准备Kafka环境
这里推荐使用Docker Compose快速搭建一套本地开发环境。
以下docker-compose.yml文件用来搭建一套单节点zookeeper和单节点kafka环境,并且在8080端口提供kafka-ui管理界面。
version: '2.1'services:zoo1:image: confluentinc/cp-zookeeper:7.3.2hostname: zoo1container_name: zoo1ports:- "2181:2181"environment:ZOOKEEPER_CLIENT_PORT: 2181ZOOKEEPER_SERVER_ID: 1ZOOKEEPER_SERVERS: zoo1:2888:3888kafka1:image: confluentinc/cp-kafka:7.3.2hostname: kafka1container_name: kafka1ports:- "9092:9092"- "29092:29092"- "9999:9999"environment:KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka1:19092,EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9092,DOCKER://host.docker.internal:29092KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT,DOCKER:PLAINTEXTKAFKA_INTER_BROKER_LISTENER_NAME: INTERNALKAFKA_ZOOKEEPER_CONNECT: "zoo1:2181"KAFKA_BROKER_ID: 1KAFKA_LOG4J_LOGGERS: "kafka.controller=INFO,kafka.producer.async.DefaultEventHandler=INFO,state.change.logger=INFO"KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1KAFKA_JMX_PORT: 9999KAFKA_JMX_HOSTNAME: ${DOCKER_HOST_IP:-127.0.0.1}KAFKA_AUTHORIZER_CLASS_NAME: kafka.security.authorizer.AclAuthorizerKAFKA_ALLOW_EVERYONE_IF_NO_ACL_FOUND: "true"depends_on:- zoo1kafka-ui:container_name: kafka-uiimage: provectuslabs/kafka-ui:latestports:- 8080:8080depends_on:- kafka1environment:DYNAMIC_CONFIG_ENABLED: "TRUE"参考资料
- https://github.com/conduktor/kafka-stack-docker-compose
- https://github.com/provectus/kafka-ui
将上述docker-compose.yml文件在本地保存,在同一目录下执行以下命令启动容器。
docker-compose up -d
如果快速启动的话,那么可以参考docker的方式
docker run -it -p 8080:8080 -e DYNAMIC_CONFIG_ENABLED=true provectuslabs/kafka-ui
容器启动后,使用浏览器打开127.0.0.1:8080 即可看到如下kafka-ui界面。
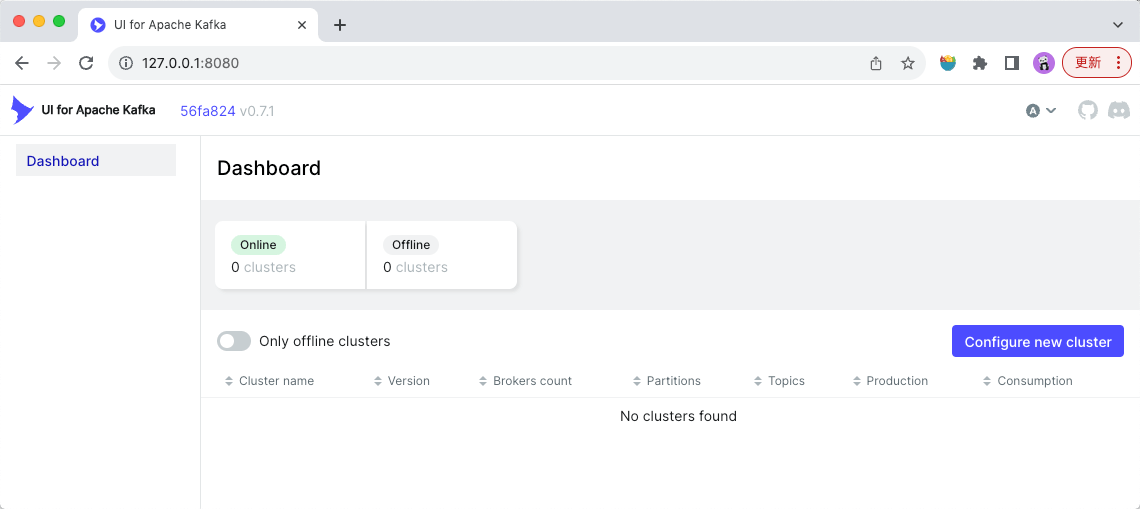
点击页面右侧的“Configure new cluster”按钮,配置kafka服务连接信息。
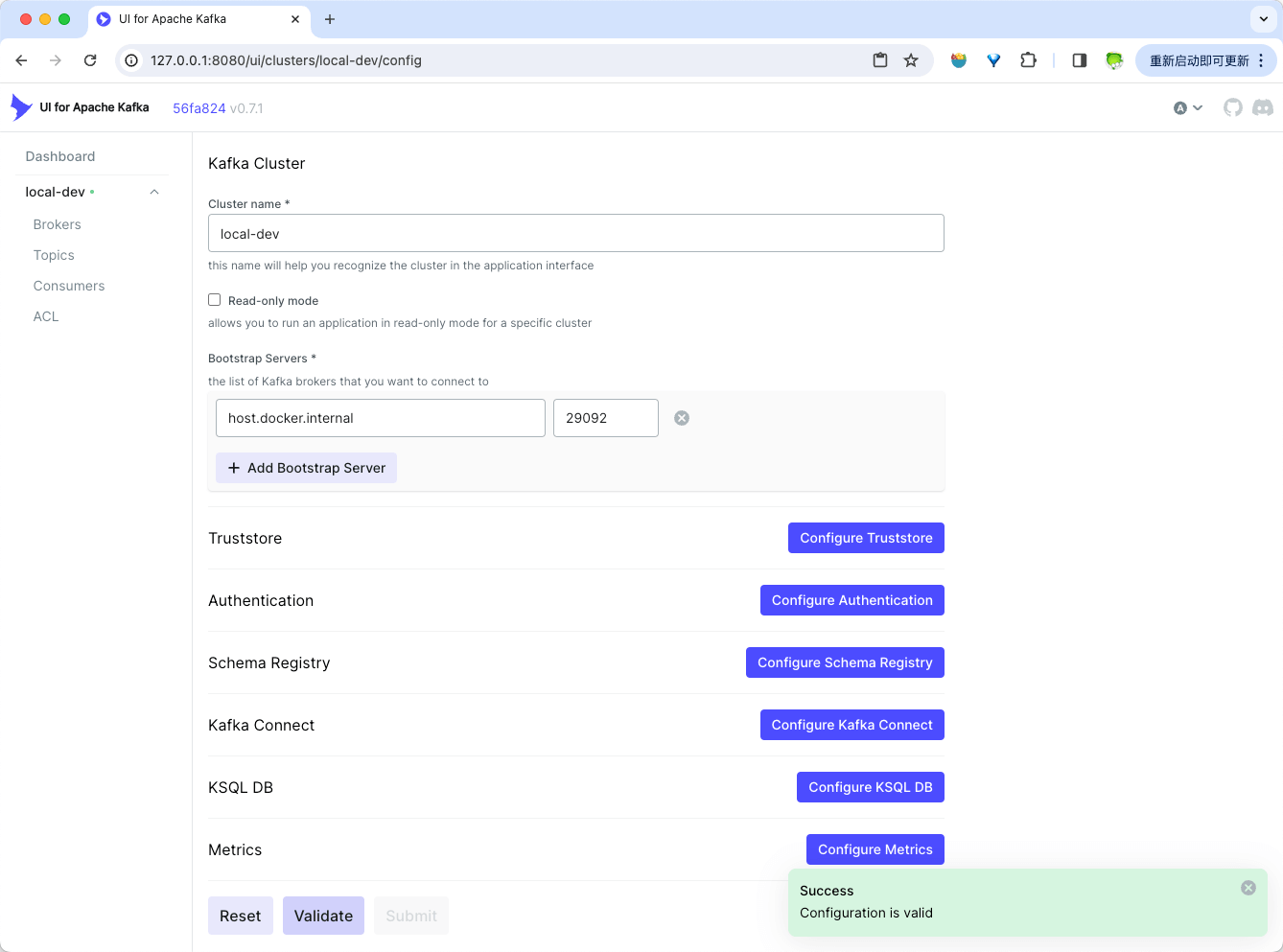
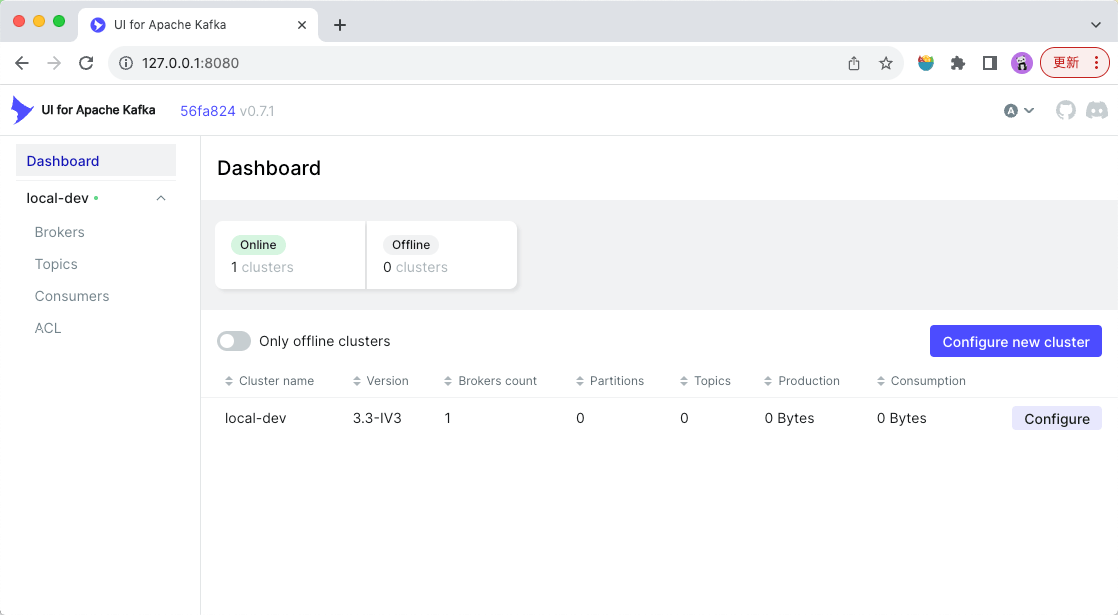
填写完信息后,点击页面下方的“Submit”按钮提交即可。
安装kafka-go
执行以下命令下载 kafka-go依赖。
go get github.com/segmentio/kafka-go
注意:kafka-go 需要 Go 1.15或更高版本。
kafka-go使用指南
kafka-go 提供了两套与Kafka交互的API。
- 低级别(
low-level):基于与Kafka服务器的原始网络连接实现。 - 高级别(
high-level):对于常用读写操作封装了一套更易用的API。
通常建议直接使用高级别的交互API。
Connection
Conn 类型是 kafka-go 包的核心。它代表与 Kafka broker之间的连接。基于它实现了一套与Kafka交互的低级别 API。
发送消息(生产者)
下面是连接至Kafka之后,使用Conn发送消息的代码示例。
// writeByConn 基于Conn发送消息
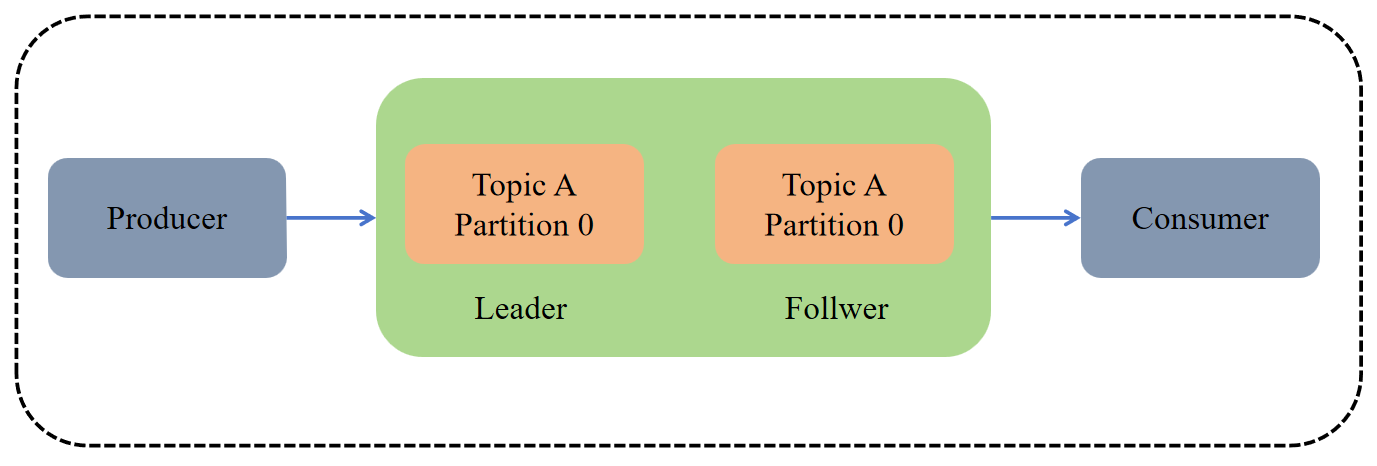
func writeByConn() {topic := "my-topic"partition := 0// 连接至Kafka集群的Leader节点conn, err := kafka.DialLeader(context.Background(), "tcp", "localhost:9092", topic, partition)if err != nil {log.Fatal("failed to dial leader:", err)}// 设置发送消息的超时时间conn.SetWriteDeadline(time.Now().Add(10 * time.Second))// 发送消息_, err = conn.WriteMessages(kafka.Message{Value: []byte("one!")},kafka.Message{Value: []byte("two!")},kafka.Message{Value: []byte("three!")},)if err != nil {log.Fatal("failed to write messages:", err)}// 关闭连接if err := conn.Close(); err != nil {log.Fatal("failed to close writer:", err)}
}消费消息(消费者)
// readByConn 连接至kafka后接收消息
func readByConn() {// 指定要连接的topic和partitiontopic := "my-topic"partition := 0// 连接至Kafka的leader节点conn, err := kafka.DialLeader(context.Background(), "tcp", "localhost:9092", topic, partition)if err != nil {log.Fatal("failed to dial leader:", err)}// 设置读取超时时间conn.SetReadDeadline(time.Now().Add(10 * time.Second))// 读取一批消息,得到的batch是一系列消息的迭代器batch := conn.ReadBatch(10e3, 1e6) // fetch 10KB min, 1MB max// 遍历读取消息b := make([]byte, 10e3) // 10KB max per messagefor {n, err := batch.Read(b)if err != nil {break}fmt.Println(string(b[:n]))}// 关闭batchif err := batch.Close(); err != nil {log.Fatal("failed to close batch:", err)}// 关闭连接if err := conn.Close(); err != nil {log.Fatal("failed to close connection:", err)}
}使用batch.Read更高效一些,但是需要根据消息长度选择合适的buffer(上述代码中的b),如果传入的buffer太小(消息装不下)就会返回io.ErrShortBuffer错误。
如果不考虑内存分配的效率问题,也可以按以下代码使用batch.ReadMessage读取消息。
for {msg, err := batch.ReadMessage()if err != nil {break}fmt.Println(string(msg.Value))
}
创建topic
当Kafka关闭自动创建topic的设置时,可按如下方式创建topic。
// createTopicByConn 创建topic
func createTopicByConn() {// 指定要创建的topic名称topic := "my-topic"// 连接至任意kafka节点conn, err := kafka.Dial("tcp", "localhost:9092")if err != nil {panic(err.Error())}defer conn.Close()// 获取当前控制节点信息controller, err := conn.Controller()if err != nil {panic(err.Error())}var controllerConn *kafka.Conn// 连接至leader节点controllerConn, err = kafka.Dial("tcp", net.JoinHostPort(controller.Host, strconv.Itoa(controller.Port)))if err != nil {panic(err.Error())}defer controllerConn.Close()topicConfigs := []kafka.TopicConfig{{Topic: topic,NumPartitions: 1,ReplicationFactor: 1,},}// 创建topicerr = controllerConn.CreateTopics(topicConfigs...)if err != nil {panic(err.Error())}
}通过非leader节点连接leader节点
下面的示例代码演示了如何通过已有的非leader节点的Conn,连接至 leader节点
conn, err := kafka.Dial("tcp", "localhost:9092")
if err != nil {panic(err.Error())
}
defer conn.Close()
// 获取当前控制节点信息
controller, err := conn.Controller()
if err != nil {panic(err.Error())
}
var connLeader *kafka.Conn
connLeader, err = kafka.Dial("tcp", net.JoinHostPort(controller.Host, strconv.Itoa(controller.Port)))
if err != nil {panic(err.Error())
}
defer connLeader.Close()上面的代码用于通过 Kafka 协议创建一个名为 “my-topic” 的主题(topic)。让我解释一下代码的主要部分:
-
func createTopicByConn(): 这是一个函数定义,用于创建主题的连接。 -
topic := "my-topic": 指定要创建的主题名称为 “my-topic”。 -
conn, err := kafka.Dial("tcp", "localhost:9092"): 通过kafka.Dial方法连接到 Kafka 集群中的任意一个节点。这里使用了tcp协议连接本地主机的 9092 端口。如果连接失败,则会产生一个错误,并且代码会中止执行。 -
defer conn.Close(): 在函数结束时关闭连接,确保资源被释放。 -
controller, err := conn.Controller(): 通过连接对象获取当前控制器(controller)节点的信息。Kafka 集群有一个控制器节点,负责集群中的元数据管理和协调工作。 -
controllerConn, err = kafka.Dial("tcp", net.JoinHostPort(controller.Host, strconv.Itoa(controller.Port))): 根据获取到的控制器节点信息,再次通过kafka.Dial方法连接到控制器节点。这里使用了net.JoinHostPort函数将主机名和端口号合并为一个字符串。如果连接失败,则会产生一个错误,并且代码会中止执行。 -
defer controllerConn.Close(): 同样在函数结束时关闭连接,确保资源被释放。 -
topicConfigs: 定义一个kafka.TopicConfig类型的切片,其中包含要创建的主题的配置信息。在这里,只有一个元素,即 “my-topic” 主题的配置。 -
err = controllerConn.CreateTopics(topicConfigs...): 调用controllerConn连接对象的CreateTopics方法来创建主题。该方法接受一个或多个kafka.TopicConfig类型的参数,用于指定要创建的主题的配置。如果创建失败,则会产生一个错误,并且代码会中止执行。 -
panic(err.Error()): 如果发生了错误,代码会使用panic函数中止执行,并打印出错误信息。
总体来说,这段代码的作用是连接到 Kafka 集群中的控制器节点,然后通过控制器节点创建一个名为 "my-topic" 的主题。
获取topic列表
conn, err := kafka.Dial("tcp", "localhost:9092")
if err != nil {panic(err.Error())
}
defer conn.Close()partitions, err := conn.ReadPartitions()
if err != nil {panic(err.Error())
}m := map[string]struct{}{}
// 遍历所有分区取topic
for _, p := range partitions {m[p.Topic] = struct{}{}
}
for k := range m {fmt.Println(k)
}上面的代码比较简单。
Reader
Reader是由 kafka-go 包提供的另一个概念,对于从单个主题-分区(topic-partition)消费消息这种典型场景,使用它能够简化代码。Reader 还实现了自动重连和偏移量管理,并支持使用 Context 支持异步取消和超时的 API。
注意: 当进程退出时,必须在 Reader 上调用 Close() 。Kafka服务器需要一个优雅的断开连接来阻止它继续尝试向已连接的客户端发送消息。如果进程使用 SIGINT (shell 中的 Ctrl-C)或 SIGTERM (如 docker stop 或 kubernetes start)终止,那么下面给出的示例不会调用 Close()。当同一topic上有新Reader连接时,可能导致延迟(例如,新进程启动或新容器运行)。在这种场景下应使用signal.Notify处理程序在进程关闭时关闭Reader。
消费消息
下面的代码演示了如何使用Reader连接至Kafka消费消息。
// readByReader 通过Reader接收消息
func readByReader() {// 创建Readerr := kafka.NewReader(kafka.ReaderConfig{Brokers: []string{"localhost:9092", "localhost:9093", "localhost:9094"},Topic: "topic-A",Partition: 0,MaxBytes: 10e6, // 10MB})r.SetOffset(42) // 设置Offset// 接收消息for {m, err := r.ReadMessage(context.Background())if err != nil {break}fmt.Printf("message at offset %d: %s = %s\n", m.Offset, string(m.Key), string(m.Value))}// 程序退出前关闭Readerif err := r.Close(); err != nil {log.Fatal("failed to close reader:", err)}
}
消费者组
kafka-go支持消费者组,包括broker管理的offset。要启用消费者组,只需在ReaderConfig中指定 GroupID。
使用消费者组时,ReadMessage 会自动提交偏移量。
// 创建一个reader,指定GroupID,从 topic-A 消费消息
r := kafka.NewReader(kafka.ReaderConfig{Brokers: []string{"localhost:9092", "localhost:9093", "localhost:9094"},GroupID: "consumer-group-id", // 指定消费者组idTopic: "topic-A",MaxBytes: 10e6, // 10MB
})// 接收消息
for {m, err := r.ReadMessage(context.Background())if err != nil {break}fmt.Printf("message at topic/partition/offset %v/%v/%v: %s = %s\n", m.Topic, m.Partition, m.Offset, string(m.Key), string(m.Value))
}// 程序退出前关闭Reader
if err := r.Close(); err != nil {log.Fatal("failed to close reader:", err)
}在使用消费者组时会有以下限制:
- (*Reader).SetOffset 当设置了GroupID时会返回错误
- (*Reader).Offset 当设置了GroupID时会永远返回 -1
- (*Reader).Lag 当设置了GroupID时会永远返回 -1
- (*Reader).ReadLag 当设置了GroupID时会返回错误
- (*Reader).Stats 当设置了GroupID时会返回一个-1的分区
显式提交
kafka-go 也支持显式提交。当需要显式提交时不要调用 ReadMessage,而是调用 FetchMessage获取消息,然后调用 CommitMessages 显式提交。
自动提交(Autocommit):在调用 ReadMessage 读取消息时,会自动将消费者所消费的消息的偏移量提交到 Kafka,由 Kafka 自动管理偏移量的提交。这种方式简单方便,但是可能会带来一些问题,比如当消费者在处理消息时发生错误,消息可能已经被提交,但实际上消息并没有被成功处理,这样就可能导致数据丢失或重复处理。
显式提交(Explicit commit):在需要提交偏移量时,调用 CommitMessages 显式地提交偏移量。这样可以在消息被成功处理后再提交偏移量,从而确保消息被正确处理。这种方式需要开发者自己管理偏移量的提交,更加灵活,但也需要更多的代码来处理。
ctx := context.Background()
for {// 获取消息m, err := r.FetchMessage(ctx)if err != nil {break}// 处理消息fmt.Printf("message at topic/partition/offset %v/%v/%v: %s = %s\n", m.Topic, m.Partition, m.Offset, string(m.Key), string(m.Value))// 显式提交if err := r.CommitMessages(ctx, m); err != nil {log.Fatal("failed to commit messages:", err)}
}在消费者组中提交消息时,使用给定主题/分区的最大偏移量确定该分区的提交偏移量值的情况。具体来说,如果通过调用 FetchMessage 获取了单个分区的偏移量为 1、2 和 3 的消息,然后使用偏移量为3的消息调用 CommitMessages,那么该分区的偏移量为 1 和 2 的消息也会被提交。
这种行为的意义在于,Kafka 会将偏移量视为连续的序列。当提交一个偏移量时,Kafka 会将该偏移量之前的所有消息都视为已经被处理。因此,如果使用偏移量为3的消息调用了提交操作,那么偏移量为1和2的消息也会被提交,因为它们在偏移量3之前,已经被消费者处理了。
这种方式确保了消费者组中的所有消费者都会收到相同的消息,并且每个分区的消息都会被处理一次且仅一次,从而确保了消费者组的一致性和正确性。
管理提交间隔
默认情况下,调用CommitMessages将同步向Kafka提交偏移量。为了提高性能,可以在ReaderConfig中设置CommitInterval来定期向Kafka提交偏移。
// 创建一个reader从 topic-A 消费消息
r := kafka.NewReader(kafka.ReaderConfig{Brokers: []string{"localhost:9092", "localhost:9093", "localhost:9094"},GroupID: "consumer-group-id",Topic: "topic-A",MaxBytes: 10e6, // 10MBCommitInterval: time.Second, // 每秒刷新一次提交给 Kafka
})Writer
向Kafka发送消息,除了使用基于Conn的低级API,kafka-go包还提供了更高级别的 Writer 类型。大多数情况下使用Writer即可满足条件,它支持以下特性。
- 对错误进行自动重试和重新连接。
- 在可用分区之间可配置的消息分布。
- 向Kafka同步或异步写入消息。
- 使用
Context的异步取消。 - 关闭时清除挂起的消息以支持正常关闭。
- 在发布消息之前自动创建不存在的
topic。
发送消息
// 创建一个writer 向topic-A发送消息
w := &kafka.Writer{Addr: kafka.TCP("localhost:9092", "localhost:9093", "localhost:9094"),Topic: "topic-A",Balancer: &kafka.LeastBytes{}, // 指定分区的balancer模式为最小字节分布RequiredAcks: kafka.RequireAll, // ack模式Async: true, // 异步
}err := w.WriteMessages(context.Background(),kafka.Message{Key: []byte("Key-A"),Value: []byte("Hello World!"),},kafka.Message{Key: []byte("Key-B"),Value: []byte("One!"),},kafka.Message{Key: []byte("Key-C"),Value: []byte("Two!"),},
)
if err != nil {log.Fatal("failed to write messages:", err)
}if err := w.Close(); err != nil {log.Fatal("failed to close writer:", err)
}创建不存在的topic
如果给Writer配置了AllowAutoTopicCreation:true,那么当发送消息至某个不存在的topic时,则会自动创建topic。
w := &Writer{Addr: kafka.TCP("localhost:9092", "localhost:9093", "localhost:9094"),Topic: "topic-A",AllowAutoTopicCreation: true, // 自动创建topic
}messages := []kafka.Message{{Key: []byte("Key-A"),Value: []byte("Hello World!"),},{Key: []byte("Key-B"),Value: []byte("One!"),},{Key: []byte("Key-C"),Value: []byte("Two!"),},
}var err error
const retries = 3
// 重试3次
for i := 0; i < retries; i++ {ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)defer cancel()err = w.WriteMessages(ctx, messages...)if errors.Is(err, LeaderNotAvailable) || errors.Is(err, context.DeadlineExceeded) {time.Sleep(time.Millisecond * 250)continue}if err != nil {log.Fatalf("unexpected error %v", err)}break
}// 关闭Writer
if err := w.Close(); err != nil {log.Fatal("failed to close writer:", err)
}写入多个topic
通常,WriterConfig.Topic用于初始化单个topic的Writer。通过去掉WriterConfig中的Topic配置,分别设置每条消息的message.topic,可以实现将消息发送至多个topic。
w := &kafka.Writer{Addr: kafka.TCP("localhost:9092", "localhost:9093", "localhost:9094"),//// 注意: 当此处不设置Topic时,后续的每条消息都需要指定Topic//Balancer: &kafka.LeastBytes{},
}err := w.WriteMessages(context.Background(),// 注意: 每条消息都需要指定一个 Topic, 否则就会报错kafka.Message{Topic: "topic-A",Key: []byte("Key-A"),Value: []byte("Hello World!"),},kafka.Message{Topic: "topic-B",Key: []byte("Key-B"),Value: []byte("One!"),},kafka.Message{Topic: "topic-C",Key: []byte("Key-C"),Value: []byte("Two!"),},
)
if err != nil {log.Fatal("failed to write messages:", err)
}if err := w.Close(); err != nil {log.Fatal("failed to close writer:", err)
}注意:Writer中的Topic和Message中的Topic是互斥的,同一时刻有且只能设置一处。
Balancer
kafka-go实现了多种负载均衡策略。特别是当你从其他Kafka库迁移过来时,你可以按如下说明选择合适的Balancer实现。
Sarama
如果从 sarama 切换过来,并且需要/希望使用相同的算法进行消息分区,则可以使用kafka.Hash或kafka.ReferenceHash。
kafka.Hash = sarama.NewHashPartitioner
kafka.ReferenceHash = sarama.NewReferenceHashPartitioner
w := &kafka.Writer{Addr: kafka.TCP("localhost:9092", "localhost:9093", "localhost:9094"),Topic: "topic-A",Balancer: &kafka.Hash{},
}
librdkafka和confluent-kafka-go
kafka.CRC32Balancer与librdkafka默认的consistent_random策略表现一致。w := &kafka.Writer{Addr: kafka.TCP("localhost:9092", "localhost:9093", "localhost:9094"),Topic: "topic-A",Balancer: kafka.CRC32Balancer{},
}
Logging
想要记录Reader/Writer类型的操作,可以在创建时配置日志记录器。
kafka-go中的Logger是一个接口类型。
type Logger interface {Printf(string, ...interface{})
}
并且提供了一个LoggerFunc类型,帮我们实现了Logger接口。
type LoggerFunc func(string, ...interface{})func (f LoggerFunc) Printf(msg string, args ...interface{}) { f(msg, args...) }
Reader
借助kafka.LoggerFunc我们可以自定义一个Logger。
// 自定义一个Logger
func logf(msg string, a ...interface{}) {fmt.Printf(msg, a...)fmt.Println()
}r := kafka.NewReader(kafka.ReaderConfig{Brokers: []string{"localhost:9092", "localhost:9093", "localhost:9094"},Topic: "q1mi-topic",Partition: 0,Logger: kafka.LoggerFunc(logf),ErrorLogger: kafka.LoggerFunc(logf),
})Writer
也可以直接使用第三方日志库,例如下面示例代码中使用了zap日志库。
w := &kafka.Writer{Addr: kafka.TCP("localhost:9092"),Topic: "q1mi-topic",Logger: kafka.LoggerFunc(zap.NewExample().Sugar().Infof),ErrorLogger: kafka.LoggerFunc(zap.NewExample().Sugar().Errorf),
}
参考
https://www.liwenzhou.com/posts/Go/kafka-go/
https://juejin.cn/post/7173314677550612493
https://www.topgoer.com/%E6%95%B0%E6%8D%AE%E5%BA%93%E6%93%8D%E4%BD%9C/go%E6%93%8D%E4%BD%9Ckafka/%E6%93%8D%E4%BD%9Ckafka.html
http://www.randyfield.cn/post/2021-05-05-go-kafka/