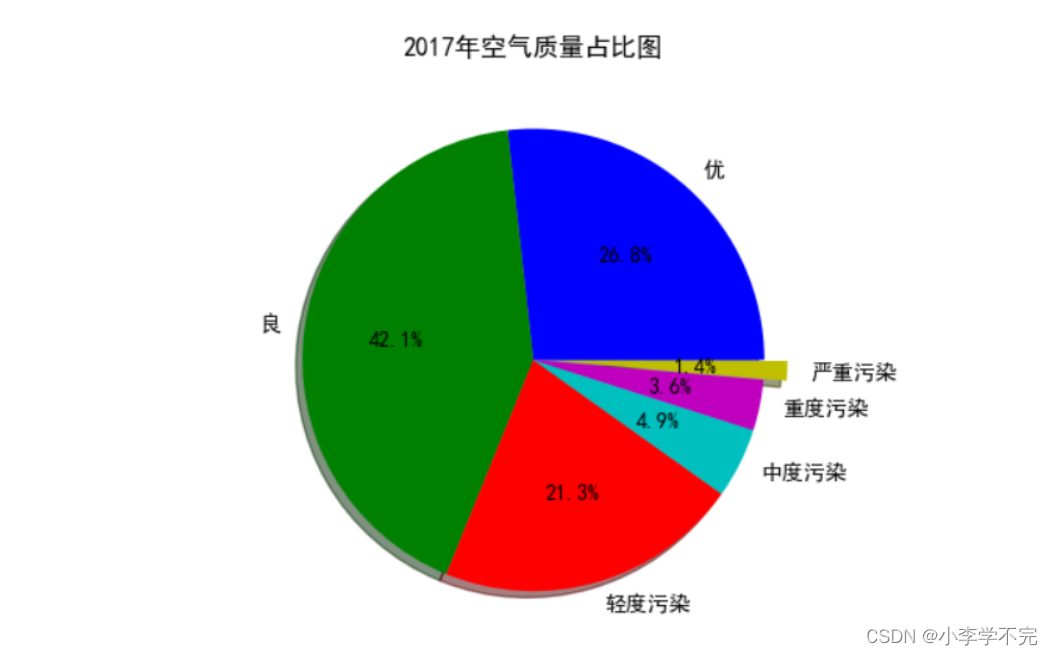
刚刚发布!Google 带来了新的 Gemma 家族成员,CodeGemma,这是基于预训练的 Gemma-2B 和 Gemma-7B 的代码生成模型。
其上下文窗口长度为8K,在另外 500 B 个主要由英语、数学和代码组成的 token 上进行了训练,改进了逻辑和数学推理能力,适合代码生成任务。
GPT-3.5研究测试: https://hujiaoai.cn
GPT-4研究测试: https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4): https://hiclaude3.com
CodeGemma-7B 在 HumanEval 上的表现优于类似大小的7B模型,甚至还要超过 CodeLLaMa-13B。
不过,在 DeepSeekCoder-7B 面前,CodeGemma 还是要稍逊一筹!
CodeGemma支持包括 Python、JavaScript、Java、Kotlin、C++、C#、Rust、Go 在内的多种编程语言。
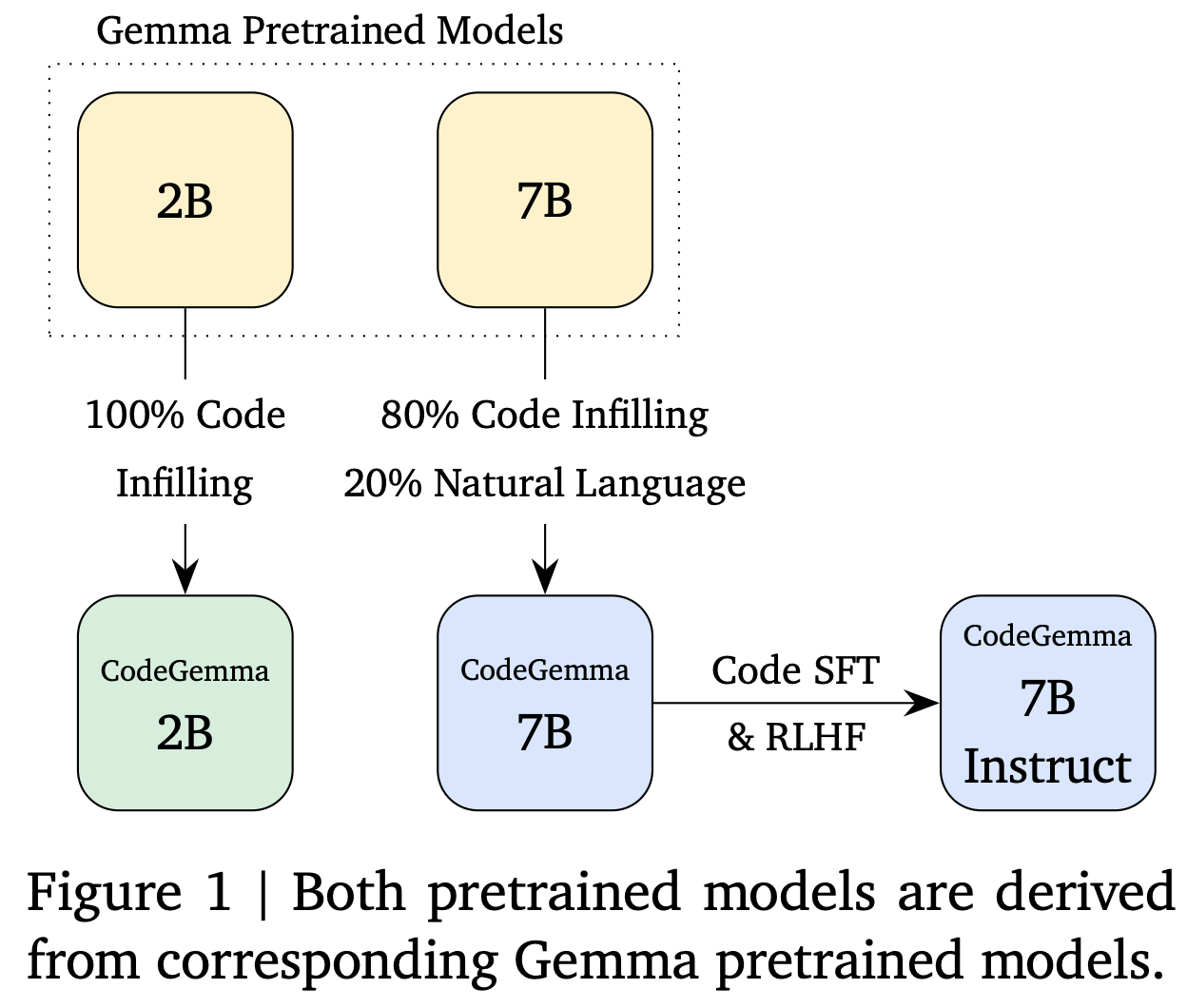
CodeGemma包含三款模型:
-
CodeGemma 2B Base Model,专门针对代码生成进行训练,旨在快速生成代码,适合需要隐私或高性能代码生成的环境。
-
CodeGemma 7B Base Model,训练数据包括80%的代码和20%的自然语言,适合代码生成和理解。
-
CodeGemma 7B Instruct Model,微调版,适用于聊天,擅长代码生成和数学推理。
2B模型相比同尺寸模型更具有优势
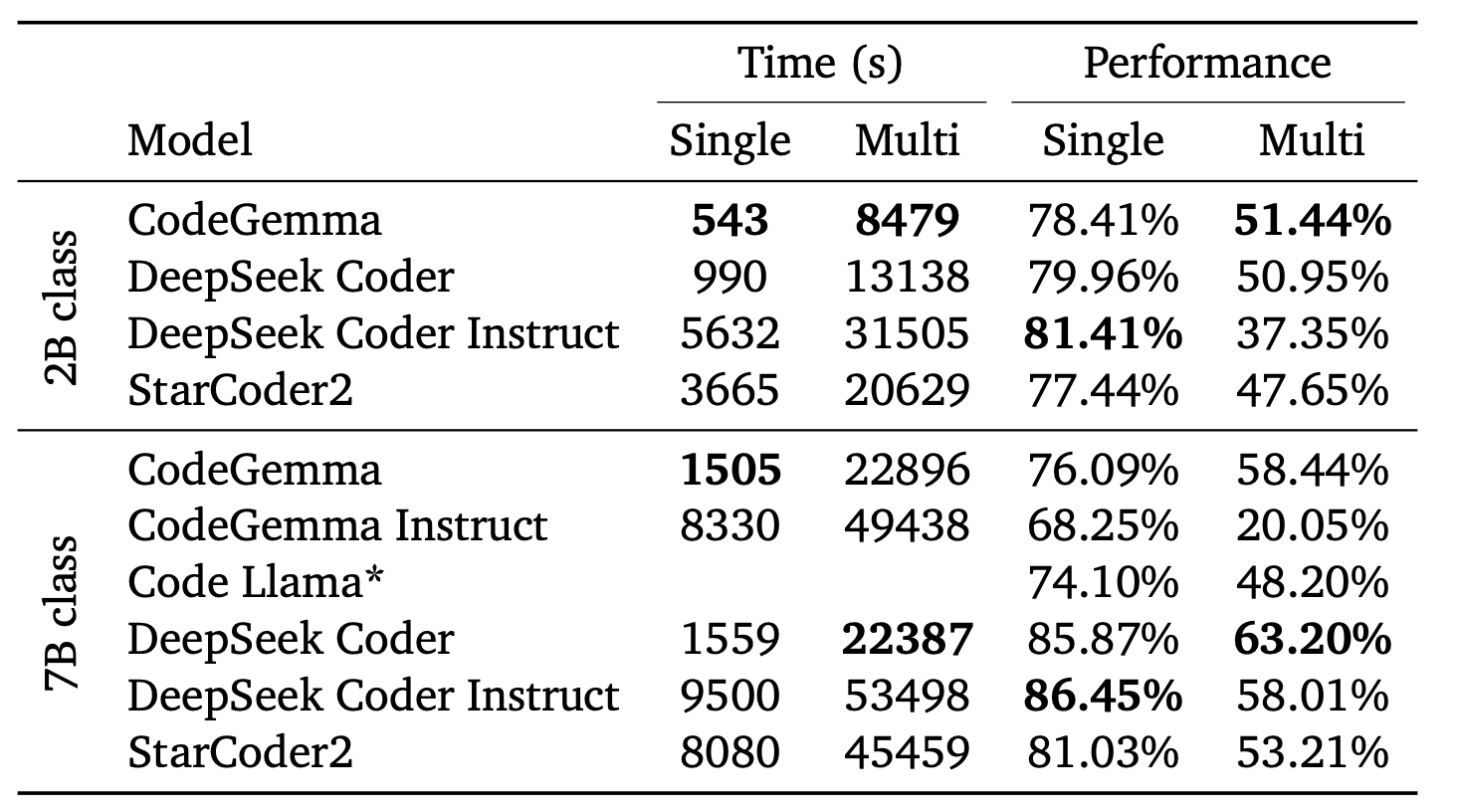
作者使用了 HumanEval Infilling benchmarks 中的单行和多行指标进行评估。在表 2 中展示了与其他基于 FIM 的代码模型的性能对比。
2B 预训练模型在代码自动补全用例中表现出色,低延迟是一个关键因素。在推断过程中,它表现与其他模型相当。
而在许多情况下,速度几乎是其他模型的两倍。作者将这种速度提升归因于基于 Gemma 的架构决策。
不过在 7B 模型上,CodeGemma 的延迟对比并没有优势,反而性能还较大程度地弱于 DeepSeek Coder。
表2. CodeGemma的单行和多行代码完成能力与其它代码模型的比较。
7B模型多语言性能超越 CodeLLaMa-13B
作者在 BabelCode-translated HumanEval 和 Mostly Basic Python Problems (MBPP) 数据集上对比 CodeGemma 系列的多语言代码能力。
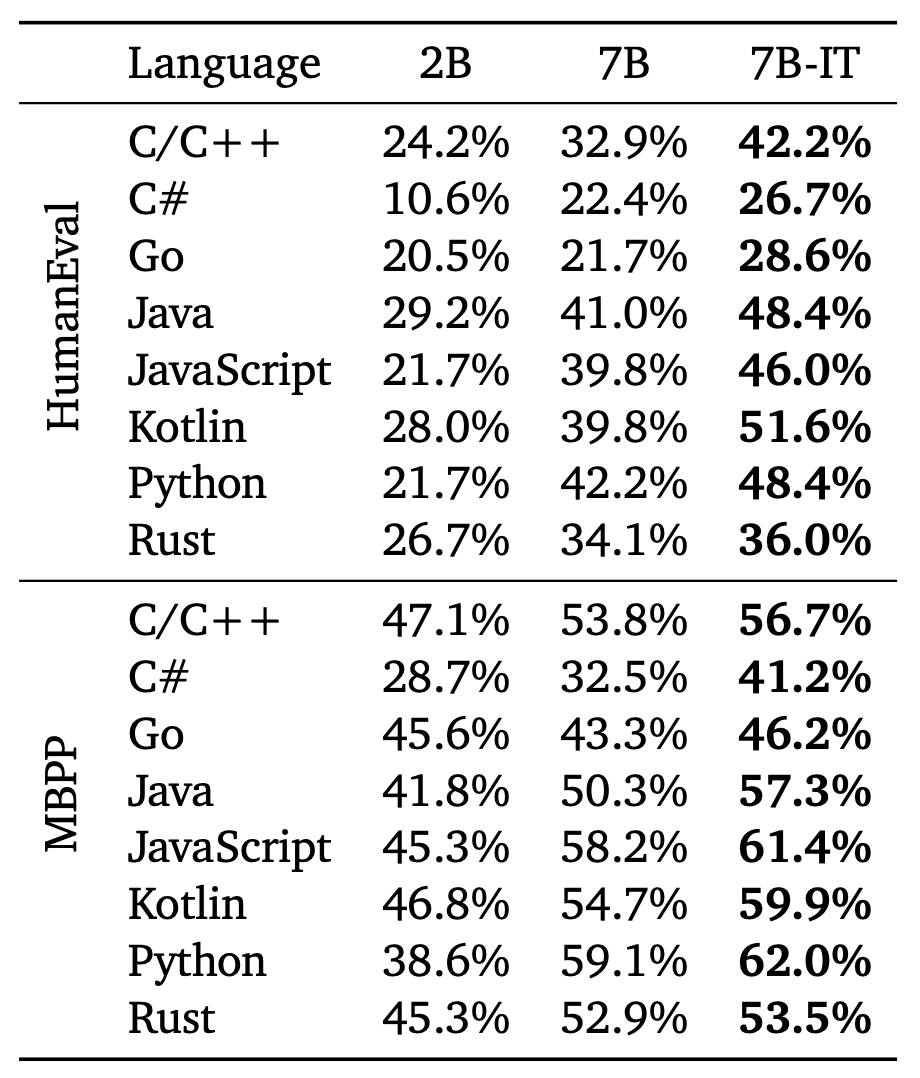
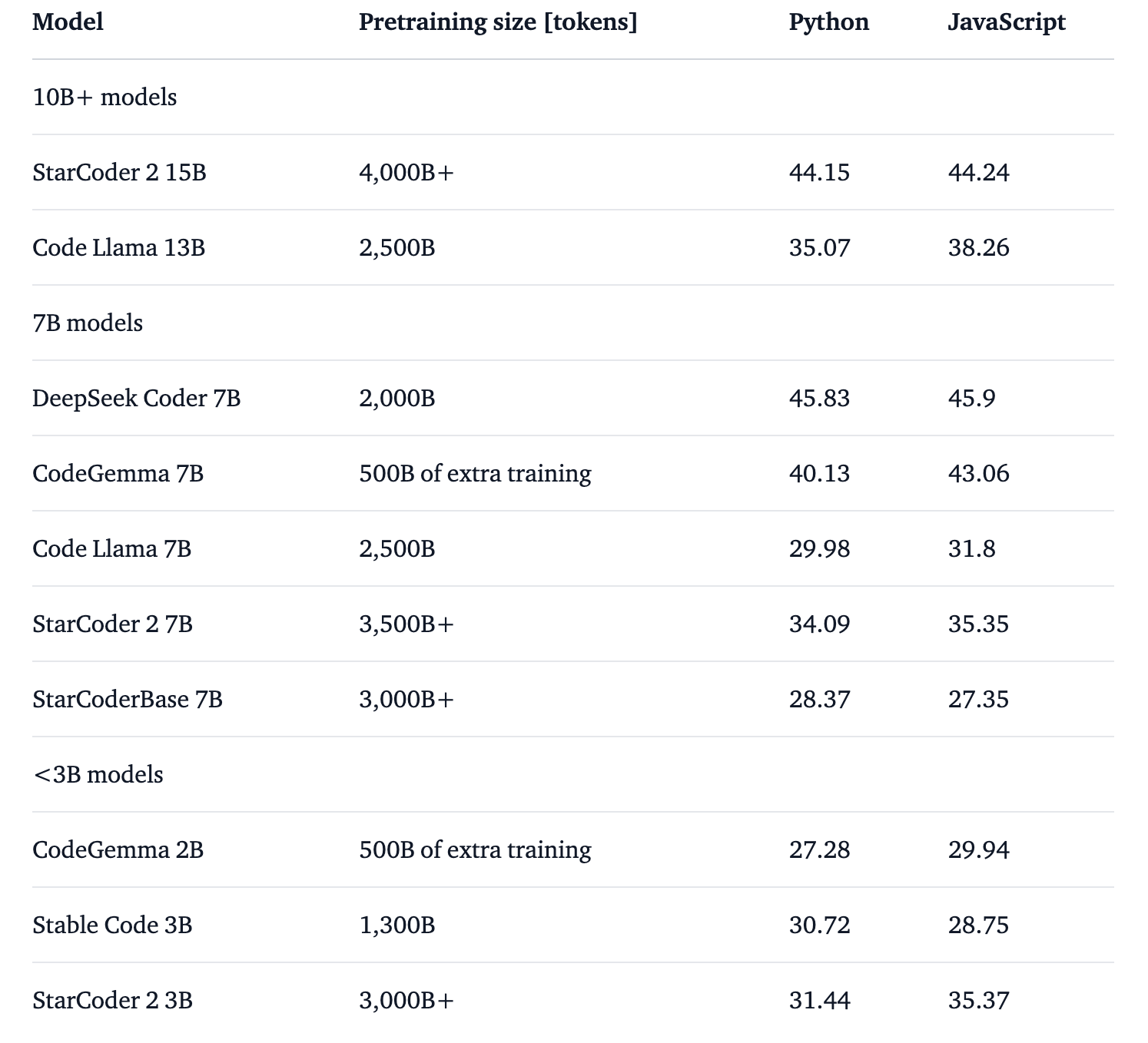
同时,bigcode-models-leaderboard 上也发布了更详细的性能对比。CodeGemma 在 7B 大小的模型中要优于除了 DeepSeekCoder-7B 的模型,对比 CodeLLaMa-13B 也提升了 5个点。
但是我们从训练数据上也能初窥端倪,对于 DeepSeekCoder 所使用的 2000 B 的数据量,CodeGemma 的 500 B 还是小巫见大巫了!
保留 Gemma 的对话能力!
作者评估了 CodeGemma 在各种领域的性能,包括问答、自然语言和数学推理。将两个 7B 模型的结果与 Instruct Gemma-7B模型的结果呈现在图3中。
图3.
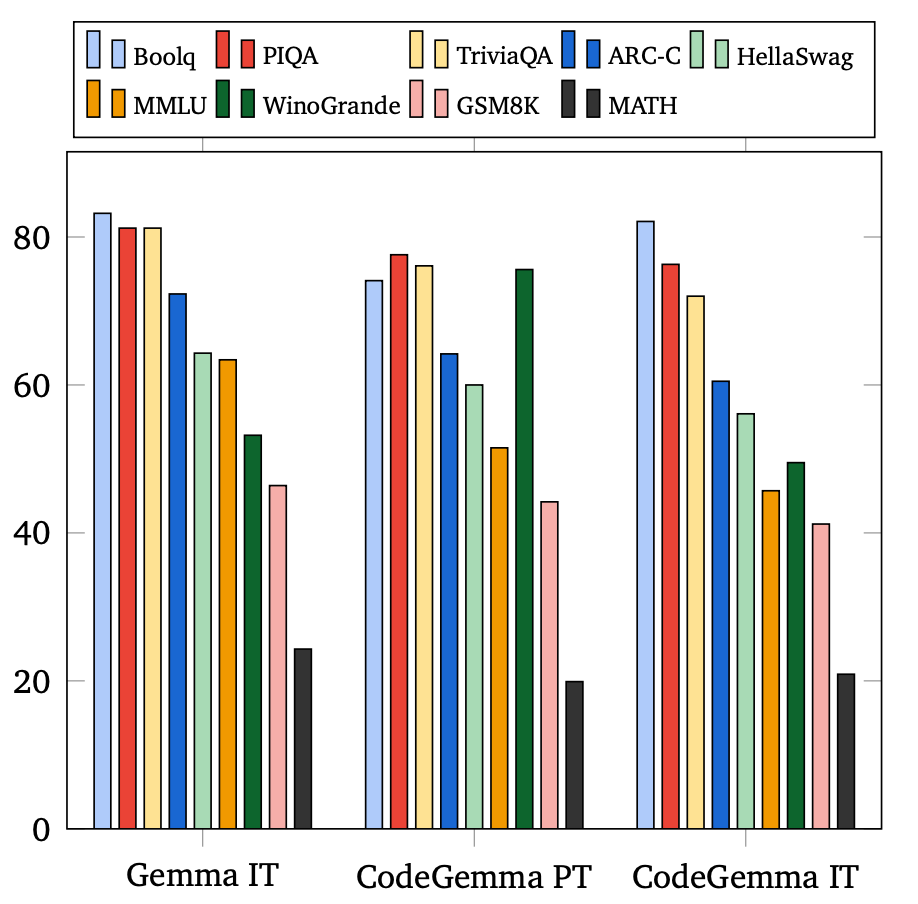
可以看到,CodeGemma 保留了 Gemma模型中大部分相同的自然语言功能。
表5. CodeGemma和指令调优版本Gemma的语言性能比较。Gemma和CodeGemma都属于7B大小类。

最后
借网友的话一用:“开源模型的发布和改进真的太快了!!”

即便是 Google 这样的团队,我们也能看到它在大模型的浪潮下有点手忙脚乱,本来以为是碾压局的 CodeGemma,没想到还是感觉发布得略显匆忙。
以 Google 的手笔,能在 500 B 的数据量下将 7B模型提高到 CodeLLaMa-13B(2500 B tokens)的水平,居然还是没有超过 DeepSeekCoder-7B。
回顾Google这几个月的动向,Bard、Gemini、Gemini Advanced、Gemma 轮番上阵,但是都没有在各自的领域上获得足够的认可,不免让吃瓜群众也感慨呀!



参考资料
[1]https://huggingface.co/blog/codegemma
[2]https://storage.googleapis.com/deepmind-media/gemma/codegemma_report.pdf
[3]https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard