Web服务器日志分析项目
业务分析
业务背景
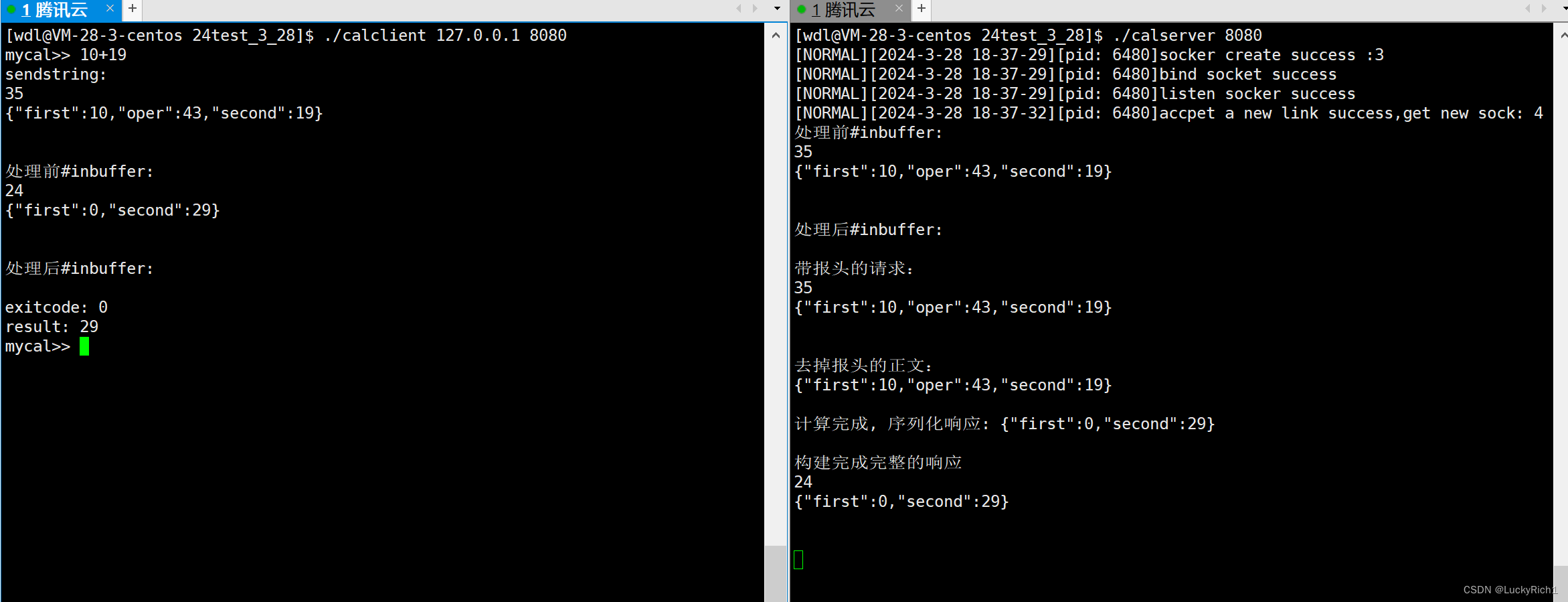
某大型电商公司,产生原始数据日志某小时达4千五万条,一天日志量月4亿两千万条。
主机规划

(可略)日志格式:
2017-06-1900:26:36101.200.190.54 GET /sys/ashx/ConfigHandler.ashx action=js 8008 - 60.23.128.118 Mazilla/5.0+ (Windows+NT+6.1;+WOW64;+rv:53.0)+Gecko/20100101+ Firefox/53.0 http://某网址/welcome.aspx 200
业务需求
- 企业高层期望通过日志进行流量来源分析、网站访客特性等信息,从而下沉访客为会员和客户。
- 期望通过日志网页访问,来分析出受欢迎和不受欢迎的功能模块、公司运营情况、关注细分功能访问量的统计和报表。
- 掌握网站缺陷情况,以便进行优化分析。
用户需求
运营、运维、产品部门提出以下具体需求:
- 运营部门想知道
最活跃的用户有哪些 - 运维部门想知道经
常被访问但无法响应的页面有哪些 - 产品部门想知道
最常被访问的页面有哪些,以便进一步加强
功能需求
- 统计客户端访问次数最多的前10个
IP地址,按访问次数排序,使用EChats柱状图可视化。 - 分析客户端访问页面不正常的页面(返回状态码不为200),同(上)一的形式展示。
- 统计客户端访问次数最多的前10个
访问路径,按访问次数排序,使用EChats柱状图可视化。
技术方案设计
技术特性
- 数据量大
不需要实时分析- 需要简单报表 (考虑Hive)
技术选型
大数据离线分析的行业最佳实践将架构由下向上分为5层,此处不需要机器学习层:
- 数据采集层
- 数据存储层
- 数据分析层
机器学习层- 数据展示层
数据采集层
这里选用Flume:Flume可以采集文件,socket数据包、文件、文件夹、kafka等各种形式源数据 -> 又可以将采集到的数据(下沉sink)输出到HDFS、hbase、hive、kafka等众多外部存储系统中。(在初步使用过程中,我们经常监听一个socket端口或者是一个目录的形式去采集元数据)。
这里我们监听目录的形式,去将数据文件采集到HDFS上供给作业处理。
配置Flume对应的.conf文件进行采集和下沉
数据存储层
使用Hadoop的文件系统HDFS进行存储,是最广泛和廉价的大数据分析平台存储方式。
使用基于hadoop的作业进行处理(文中是MapReduce)
数据分析层
此层文中规划的比较笼统,如MapReduce、Spark、Hive等(主离线),如果是实时需求我们一般采用Flink。文中采用的具体技术栈是HIVE,因为SQL语法减少了代码量。(同时需求较为简单,避免了引入Spark增加复杂度【技术没有最好的,只有符合场景下最合适的】)。
在Hive中引入hdfs中的表,进行分析处理,且输出:
开启客户端Hive,然后在Hive中创建数据库t1,在t1数据库中创建内部表a1,列之间用空格分隔,将数据文件/out/part*导入该表。然后将业务逻辑SQL处理结果输出到结果目录,针对不同的三个业务需求,进行不同的SQL处理和编写,此处略。
hive> create database t1;
hive> use t1;
hive> create table a1(... ...) row format delimited fields terminated by " ";
hive> load data inpath 'hdfs://localhost:9000/out/part*' into table a1;
hive> select * from a1 limit 10;...//把分析数据以覆盖的方式插入该目录
hive> insert overwrite directory 'hdfs://localhost:9000/user/hive/warehouse/a1' select n9,count(*) as num from a1 group by n9;数据展示层
此层略述 , 主是SpringBoot一套的搭配Echatrs的可视化展示。具体是原生还是VUE均可。
Hadoop文件数据由sqoop管道传输到关系型数据库中。
利用管道工具sqoop将hdfs文件迁移到关系型数据库
sqoop export --connect jdbc:mysql://localhost:3306/sqoop --username hive --password hive --table a1 --export-dir /user/hive/warehouse/a1 --input-fields-terminated-by '\001' --num-mappers 1
项目技术栈流程图

招聘网站数据分析项目
相比于直接生成的数据文件,这里的原始数据通过Python爬虫进行爬取,后续步骤类似(比如技术特性一致:数据量大,非实时等),具体业务需求不一致,原始数据格式不一致(此处非日志格式,而是JSON)。即数据采集层使用Python的request模块进行采集。
项目技术栈流程图

电商网站实时数据分析项目
业务分析
电商网站的数据非常多,有用户基本数据(个人信息、账户信息等)、访问数据(浏览、点击、收藏、购买等)、消费数据(支付、转账等)等。借助这些信息我们取其中两个简单的业务需求。
业务需求
- 企业高层期望能够随时查看当天的累计销售总额;
- 部门经理期望能看到某种类型商品(如家电、食品)下的销售总额,观察日内的销售情况的变化;
功能需求
- 统计当天的累计销售金额;
- 统计某种类型的商品当天每个时间段内的销售金额;
这里,技术特性就多了个实时性,文中采用spark进行微批处理,近实时性。
技术选型
大数据实时计算的行业最佳实践架构由下往上分为5层:
- 数据采集层
- 数据缓存层
- 数据计算层
- 数据存储层
- 数据展示层
这里数据采集层依旧是使用Flume进行采集原始文件数据【数据采集层】,但是采集之后下沉到缓存层不再是hdfs文件而是消息队列Kafka。【数据缓存层】。后经由Spark程序消费处理【数据计算层】后存储到Redis中【数据存储层】,再通过Spring程序进行可视化展示【数据展示层】。
核心代码
这里的核心代码是Spark的处理,如何把数据归纳到对应时间段进行累加统计,文中采用的是最简单的直接根据解析出的JSON数据中的time字段进行Redis中对应的key进行累加操作。【采用的是Redis的incrBy累加操作,此处文中未作说明,并发情况下可能封装了redis的事务watch或者CAS乐观锁?】(并未使用开窗,这里的需求和实现是伪实时的)
项目技术栈流程图

金融大数据分析项目
业务需求
- 银行高层希望了解银行有哪些业务办理的方式?各自占多少份额?这样可以优化现有的资源配置,更好地服务客户
- 银行高层希望了解各个城市的业务量分别是多少,有利于开展业务活动
- 银行高层想要知道今年依赖哥哥月份的业务量及变化趋势,并预测今年的业务办理总量
- 银行高层希望能给基金用户推荐合适的基金(真歹毒啊!)
功能需求
- 统计分析银行各种业务办理方式的占比,采用Echarts饼状图;
- 统计分析银行哥哥城市的业务量,并采用ECharts柱状图可视化;
- 统计分析银行截止到目前,每个月的业务量,并采用ECharts折线图可视化;
- 通过历史用户购买基金的数据,使用
协同过滤算法,给当前用户推荐合适的基金;
其中(1)和(2)属于离线数据分析,(3)属于实时数据分析,(4)属于数据挖掘。
技术特性
- 数据量较大
- 业务较为复杂
- 离线和实时需求交叉
技术框架
将其分为四层:数据采集层、数据处理层、数据存储层、数据展示层。
数据采集层
文中离线处理方向:数据采集使用SparkSQL从MySQL中采集数据;实时方向采用Flume和Kafka从服务器进行采集数据。
数据处理层
离线方向采用Spark Core进行数据处理;
实时方向采用Flink处理;
数据存储层
离线采用MySql进行存储;实时采用Redis进行存储;
数据展示层
采用SpringBoot和VUE.js进行处理。
项目技术栈流程图
离线方向将数据用SparkSQL从MySQL中抽取后处理存放在Hive分区表中,再用Spark进行处理和清洗统计分析保存在MySQL中。实时则是直接处理Flume采集到Kafka中的数据下沉到Redis和MySQL中。
【Flink业务处理都是简单的keyBy(0)和sum(1)】未进行开窗类的。

使用Spark ML进行数据挖掘:引入maven中spark-mllib_2.11调用对应的API进行结果训练获取:略。
参考
《“1+x”大数据应用开发(Java)职业技能等级证书系列教材》 卢正平 曹小平 郑子伟 编著