects = []for date, objects in response["near_earth_objects"].items():for obj in objects:obj["close_approach_date"] = dateall_objects.append(obj)df = pd.json_normalize(all_objects)return df.drop("close_approach_data", axis=1)
要调用此函数并查看数据集的前五行,你可以运行以下命令:
df = create_df(response)
df.head()连接到 Elasticsearch
你可以通过提供 Elastic Cloud ID 和 API 密钥进行身份验证,从 Python 客户端访问 Elasticsearch。
def connect_to_elastic():elastic_cloud_id = getpass("Elastic Cloud ID: ")elastic_api_key = getpass("Elastic API Key: ")return Elasticsearch(cloud_id=elastic_cloud_id, api_key=elastic_api_key)现在,你可以将连接函数的结果保存到名为 es 的变量中。
es = connect_to_elastic()Elasticsearch 中的索引是数据的主要容器。 你可以将索引命名为 asteroid_data_set。
index_name = "asteroid_data_set"
es.indices.create(index=index_name)你返回的结果将如下所示:
ObjectApiResponse({'acknowledged': True, 'shards_acknowledged': True, 'index': 'asteroids_data'})现在,你可以创建一个辅助函数,该函数允许你将 DataFrame 转换为正确的格式以上传到索引中。
def doc_generator(df, index_name):for index, document in df.iterrows():yield {"_index": index_name,"_id": f"{document['id']}","_source": document.to_dict(),}接下来,你可以将 DataFrame 的内容批量上传到 Elastic,调用您刚刚创建的辅助函数。
helpers.bulk(es, doc_generator(df, index_name))你应该得到类似于以下内容的结果,它告诉你已上传的行数:
(146, [])你最后一次更新数据是什么时候?
将数据上传到 Elasticsearch 后,你可以检查上次更新索引的时间并设置日期格式,以便它可以与 NASA API 配合使用。
def updated_last(es, index_name):query = {"size": 0,"aggs": {"last_date": {"max": {"field": "close_approach_date"}}},}response = es.search(index=index_name, body=query)last_updated_date_string = response["aggregations"]["last_date"]["value_as_string"]datetime_obj = datetime.strptime(last_updated_date_string, "%Y-%m-%dT%H:%M:%S.%fZ")return datetime_obj.strftime("%Y-%m-%d")你可以将索引上次更新的日期保存到变量中并打印出该日期。
last_update_date = updated_last(es, index_name)
print(last_update_date)更新你的数据
现在,你可以创建一个函数来检查自上次更新索引和当前日期以来是否有任何新数据。 如果对象有效并且数据不为空,它将更新索引并让你知道是否没有新数据要更新,或者 DataFrame 是否返回 None 类型,表明可能存在问题。
def update_new_data(df, es, last_update_date, index_name):if isinstance(last_update_date, str):last_update_date = datetime.strptime(last_update_date, "%Y-%m-%d")last_update_date = pd.Timestamp(last_update_date).normalize()if not df.empty and "close_approach_date" in df.columns:df["close_approach_date"] = pd.to_datetime(df["close_approach_date"])today = pd.Timestamp(datetime.now().date()).normalize()if df is not None and not df.empty:update_range = df.loc[(df["close_approach_date"] > last_update_date)& (df["close_approach_date"] < today)]if not update_range.empty:helpers.bulk(es, doc_generator(update_range, index_name))else:print("No new data to update.")else:print("The DataFrame is None.")如果 DataFrame 是有效对象,它将调用你编写的函数并更新索引(如果适用)。 它还会打印出索引上次更新的日期,以帮助你在需要时进行调试。 如果没有,它会告诉你可能有问题。
try:if df is None:raise ValueError("DataFrame is None. There may be a problem.")update_new_data(df, es, last_update_date, index_name)print(updated_last(es, index_name))
except Exception as e:print(f"An error occurred: {e}")保持索引最新
现在你已经创建了用于本地测试的框架,你可以设置一个环境,你可以每天运行脚本来检查是否有任何新数据可用并相应地更新索引。
创建云函数
你现在已准备好部署云功能。 为此,你需要选择环境作为第二代函数,命名你的函数,然后选择云区域。 你还可以将其绑定到 Cloud Pub/Sub 触发器,并选择创建新主题(如果你尚未创建)。 你可以在 GitHub 上查看本节的完整代码。
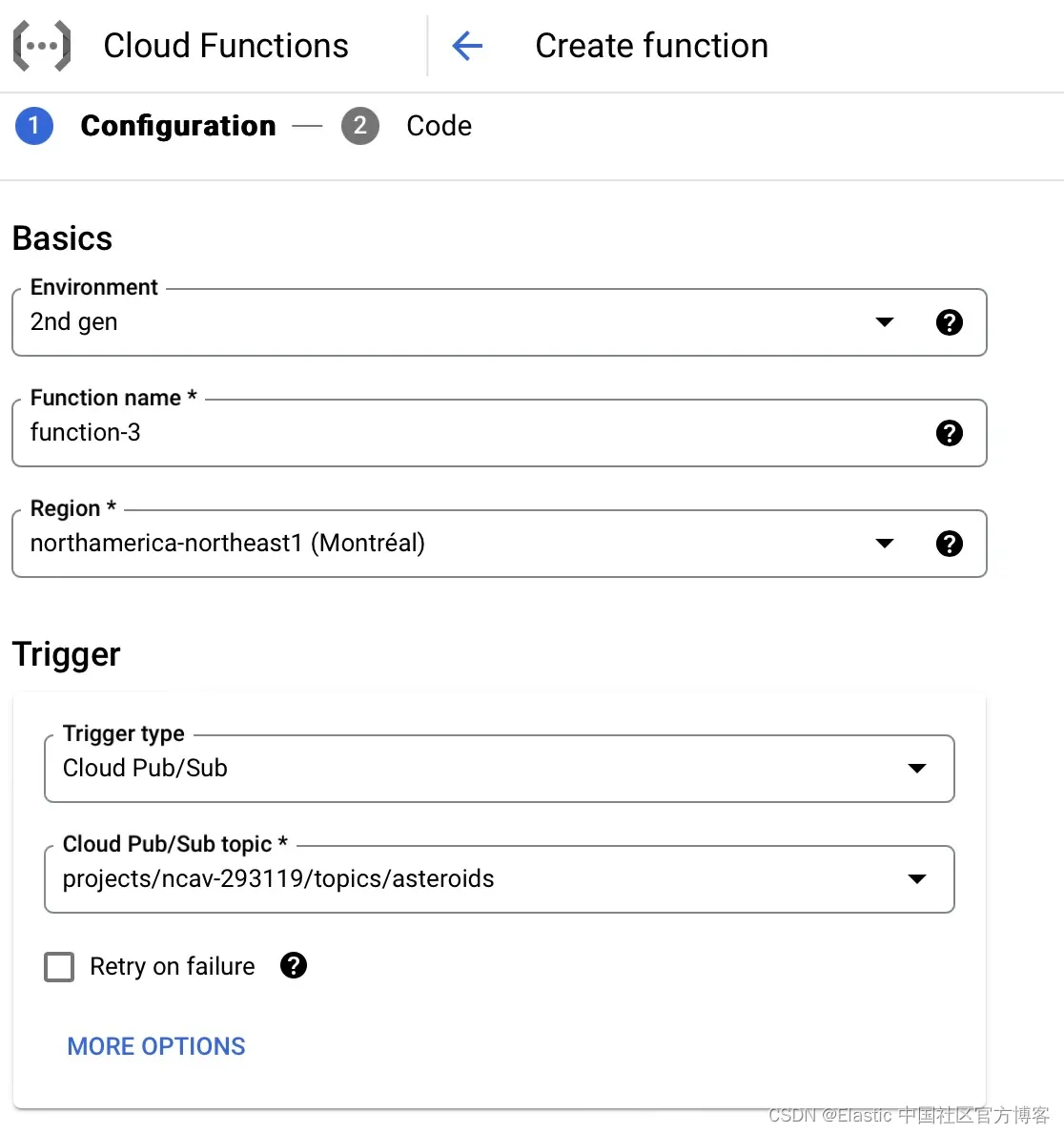
创建 Pub/Sub 主题
创建新主题时,你可以命名主题 ID 并选择使用 Google 管理的加密密钥进行加密。

设置 Cloud Function 的环境变量
在 “Runtime environment variables” 下方,你可以添加 NASA_API_KEY、ELASTIC_CLOUD_ID 和 ELASTIC_API_KEY 的环境变量。 你需要将它们保存为原始值,并且不带单引号。 因此,如果你之前在终端中输入了 “xxxlsdgzxxxxx” 值,你会希望它是 xxxlsdgzxxxxx。
调整你的代码并将其添加到你的云函数
输入环境变量后,你可以按 “下一步(next)” 按钮,这将带你进入代码编辑器。 你需要选择 Python 3.12.1 的运行时或匹配你正在使用的 Python 版本。 之后,将入口点更新为 update_index。 入口点的作用与 Python 中的 main 函数类似。
你将希望使用 os 来执行更自动化的过程,而不是使用 getpass 来获得环境变量(账号信息)。 示例如下所示:
elastic_cloud_id = os.getenv("ELASTIC_CLOUD_ID")
elastic_api_key = os.getenv("ELASTIC_API_KEY")你需要调整脚本的顺序,以使函数首先连接到 Elasticsearch。 之后,你将想知道索引上次更新的时间,连接到你正在使用的 NASA API,将其保存到 DataFrame,并加载可能可用的任何新数据。
你可能会注意到底部有一个名为 update_index 的新函数,它将你的代码联系在一起。 在此函数中,你定义索引的名称,连接到 Elasticsearch,计算出索引的最后更新日期,连接到 NASA API,将结果保存到数据框中,并在需要时更新索引。 要指示入口点函数是云事件,你可以使用装饰器 @functions_framework.cloud_event 来表示它。
@functions_framework.cloud_event
def update_index(cloud_event):index_name = "asteroid_data_set"es = connect_to_elastic()last_update_date = updated_last(es, index_name)print(last_update_date)response = connect_to_nasa(last_update_date)df = create_df(response)if df is not None:update_new_data(df, es, last_update_date, index_name)print(updated_last(es, index_name)) else:print("No new data was retrieved.")这是完整更新的代码示例:
import functions_framework
import requests
import os
import pandas as pd
from datetime import datetime
from elasticsearch import Elasticsearch, helpersdef connect_to_elastic():elastic_cloud_id = os.getenv("ELASTIC_CLOUD_ID")elastic_api_key = os.getenv("ELASTIC_API_KEY")return Elasticsearch(cloud_id=elastic_cloud_id, api_key=elastic_api_key)def connect_to_nasa(last_update_date):url = "https://api.nasa.gov/neo/rest/v1/feed"nasa_api_key = os.getenv("NASA_API_KEY")params = {"api_key": nasa_api_key,"start_date": last_update_date,"end_date": datetime.now(),}return requests.get(url, params).json()def create_df(response):all_objects = []for date, objects in response["near_earth_objects"].items():for obj in objects:obj["close_approach_date"] = dateall_objects.append(obj)df = pd.json_normalize(all_objects)return df.drop("close_approach_data", axis=1)def doc_generator(df, index_name):for index, document in df.iterrows():yield {"_index": index_name,"_id": f"{document['close_approach_date']}","_source": document.to_dict(),}def updated_last(es, index_name):query = {"size": 0,"aggs": {"last_date": {"max": {"field": "close_approach_date"}}},}response = es.search(index=index_name, body=query)last_updated_date_string = response["aggregations"]["last_date"]["value_as_string"]datetime_obj = datetime.strptime(last_updated_date_string, "%Y-%m-%dT%H:%M:%S.%fZ")return datetime_obj.strftime("%Y-%m-%d")def update_new_data(df, es, last_update_date, index_name):if isinstance(last_update_date, str):last_update_date = datetime.strptime(last_update_date, "%Y-%m-%d")last_update_date = pd.Timestamp(last_update_date).normalize()if not df.empty and "close_approach_date" in df.columns:df["close_approach_date"] = pd.to_datetime(df["close_approach_date"])today = pd.Timestamp(datetime.now().date()).normalize()if df is not None and not df.empty:update_range = df.loc[(df["close_approach_date"] > last_update_date)& (df["close_approach_date"] < today)]print(update_range)if not update_range.empty:helpers.bulk(es, doc_generator(update_range, index_name))else:print("No new data to update.")else:print("The DataFrame is empty or None.")# Triggered from a message on a Cloud Pub/Sub topic.
@functions_framework.cloud_event
def hello_pubsub(cloud_event):index_name = "asteroid_data_set"es = connect_to_elastic()last_update_date = updated_last(es, index_name)print(last_update_date)response = connect_to_nasa(last_update_date)df = create_df(response)try:if df is None:raise ValueError("DataFrame is None. There may be a problem.")update_new_data(df, es, last_update_date, index_name)print(updated_last(es, index_name))except Exception as e:print(f"An error occurred: {e}")添加 requirements.txt 文件
你还需要定义一个requirements.txt 文件,其中包含运行代码所需的所有指定包。
functions-framework==3.*
requests==2.31.0
elasticsearch==8.12.0
pandas==2.1.4调度你的云函数
在 Cloud Scheduler 中,你可以将函数设置为使用 unix cron 格式定期运行。 我将代码设置为每天早上 8 点在我的时区运行。

你还需要配置执行以连接到你之前创建的 Pub/Sub 主题。 我目前将消息正文设置为 “hello”。

现在你已经设置了 Pub/Sub 主题和 Cloud Function 并将该 Cloud Function 设置为按计划运行,只要出现新数据,你的索引就会自动更新。
结论
使用 Python、Google Cloud Platform Functions 和 Google Cloud Scheduler,你应该能够确保定期更新索引。 你可以在此处找到完整的代码以及用于本地测试的搜索实验室笔记本。 我们还与 Google Cloud 一起举办了一场点播网络研讨会,如果你想构建搜索应用程序,这可能是一个不错的下一步。 如果你基于此博客构建了任何内容,或者如果你对我们的讨论论坛和社区 Slack 频道有疑问,请告诉我们。