draw下载地址
根据不同操作系统选择不同的安装

截图给gpt 并让他生成drawio格式的,选上推理

在本地将生成的内容保存为xml格式

使用drawio打开 保存的xml文件

只能说效果一般。
大模型gpt结合drawio绘制流程图
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/30362.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

2025-03-08 学习记录--C/C++-C 语言 判断一个数是否是完全平方数
C 语言 判断一个数是否是完全平方数 使用 sqrt 函数计算平方根,然后判断平方根的整数部分是否与原数相等。 #include <stdio.h>
#include <math.h>int isPerfectSquare(int num) {if (num < 0) {return 0; // 负数不是完全平方数}int sqrtNum (int)…

Java高频面试之集合-07
hello啊,各位观众姥爷们!!!本baby今天来报道了!哈哈哈哈哈嗝🐶
面试官:ArrayList 和 Vector 的区别是什么? ArrayList 与 Vector 的区别详解
ArrayList 和 Vector 都是 Java 中基于…

《原型链的故事:JavaScript 对象模型的秘密》
原型链(Prototype Chain) 是 JavaScript 中实现继承的核心机制。每个对象都有一个内部属性 [[Prototype]](可以通过 __proto__ 访问),指向其原型对象。每个对象都有一个原型, 原型本身也是一个对象…

第11章 web应用程序安全(网络安全防御实战--蓝军武器库)
网络安全防御实战--蓝军武器库是2020年出版的,已经过去3年时间了,最近利用闲暇时间,抓紧吸收,总的来说,第11章开始学习利用web应用程序安全,主要讲信息收集、dns以及burpsuite,现在的资产测绘也…

【redis】全局命令set、get、keys
生产环境
未来在工作中会涉及到的几个环境:
办公环境(入职后,公司给你发个电脑)开发环境 有的时候,开发环境和办公环境是一个(一般做前端和做客户端)有的时候,开发环境是一个单独的…

Paper Reading | AI 数据库融合经典论文回顾
人工智能(AI)和数据库(DB)在过去的50年里得到了广泛的研究,随着数据库近年来的不断发展,数据库开始与人工智能结合,数据库和人工智能(AI)可以相互促进。一方面࿰…

Linux上位机开发(开篇)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 传统的上位机开发,一般都是默认pc软件开发。既然是pc软件,一般来说都是基于windows平台开发。开放的框架,无非是…

最长递增子序列--蓝桥oj3046拍照
题目链接
arr[] 1700 1701 1702 1703 1704 1705
dp1[] 1 2 3 4 5 6
dp2[] 6 5 4 3 2 1
sum[]dp1[]dp2[]
sum[] 7 7 7 7 7 7
7是最大的倒叙和正序的…

upload-labs文件上传
第一关
上传一个1.jpg的文件,在里面写好一句webshell 保留一个数据包,将其中截获的1.jpg改为1.php后重新发送 可以看到,已经成功上传 第二关
写一个webshell如图,为2.php 第二关在过滤tpye的属性,在上传2.php后使用b…
LeetCode1137 第N个泰波那契数
泰波那契数列求解:从递归到迭代的优化之路
在算法的世界里,数列问题常常是我们锻炼思维、提升编程能力的重要途径。今天,让我们一同深入探讨泰波那契数列这一有趣的话题。
泰波那契数列的定义
泰波那契序列 Tn 有着独特的定义方式…

OpenCV 拆分、合并图像通道方法及复现
视频讲解 OpenCV 拆分、合并图像通道方法及复现 环境准备:安装 OpenCV 库(pip install opencv-python)
内容:
1. 读取任意图片(支持 jpg/png 等格式)
2. 使用 split () 函数拆解成 3 个单色通道…

【ArcGIS】地理坐标系
文章目录 一、坐标系理论体系深度解析1.1 地球形态的数学表达演进史1.1.1 地球曲率的认知变化1.1.2 参考椭球体参数对比表 1.2 地理坐标系的三维密码1.2.1 经纬度的本质1.2.2 大地基准面(Datum)的奥秘 1.3 投影坐标系:平面世界的诞生1.3.1 投…

登录固定账号和密码:
接口文档
【apifox】面试宝典 个人中心-保存用户数据信息 - 教学练测项目-面试宝典-鸿蒙
登录固定账号和密码:
账号:hmheima
密码:Hmheima%123 UI设计稿
【腾讯 CoDesign】面试宝典 CoDesign - 腾讯自研设计协作平台 访问密码࿱…
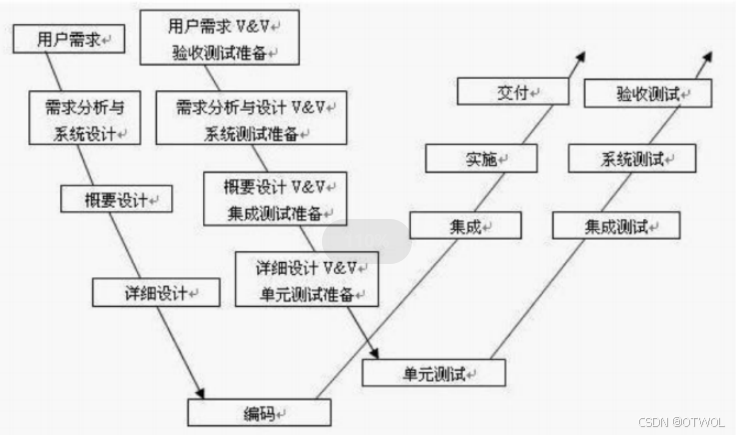
软件测试的基础入门(二)
文章目录 一、软件(开发)的生命周期什么是生命周期软件(开发)的生命周期需求分析计划设计编码测试运行维护 二、常见的开发模型瀑布模型流程优点缺点适应的场景 螺旋模型流程优点缺点适应的场景 增量模型和迭代模型流程适应的场景…


PQL查询和监控各类中间件
1 prometheus的PQL查询
1.1 Metrics数据介绍
prometheus监控中采集过来的数据统一称为Metrics数据,其并不是代表具体的数据格式,而是一种统计度量计算单位当需要为某个系统或者某个服务做监控时,就需要使用到 metrics
prometheus支持的met…


STM32-I2C通信外设
目录
一:I2C外设简介
二:I2C外设数据收发
三:I2C的复用端口 四:主机发送和接收
五:硬件I2C读写MPU6050
相关函数:
1.I2C_ GenerateSTART
2.I2C_ GenerateSTOP
3.I2C_ AcknowledgeConfig
4.I2C…

c语言程序设计--(数据的存储)冲刺考研复试面试简答题,看看我是怎么回答的吧!!!!!
目录
1、整型在内存中的存储是怎样的?
2、原码反码补码的计算方式是什么?
3、对于整形数据在内存中存的都是二进制补码是为什么?
2、什么是大端小端存储?
3、为什么要有大端和小端的存储方式呢? 1、整型在内存中的…

记录小白使用 Cursor 开发第一个微信小程序(二):创建项目、编译、预览、发布(250308)
文章目录 记录小白使用 Cursor 开发第一个微信小程序(二):创建项目、编译、预览、发布(250308)一、创建项目1.1 生成提示词1.2 生成代码 二、编译预览2.1 导入项目2.2 编译预览 三、发布3.1 在微信开发者工具进行上传3…
推荐文章
- (下:补充——五个模型的理论基础)深度学习——图像分类篇章
- .NET Core全屏截图,C#全屏截图
- [c语言日寄]精英怪:三子棋(tic-tac-toe)3命慢通[附免费源码]
- [java] java基础-字符串篇
- 《Effective Java》学习笔记——第2部分 对象通用方法最佳实践
- 《OpenCV》——dlib(人脸应用实例)
- 《Python实战进阶》No14: 使用Dask处理大规模数据集
- 《鸢尾花数学大系:从加减乘除到机器学习》开源资源
- 「 机器人 」利用数据驱动模型替代仿真器:加速策略训练并降低硬件依赖
- 【10】RUST的迭代器与闭包
- 【2024年华为OD机试】(A卷,200分)- 创建二叉树 (JavaScriptJava PythonC/C++)
- 【C++】面试题整理(未完待续)