1.翻译环境
计算机能够执行二进制指令,我们的电脑不会直接执行C语言代码,编译器把代码转换成二进制的指令;
我们在VS上面写下printf("hello world");这行代码的时候,经过翻译环境,生成可执行的exe文件,这个主要是编译器完成,生成可执行的文件以后,要进行运行,这个运行主要是由我们的操作系统决定的;
windows环境下面,.c文件经过编译器(cl.exe)的处理,生成.obj的目标文件,这个里面可能会有多个源文件,每个源文件都会生成各自的目标文件,这个过程就叫做编译;目标文件和链接库经过链接器(link.exe)的处理就生成了可执行文件,这个过程叫做链接;
2.预处理(简介)
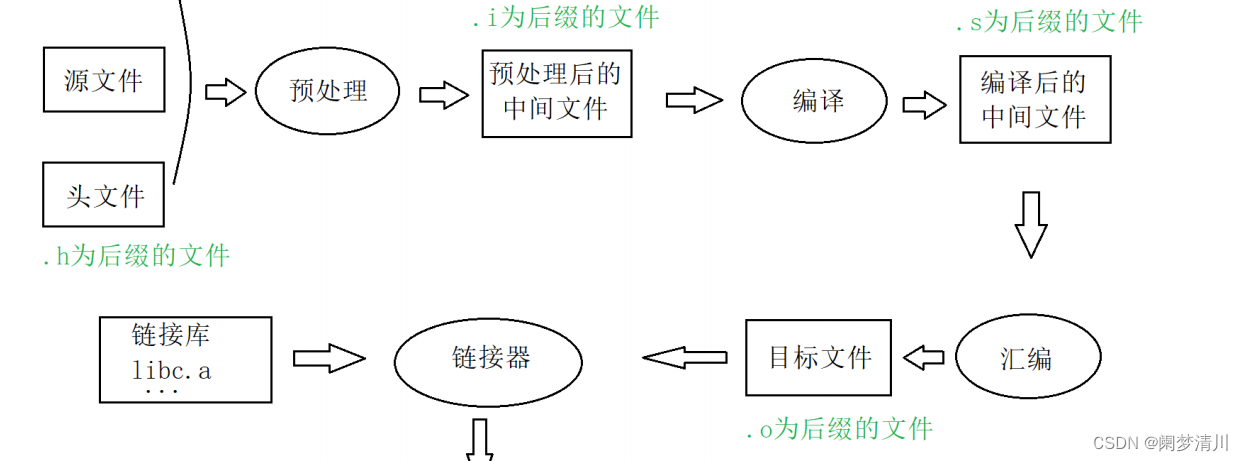
编译其实是分3个过程的,分别是预处理生成.i文件,编译生成.s文件,汇编生成.o文件;
预处理的时候会展开头文件,处理编译指令,删掉我们写的注释(通过这个地方我们也可以看出来注释是写给我们程序员自己看的,并不会真正的到目标文件里面),预处理主要是处理那些以#开头的指令;
3.编译
词法分析,语法分析,语义分析,主要是把C代码(我们可以读懂)转换成为汇编代码(我们无法读懂);
词法分析:将源代码程序被通过扫描器简单的进⾏词法分析,把代码中的字符分割成⼀系列 的记号(关键字、标识符、字⾯量、特殊字符等);
语法分析是以表达式为节点生成语法树;
语义分析主要是进行数据类型的区分,以及数据类型的匹配;
汇编是把汇编代码转换成为机器指令,机器指令就是我们常说的二进制指令;
4.链接
解决一个项目里面多文件,多模块之间可以相互调用,进行地址和空间分配;把多个目标文件进行合并;这个时候我们就是合并相同的函数的地址(会取函数的有效地址),地址修订的过程就叫做重定位,这样不同的函数之间就可以相互调用;
5.预处理(详细)
(1)预处理符号
int main()
{printf("%s\n", __FILE__);printf("%s\n", __DATE__);printf("%s\n", __TIME__);printf("%d\n", __LINE__);return 0;
}这些符号就是已经存在的,我们可以直接进行使用,第一个是打印文件的名字,第二个是创建的日期,第三个打印创建的日期,第四个是行号;这个日期和时间是文件被编译的瞬间的时间和日期

(2)#define
#define可以定义符号常量,这个符号在代码里面出现的时候都会被替换为对应的内容;
#include<stdio.h>
#define MAX 1000
#define ASD "hello world"
int main()
{printf("%d\n", MAX);printf("%s\n", ASD);return 0;
}对于#define定义符号的时候,我们不需要在结尾加上分号,这个时候加上分号就是多余的;

由此可见,如果加上分号,会让编译器默认为你的定义是后面带上分号的1000,这个问题很常见,例如下面的判断语句;

这个简单的if.....else语句报错的原因就是我们加了分号,因为在默认的情况下,如果没有中括号,if只会执行一条语句,但是这个地方MAX自带分号,结尾又有一个分号,相当于是2个语句,所以轮到else执行的时候就会报错;
#define也可以定义宏,下面就是一个具体的案例:

宏的定义类似于函数,但是括号里面没有参数,预处理以后就变成了int ret=a*a;就相当于把a带入define里面的x,把宏体替换回主函数里面的ret语句,下面我们使用表达式进行代换,看看结果:

可能在我们的直觉里面,a+1=6,6*6=36,但是最后打印输出的结果确是11,为什么会这样呢,实际上他在替换的时候,是这样进行替换的,a+1*a+1,我们计算的时候会把a+1看作一个整体,但是预处理不会,他会先计算乘法1*a=5,5+5+1=11,打印输出结果;如果我们想要得到正确结果,我们可以加上中括号就可以了:
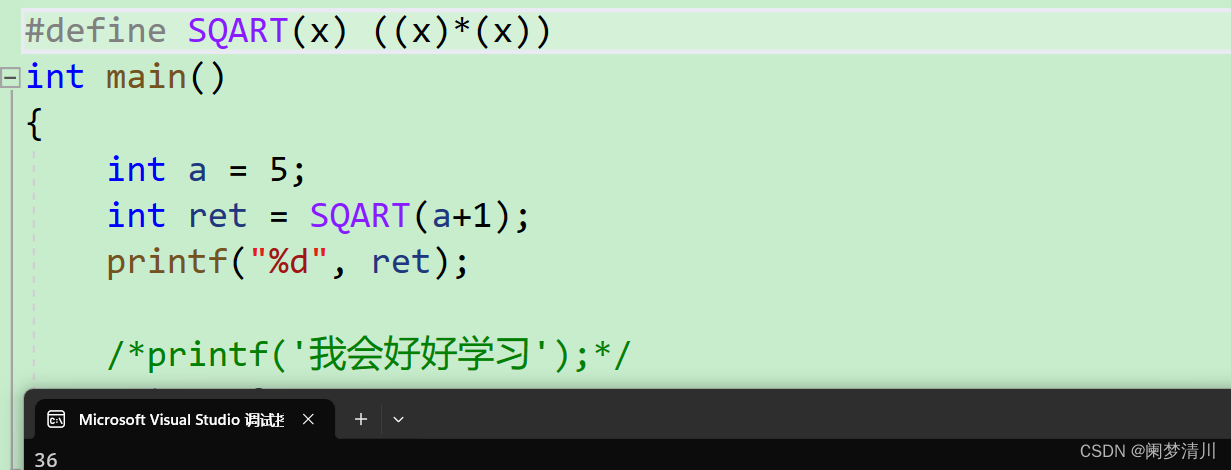
因此用于对数值表达式进行求值的宏定义的时候,我们应该带上括号;否则参数会和就近的运算符结合进行运算,可能无法达到我们想要的结果;
(3)带有副作用的宏
什么叫做副作用呢,我们通过一个简单的例子理解一下:

这个例子里面第一个表达式计算以后a=11,b=10,第二个表达式计算以后a=11,b=11,这个时候我们就可以说,++具有副作用,因为他在赋值的同时,把b的数值也给改变了;
下面我i们学习一下宏的副作用:

这个例子是想要说明使用宏求最大值的时候,这个例子里面替换以后就是:
(a++)>(b++)?(a++):(b++)a++以后先使用后加加,就是带进去的值是3,a的值是4,同理,b++带进去的值是5,b的值是6,但是3>5显然不对,因此执行后半句,也就是b++,这个时候b本来就是6了,加加就会变成7,由此可见,这个过程加加执行了2次,可能并不是我们想要的结果,而且具有不确定性,如果是前面的大,就会是a++执行2次,我们称这种现象叫做宏的副作用;
(4)宏和函数
宏和函数其实是各有利弊的,概括起来,我们可以这样讲,通过前面的一些案例,我们也发现了宏和函数貌似具有一些相似的功能,我们在处理一些比较简单的问题的时候,我们可以使用宏,因为相比较于函数,宏的执行速度和效率会比函数高,因为函数就会涉及到函数的调用以及函数的返回,这些过程我们使用宏都不会遇到,因此使用宏可以节省时间,但是宏自身也是有弊端的,因为宏对于参数的要求不像函数那样严格,因此我们使用的时候可能会出现问题,而且像我们前面提到的,宏的使用可能会出现我们难以预料的副作用,还涉及运算符号的优先级的结合问题;但是函数会在类型完全匹配的时候才回去进行调用,这个方面函数更加保险;
(5)命名规则
这个是我们一般遵守的规则,这个可以用来区分一般的函数和宏的定义,宏在定义的时候一般都是全部大写,但是函数不会全部大写;
(6)条件编译
下面我们认识一些常见的条件编译指令,
#if #endif指令
int main()
{
#if 0int a = 10;int b = 20;printf("%d", a + b);return 0;
#endif
}
这个地方因为在#if的后面是0,所以在条件编译里面的代码就不会被执行了,
#define MAX 0
int main()
{
#if MAXint a = 10;int b = 20;printf("%d", a + b);return 0;
#endif
}(7)头文件的包含
我们使用的包含自己的文件就是使用双引号,包含库里面的文件就是使用尖括号,这两者的区别就是:使用双引号包含会先从当前的文件路径下面进行寻找,找不到的话再到库里面去寻找,使用尖括号就会直接到库里面去寻找,当然,#include<stdio.h>我们都知道这个是库里面的,但是如果我们使用双引号代替尖括号,也可以运行,因为在当前的目录下面找不到,最后还是会到库里面去找,但是这样就浪费时间,我们一般不会这样做;
我们不同的文件相互包含,可能会出现头文件被多次包含的问题,这样做的话,如果头⽂件⽐较⼤,这样预处理后代码量会剧增;我们在头⽂件中添加 ifndef/define/endif解决被多次包含的问题,当然,我们也是可以在头文件里面添加pragma once这样我们的头文件就只会被包含一次了;
(8)取消宏定义
#define MAX 10
int main()
{int a = 10;int b = 20;
#undef MAXfor (int i = 0; i < MAX; i++)//这里会报错{a++;b++;}printf("%d", a + b);return 0;
}我们在开头定义MAX宏,我们可以使用#undef指令取消宏的定义,取消之后,如果我们继续使用的话,就会报错了;
(9)#和##
我们在认识这两个符号之前,我们先铺垫一些只是,这个会在#和##的代码里面使用到
int main()
{printf("what are you doing""\n");printf("what are ""you doing""\n");return 0;
}打印结果:

这个铺垫就是这两种写法的效果是一样的,也就是说如果都是字符串,系统会自动的进行合并字符串的操作;接下来我们了解了这一点再来学习这两种符号的用法:
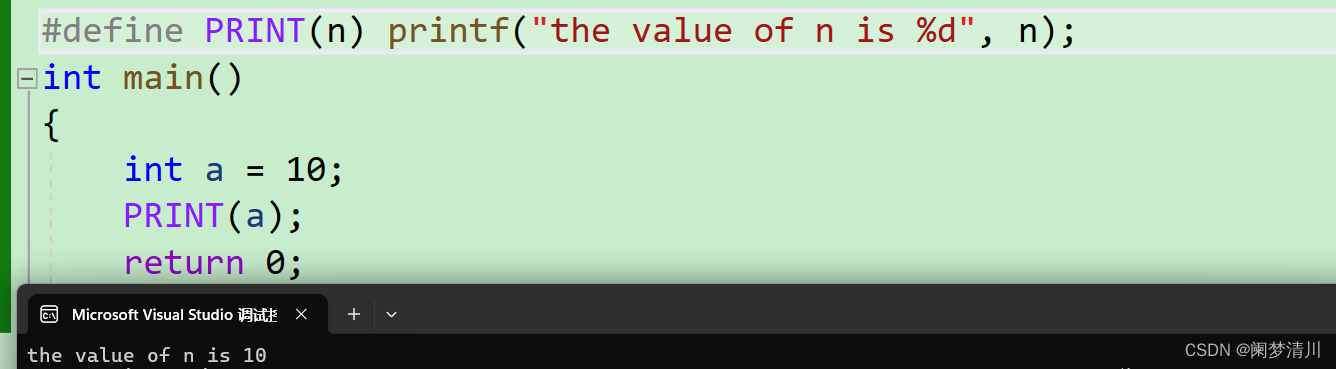
我们首先对比一下使用#和不使用的区别;
不使用:
使用#的打印结果:
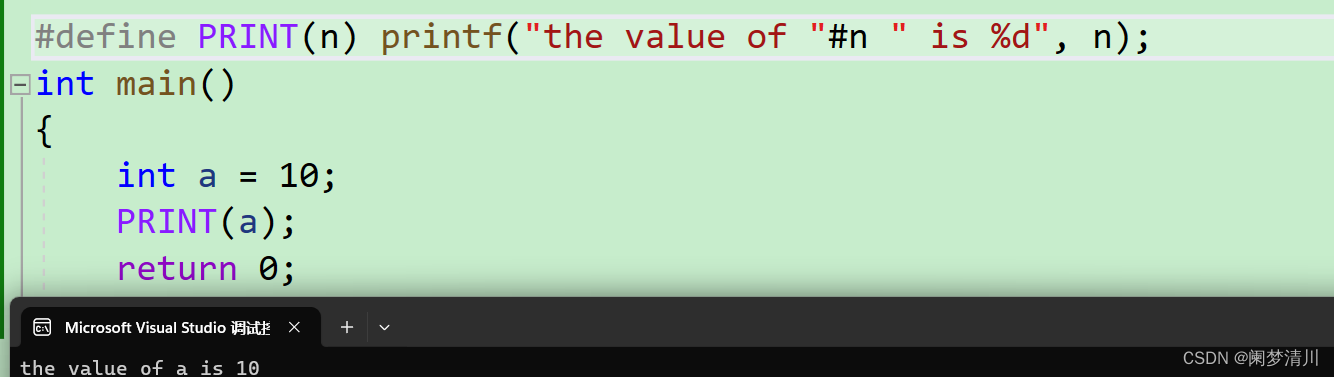
因此,我们可以概括:#运算符所执⾏的操作可以理解为”字符串化“。
##的用法:把位于它两边的符号合成⼀个符号,它允许宏定义从分离的⽂本⽚段创建标识符。 ## 被称 为记号粘合;
写⼀个函数求2个数的较⼤值的时候,不同的数据类型就得写不同的函数。
int int_max(int x, int y)
{return x>y?x:y;
}
float float_max(float x, float y)
{return x>yx:y;
}//宏定义
#define GENERIC_MAX(type) \
type type##_max(type x, type y)\
{ \return (x>y?x:y); \
}注释:这里的\是续行符;
GENERIC_MAX(int) //替换到宏体内后int##_max ⽣成了新的符号 int_max做函数名
GENERIC_MAX(float) //替换到宏体内后float##_max ⽣成了新的符号 float_max做函数名
int main()
{//调⽤函数int m = int_max(2, 3);printf("%d\n", m);float fm = float_max(3.5f, 4.5f);printf("%f\n", fm);return 0;
}这样利用##符号,我们同样可以实现不同类型数据的比较的目的。