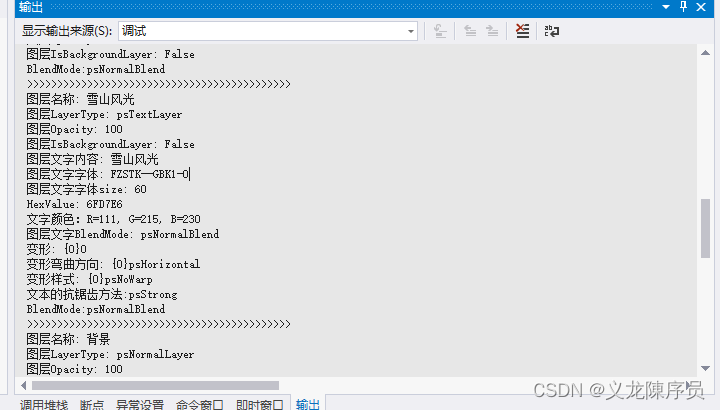
Spark RDD操作实验
一、实验目的
(1)掌握使用Spark访问本地文件和HDFS文件的方法
(2)熟练掌握在Spark Shell中对Spark RDD的操作方法
(3)掌握Spark应用程序的编写、编译打包和运行方法
二、.实验平台
(1)操作系统:Ubuntu 22.04
(2)Spark版本:3.3.4
(3)Hadoop版本:3.2.3
三、实验步骤(在spark-shell中完成)
1、读取Linux系统本地文件,并统计出文件的行数(.count())。
创建txt文件内容如下:
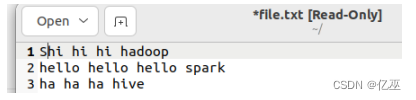
val t=sc.textFile("file:///home/prx17/Desktop/cat_group")
t.count()

- 读取HDFS系统文件,并统计出文件的行数。
将本地文件上传至hdfs
hdfs dfs -put /home/prx17/Desktop/cat_group /data
hdfs dfs -cat /data/cat_group

统计行数
val hdfsfile=sc.textFile("hdfs://localhost:9000/data/cat_group")

- 通过调用parallelize方法,用数组Array={1,2,3,4,5}创建RDD,并求出个各元素的乘积。

- 过滤出文件中所有包含“spark”的行,将结果打印出来。
创建txt文件内容如下:
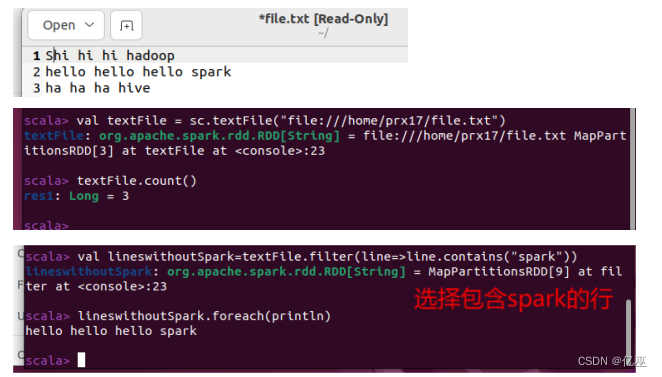
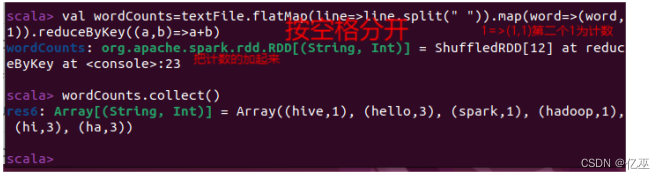
- 假设有一个本地文件word.txt,里面包含了很多行文本,每行文本由多个单词构成,单词之间用空格分隔。对该文本进行词频统计。
6、将下面的成绩单,根据分数降序排序。
| Marry | 78 |
| John | 82 |
| Wang | 90 |
| Lee | 69 |
| Yang | 85 |

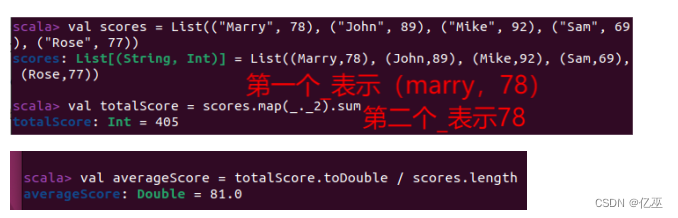
- 给定一组键值对(”Marry”,78),(”John”,89),(”Mike”,92),(”Sam”,69),(”Rose”,77),键值对中的value表示分数,计算所有同学成绩的平均分。
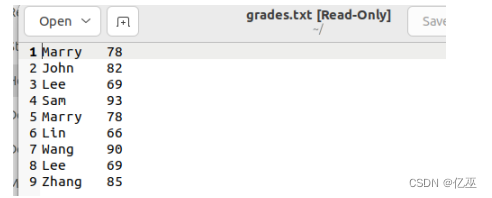
8、删除人名重复的记录,只保留一条记录。
| Marry | 78 |
| John | 82 |
| Lee | 69 |
| Sam | 93 |
| Marry | 78 |
| Lin | 66 |
| Wang | 90 |
| Lee | 69 |
| Zhang | 85 |
创建文件
创建rdd
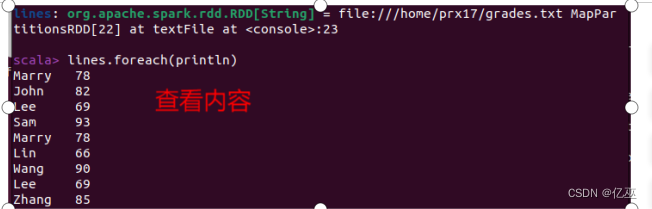
去重方法一:
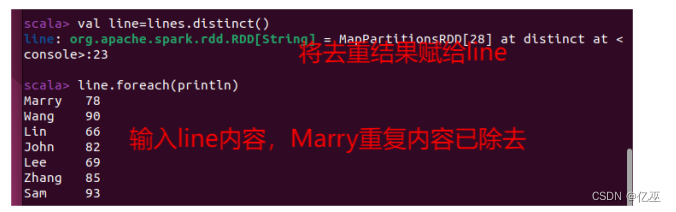
去重方法二:
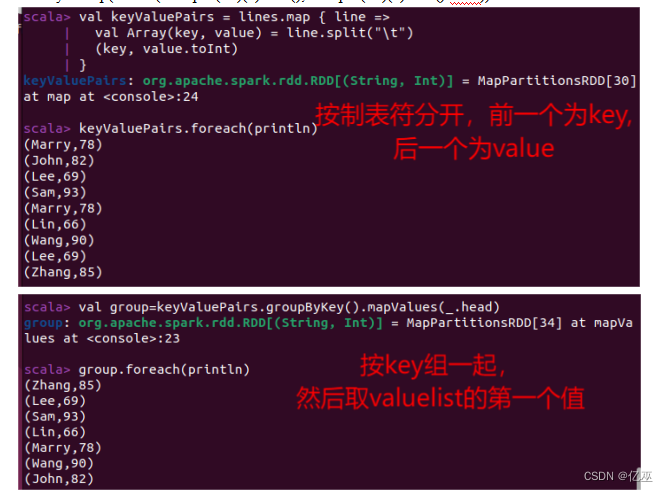
变成键值对形式
val key=t.map(line=>(line.split(" ")(0).trim(),line.split(" ")(1).trim().toInt))
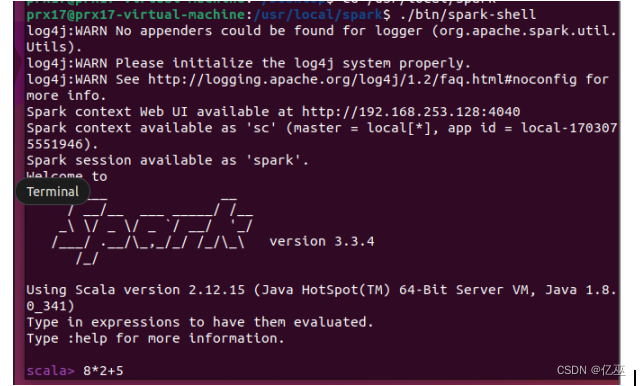
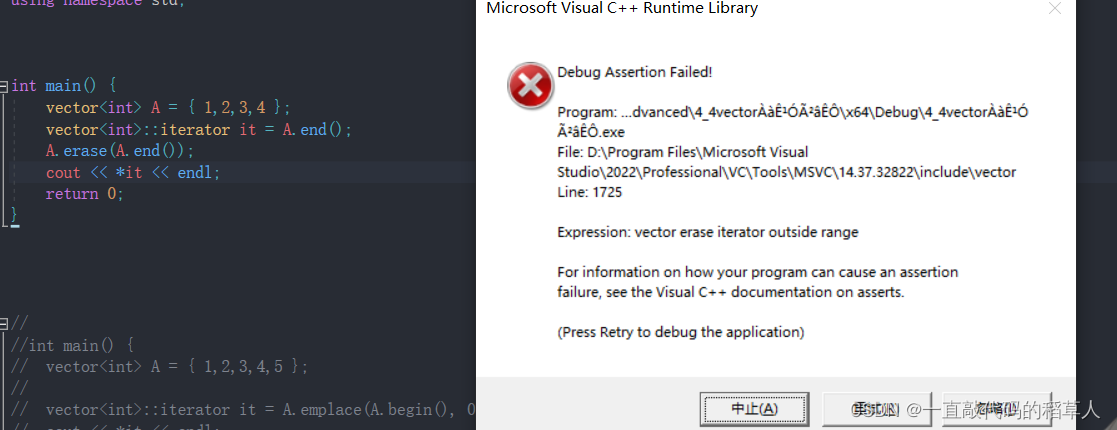
问题与解决方法:
1.解决启动spark时报出一堆INFO,进入spark的conf文件
进入log4j.properties文件,将其中的INFO修改为WARN
重启无大量INFO
- lines.distinct()去重方式操作并不会对lines进行行动
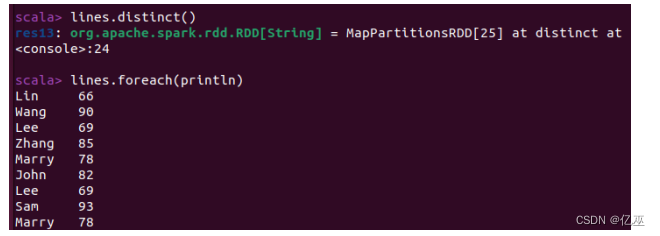
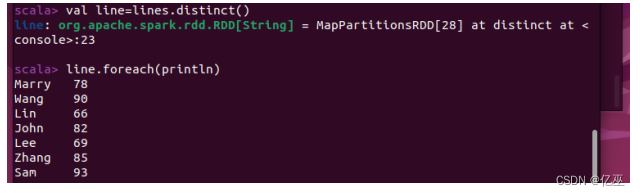
只有把去重结果赋给一个变量才能保存去重结果





![Vue 样式技巧总结与整理[中级局]](https://img-blog.csdnimg.cn/direct/2ef7d9e8907246a9bafaec9197eaaedb.png)