分布式场景下,需要保证每一个服务拿到的id是唯一的。本文讨论、分析、总结了一些常见的分布式ID生成方案
结论:技术上没有银弹,每种分布式id都有自己的使用场景。uuid适用于业务比较简单,对性能没有太高追求等。 目前主流是 基于数据库的号段模式,雪花算法、以及雪花算法的改进版本。
UUID
UUID全程是 Universally Unique Identifier。字面意思:全球唯一的标识。 UUID 是一种由标准化的算法生成的 128 位数字,它在理论上是全球唯一的。UUID 可以通过不同的算法生成,其中最常见的是基于时间戳和节点信息生成的版本 1 UUID 和基于随机数生成的版本 4 UUID。
有什么特点?
- 足够的简单,java原生自带。本地生成具有唯一性。
- 缺点:不是自增的。不具备趋势递增性。没有具体的业务含义。长度比较大,浪费空间。
基于数据库
使用一个单独的数据库实例去生成。访问量剧增,mysql本身就是瓶颈。单点风险。
数据库集群。
多个db。使用不常。这样就可以确保每一个db生成的都是不重复的。
比如3个db实例,db1 从1开始生成,每次自增3。db2从2,每次自增3。这样就能保证唯一性。
- 致命缺点:不利于后续扩容(几乎很少去使用)
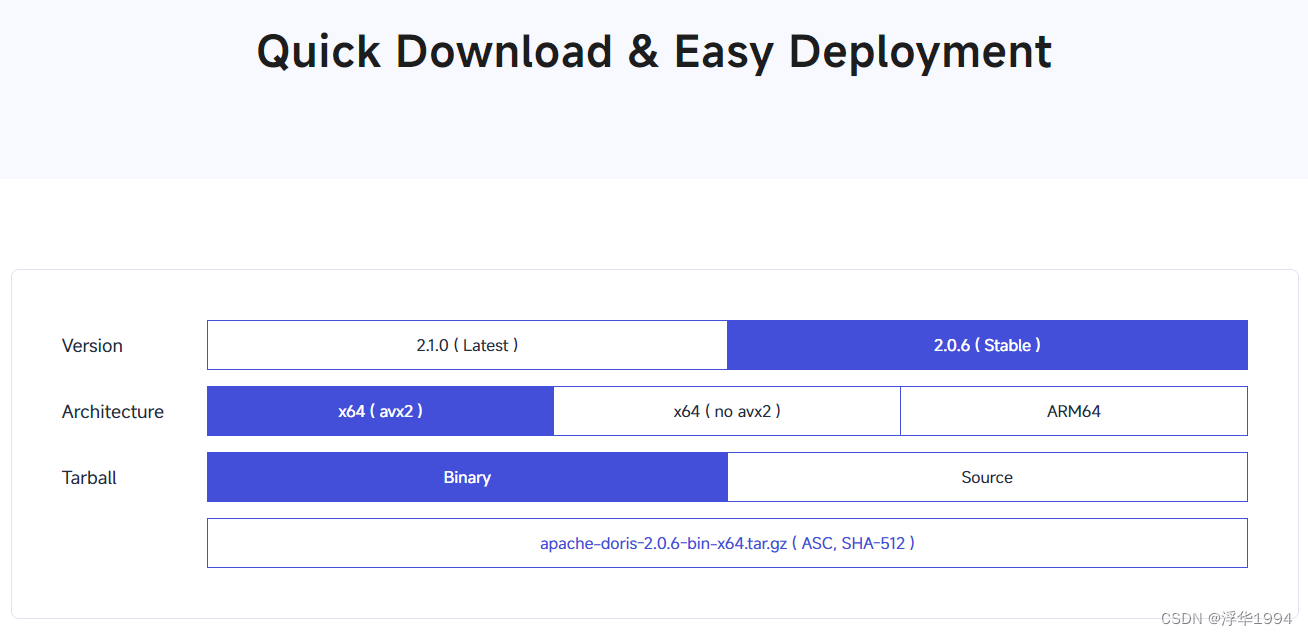
基于数据库的号段模式(重点)
号段模式是当下分布式ID生成器的主流实现方式之一,号段模式可以理解为从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,具体的业务服务将本号段,生成1~1000的自增ID并加载到内存。表结构如下:
CREATE TABLE id_generator (
id int(10) NOT NULL,
max_id bigint(20) NOT NULL COMMENT ‘当前最大id’,
step int(20) NOT NULL COMMENT ‘号段的布长’,
biz_type int(20) NOT NULL COMMENT ‘业务类型’,
version int(20) NOT NULL COMMENT ‘版本号’,
PRIMARY KEY (id)
)
biz_type :代表不同业务类型
max_id :当前最大的可用id
step :代表号段的长度
version :是一个乐观锁,每次都更新version,保证并发时数据的正确性
等这批号段ID用完,再次向数据库申请新号段,对max_id字段做一次update操作,update max_id= max_id + step,update成功则说明新号段获取成功,新的号段范围是(max_id ,max_id +step]。
update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX
由于多业务端可能同时操作,所以采用版本号version乐观锁方式更新,这种分布式ID生成方式不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多。
雪花算法
雪花算法(Snowflake)是twitter公司内部分布式项目采用的ID生成算法,开源后广受国内大厂的好评,在该算法影响下各大公司相继开发出各具特色的分布式生成器。

Snowflake生成的是Long类型的ID,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特。
Snowflake ID组成结构:正数位(占1比特)+ 时间戳(占41比特)+ 机器ID(占5比特)+ 数据中心(占5比特)+ 自增值(占12比特),总共64比特组成的一个Long类型。
第一个bit位(1bit):Java中long的最高位是符号位代表正负,正数是0,负数是1,一般生成ID都为正数,所以默认为0。
时间戳部分(41bit):毫秒级的时间,不建议存当前时间戳,而是用(当前时间戳 - 固定开始时间戳)的差值,可以使产生的ID从更小的值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年
工作机器id(10bit):也被叫做workId,这个可以灵活配置,机房或者机器号组合都可以。
序列号部分(12bit),自增值支持同一毫秒内同一个节点可以生成4096个ID
根据这个算法的逻辑,只需要将这个算法用Java语言实现出来,封装为一个工具方法,那么各个业务应用可以直接使用该工具方法来获取分布式ID,只需保证每个业务应用有自己的工作机器id即可,而不需要单独去搭建一个获取分布式ID的应用。
nowFlake可以保证:
优缺点:
- 同一台服务器所有生成的id按时间趋势递增
整个分布式系统内不会产生重复id(因为有datacenterId和workerId来做区分)
存在的问题: - 机器ID(5位)和数据中心ID(5位)配置没有解决,分布式部署的时候会使用相同的配置,任然有ID重复的风险。
- 使用的时候需要实例化对象,没有形成开箱即用的工具类。
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。(这点在正常情况下是不会发生的)
作者:程序员内点事 链接:
https://juejin.im/post/5e48a9af6fb9a07cc200c203
来源:掘金