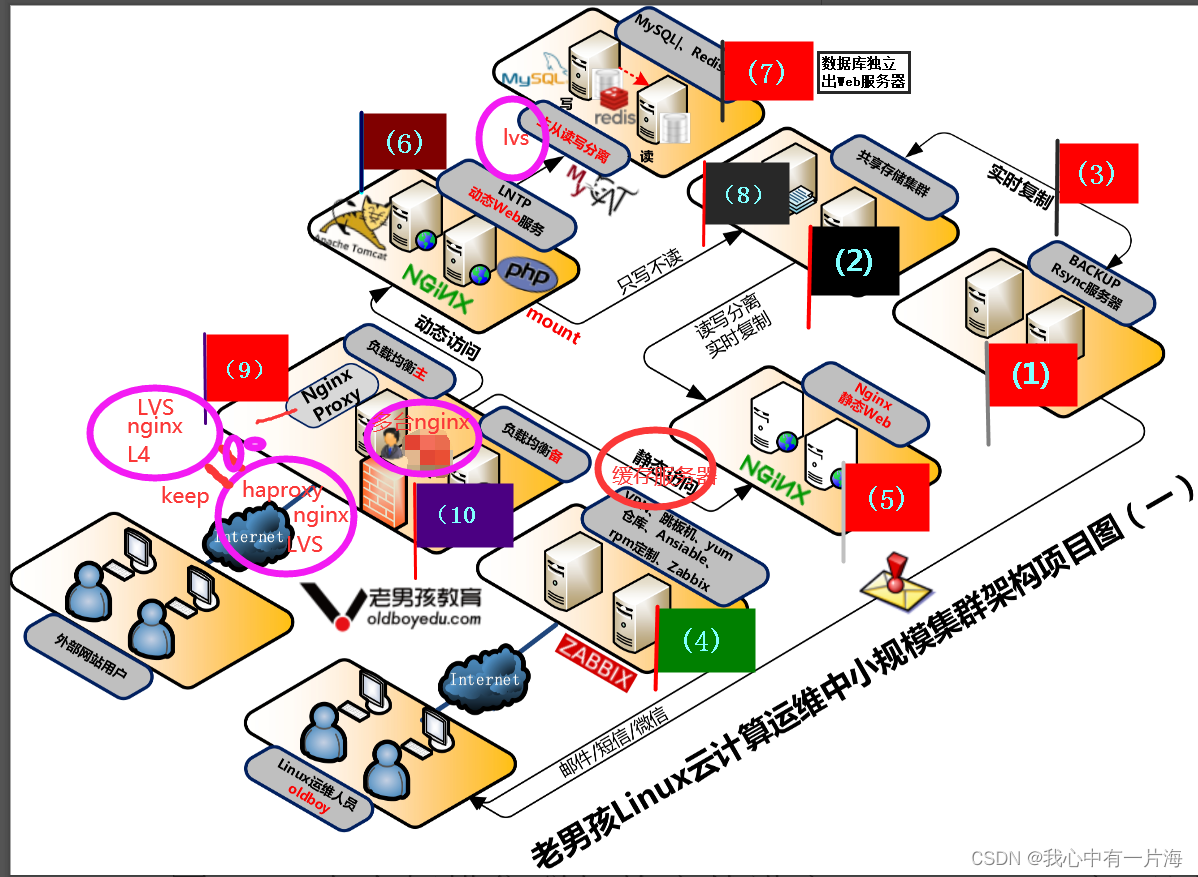
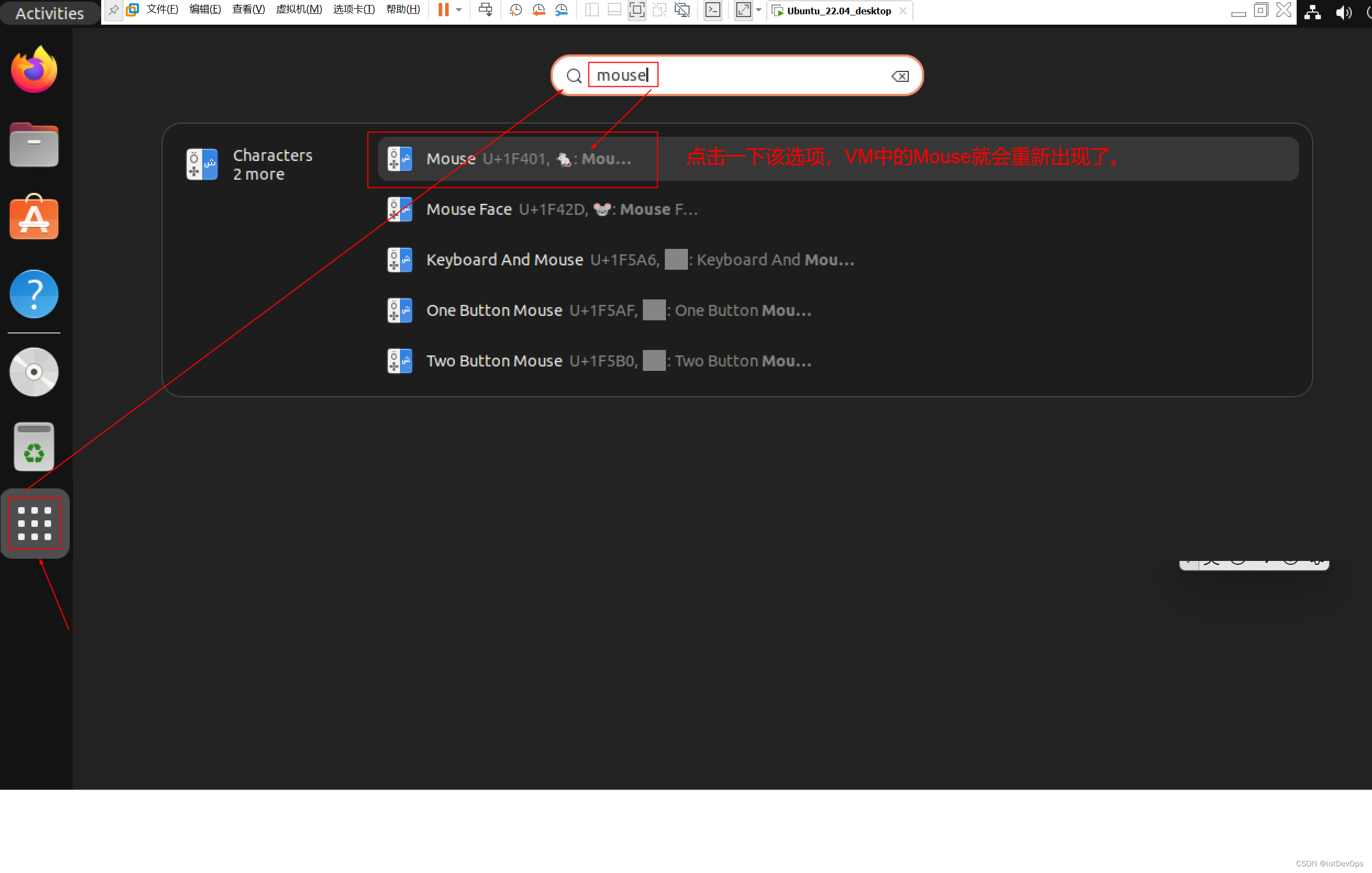
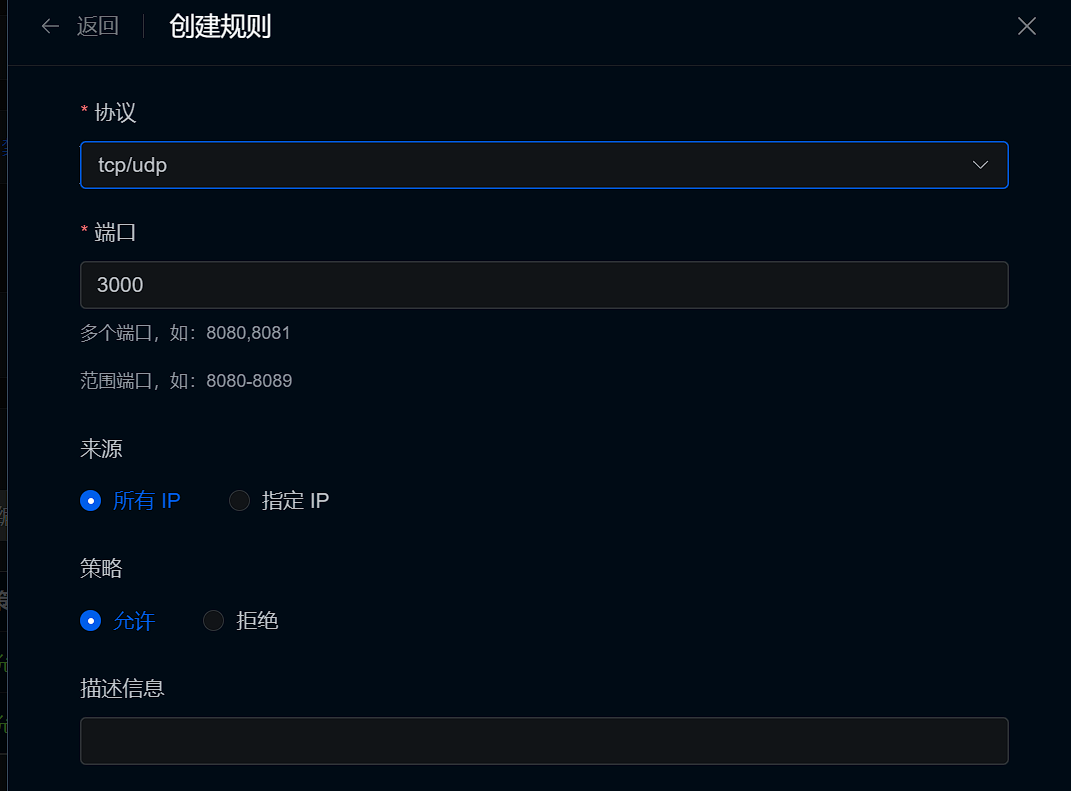
主页:homepage
参考代码:P-MapNet
动机与出发点
在感知系统中引入先验信息是可以提升静态元素感知网络的上限的,这篇文章对SD地图采用栅格化表示(也就是图像形式),之后用CNN网络去抽取栅格化SD地图的信息,将其作为BEV特征优化时额外信息的来源(也就是做key和val)。其实还有一种SD地图表示的方法,那就是向量化描述,目前现有的文献还没有对这两种模态表示更好做过细致分析。感知的终极目的时在线构建高精地图,而感知+地图的结果只能说是在鲁棒性、稳定性上好于纯视觉的方案,对此这篇文章设计了一个refine网络,这个网络通过自监督学习(也即是MAE自编码)的方式学习栅格化的HDMap,这样使得网络参数中隐式编码了HDMap的信息。再用这个自监督得到的网络用视觉+SDMap的结果作为输入去fine-tune得到最后结果。虽然这个隐式编码能够带来一定性能提升,但是没有将静态元素信息很好挖掘。
整体pipeline
文章的方法可以看作是两阶段优化,第一阶段视觉+SDMap得到初步感知结果,第二阶段通过在HDMap预训练过的网络上finetune,整体结构见下图:
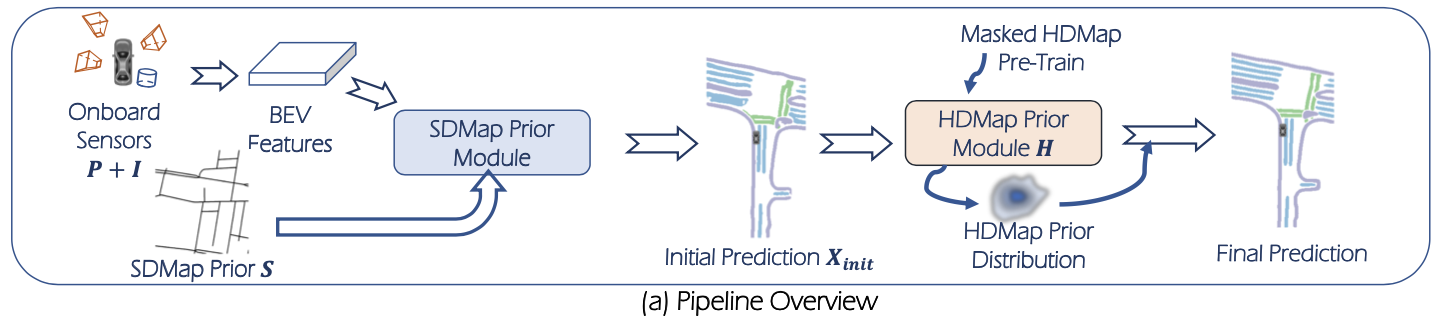
静态元素感知
1)视觉+SDMap的视觉感知
对于这一部分感知任务它首先会使用CNN网络将栅格化之后的SDMap进行编码,之后送到transformer-layer中去做cross-attn,也就是下图中的前半部分。
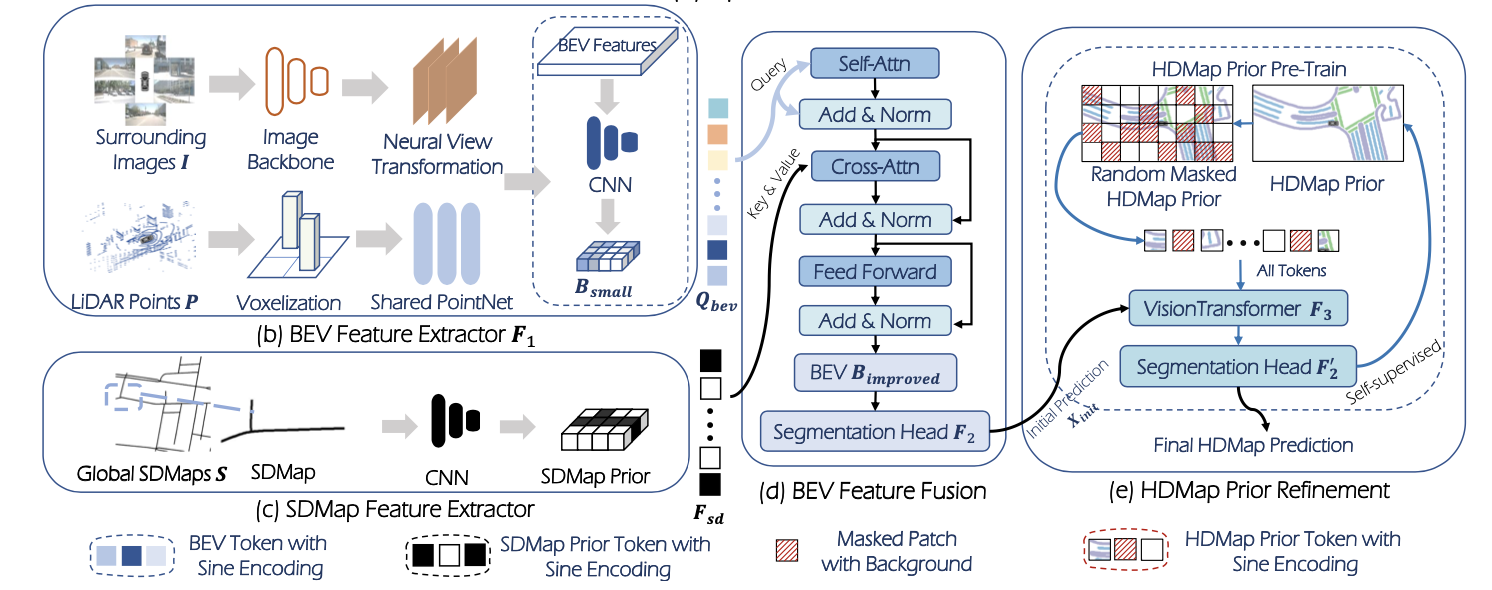
BEV特征(上图中展示的BEV特征应该是经过PV2BEV之后的,因为并未看到与图像特征做交互)通过cross-attn之后相当于就是引入到道路先验,之后再经过预测网络得到初步感知结果。
2)初始感知结果上finetune
这里优化的过程可以划分为两个步骤:
Step1:预训练
使用栅格化之后的HDMap做MAE自编码预训练,这样使得网络参数中隐式学习到了静态元素的信息。这里MAE中mask的设置文中给出了两种方式:random mask和grid-based mask,第一种是在图上按照 20 ∗ 20 20*20 20∗20像素为格子大小间隔做mask,第二种是从多种( 20 ∗ 20 , 20 ∗ 40 , 25 ∗ 50 , 40 ∗ 80 20*20,20*40,25*50,40*80 20∗20,20∗40,25∗50,40∗80)格子大小选择一个尺寸然后按照50%的概率进行随机mask。
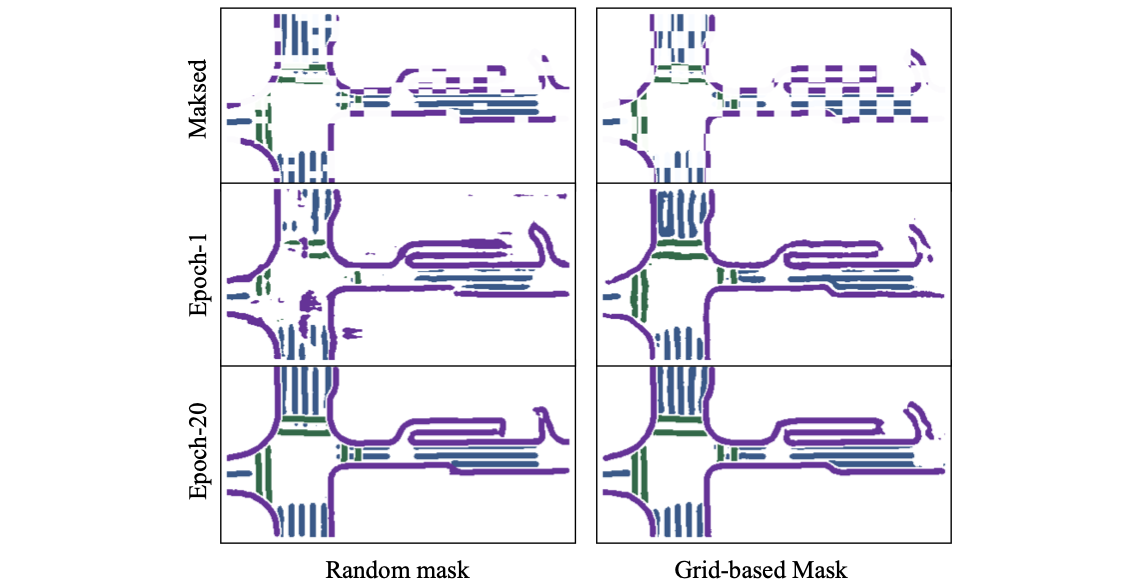
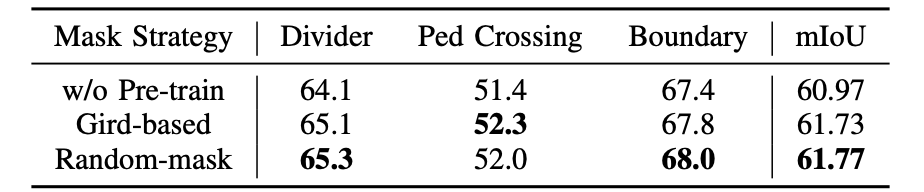
上面的两种mask方式进行比较,有如下结果
Step2:初始结果上的finetune
在Step1中通过预训练的方式得到网络初始参数,那么以感知初始结果作为输入使用预训练参数进行finetune,就可以依据HDMap中的先验信息去进一步优化感知的结果。下面列举了不同感知距离下,初始感知结果和finetune之后结果的性能比较:

实验结果
nuscenes val上的结果比较:
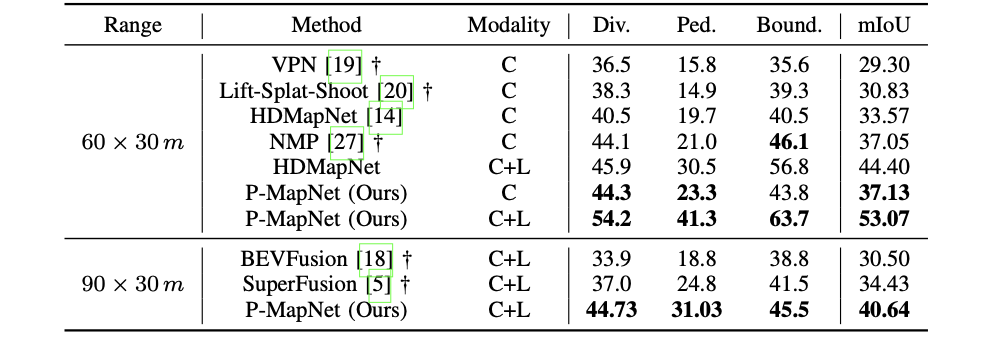
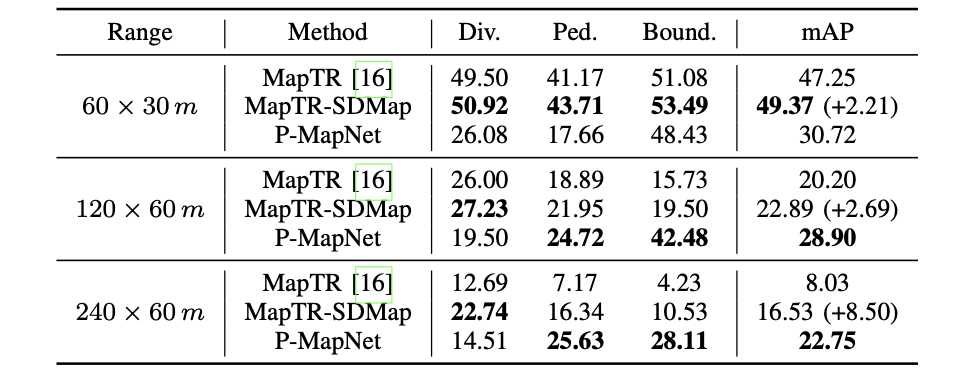
远距离下的性能比较:
![[技术笔记] Flash选型之基础知识芯片分类](https://img-blog.csdnimg.cn/direct/99cff0fd48b4413196959a03cd9ff0e0.png)




![[linux] AttributeError: module ‘transformer_engine‘ has no attribute ‘pytorch‘](https://img-blog.csdnimg.cn/direct/fc90b4653bd548d8acc13fe003d4768f.png)