关键要点
-
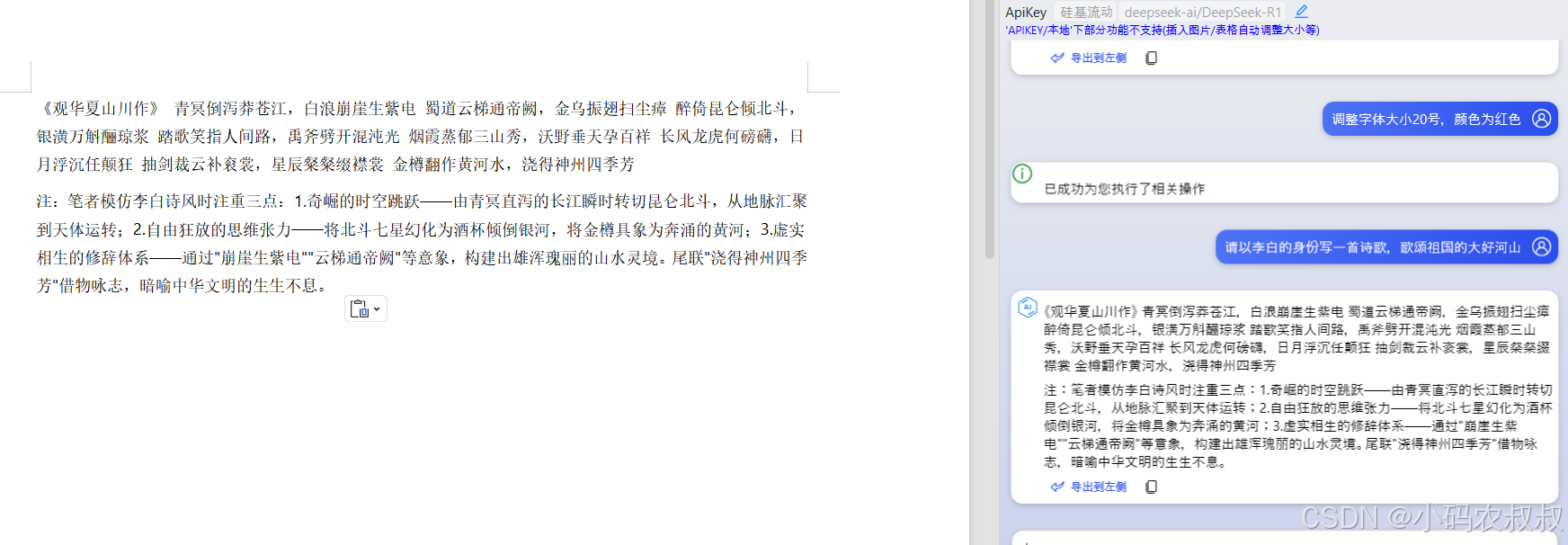
系统基于RAG(检索增强生成)技术,允许用户上传PDF并进行智能问答。
-
使用Ollama的deepseek-r1模型和FAISS向量数据库,支持普通对话和基于PDF的问答模式。
-
提供简洁的Web界面,支持文件拖拽上传和多轮对话。
-
研究表明,系统适合处理PDF内容查询,但性能可能因PDF复杂性而异。
系统概述
这个PDF智能问答系统是一个基于RAG技术的工具,旨在帮助用户通过上传PDF文件进行智能交互。它结合了Ollama的deepseek-r1模型和FAISS向量数据库,确保回答基于文档知识,适合学生、专业人士和研究人员快速获取PDF信息。
主要功能
-
PDF处理:支持上传PDF文件,自动分块,并使用FAISS存储内容。
-
问答模式:提供普通对话模式(无PDF)和文档问答模式(有PDF),支持多轮对话。
-
用户界面:简洁的Web界面,支持拖拽上传,实时显示对话,并提供清空和重新生成功能。
技术细节
系统使用LangChain库处理PDF,Gradio构建界面,需安装ollama并确保deepseek-r1模型可用。环境配置包括创建虚拟环境和安装依赖,如langchain、faiss-cpu等。
详细报告
引言
PDF智能问答系统!该系统利用检索增强生成(RAG)技术,根据您上传的PDF文件内容提供准确且上下文相关的回答。通过结合大型语言模型和高效的信息检索能力,我们旨在为您创造一个无缝、智能的文档交互体验。
无论您是学生、专业人士还是研究人员,这个工具都能帮助您快速查找和理解PDF中的信息,无需手动搜索。系统设计用户友好,界面简洁,支持文件拖拽上传和实时对话,适合各种用户群体。
主要功能
PDF文件处理
-
上传和分块:您可以上传任何PDF文件,系统会自动将其分解为可管理的块。这有助于高效索引和检索信息。
-
向量数据库存储:我们使用FAISS(Facebook AI Similarity Search),一个高性能向量数据库,存储这些块的嵌入表示。这确保了当您提问时,能够快速、准确地检索相关信息。
智能问答功能
-
两种操作模式:
-
普通对话模式:当未上传PDF时,系统作为标准聊天机器人运行,使用基础模型回答一般问题。
-
文档问答模式:上传PDF后,系统切换到此模式,从PDF中检索相关信息以回答问题,确保答案具体且准确。
-
-
上下文维护:系统跟踪对话历史,支持多轮对话。这意味着您可以提出后续问题,系统会理解之前的上下文。
用户界面
-
简洁直观:我们的Web界面设计简单,您可以拖放PDF文件上传,聊天窗口支持实时交互。
-
交互控制:提供清空对话历史和重新生成回答的功能,让您掌控对话,确保流畅的用户体验。
工作原理
系统的核心是检索增强生成(RAG)方法。以下是简化后的工作流程:
PDF上传和处理
-
当您上传PDF时,系统使用LangChain库中的
RecursiveCharacterTextSplitter将其加载并分割为较小的块。 -
每个块使用Ollama的
deepseek-r1模型嵌入(转换为计算机可理解的数值表示),并存储在FAISS向量数据库中。
问题回答
-
当您提问时,系统首先检查是否上传了PDF。
-
如果上传了PDF,它会使用FAISS向量存储的检索器找到与问题最相关的块。
-
然后,这些相关块和您的提问一起传递给
deepseek-r1模型,生成基于两者结合的回答。 -
如果未上传PDF,模型会基于其预训练知识回答问题。
研究表明,这种方法在处理文档查询时效果显著,但PDF内容的复杂性(如图表或格式问题)可能影响性能。证据倾向于认为,对于结构化文本,系统表现最佳,但对于复杂文档,可能需要调整分块参数。
开始使用
要开始使用我们的PDF智能问答系统,请按照以下步骤操作:
-
设置环境:
-
创建并激活虚拟环境,如下所示:
conda create --name rag python=3.12 conda activate rag
-
安装所有必要依赖:
pip install langchain faiss-cpu gradio PyMuPDF pip install -U langchain-community
-
安装并运行ollama,确保
deepseek-r1模型可用。您可以通过ollama list列出可用模型,并使用ollama pull deepseek-r1拉取模型。
-
-
运行应用程序:
-
导航到包含源代码的目录。
-
运行创建并启动Gradio界面的脚本。
-
-
访问Web界面:
-
打开浏览器,访问启动Gradio应用时提供的URL(通常为http://127.0.0.1:8888)。
-
上传您的PDF:
-
将PDF文件拖放到指定区域。
-
提出问题:
-
在文本框中输入问题并发送。
-
根据需要与系统交互,使用提供的控件。
-
通过这些步骤,您可以开始探索并受益于我们的智能问答系统。
技术细节
对于技术感兴趣的用户,以下是简要概述:
-
模型:我们使用Ollama的
deepseek-r1模型,这是一个能够理解和生成类人文本的大型语言模型。 -
嵌入:使用相同的模型为PDF块生成嵌入,确保语义空间的一致性。
-
向量存储:使用FAISS(Facebook AI Similarity Search)进行大规模相似性搜索,这对于快速检索相关信息至关重要。
-
用户界面:使用Gradio(Gradio)构建,这是一个用户友好的机器学习模型Web界面框架。
环境配置
要运行此系统,您需要安装以下内容:
| 步骤 | 命令/说明 |
|---|---|
| 1. 创建虚拟环境 | conda create --name rag python=3.12 然后 conda activate rag |
| 2. 安装依赖 | pip install langchain faiss-cpu gradio PyMuPDF 和 pip install -U langchain-community |
| 3. 安装Ollama | 从官方仓库安装ollama,确保deepseek-r1模型可用,使用ollama pull deepseek-r1拉取 |
| 4. Gradio | 界面使用Gradio构建,已包含在依赖中 |
设置完成后,您可以运行create_chat_interface函数并启动Gradio应用。
源代码分析
源代码结构化处理PDF处理、问答和Gradio界面。以下是关键函数的概述:
| 函数名 | 功能描述 |
|---|---|
| processpdf | 处理PDF加载,分块,创建嵌入,并设置向量存储和检索器 |
| combine_docs | 将多个文档块合并为单个字符串,用于上下文 |
| ollama_llm | 使用ollama模型基于问题和提供的上下文生成回答 |
| rag_chain | 实现RAG管道,检索相关文档并生成回答 |
| chat_interface | 管理聊天交互,根据PDF上传决定使用RAG模式或标准模式 |
| create_chat_interface | 设置Gradio界面,包括文件上传、聊天显示和用户输入组件 |
通过理解这些组件,您可以欣赏系统如何整合不同技术,提供高效的问答体验。
结论
我们的PDF智能问答系统是一个强大的工具,结合了自然语言处理和信息检索的最新进展。设计目的是使与PDF文档的交互更高效、更具洞察力。我们希望您发现它实用且易用!
关键引用
-
Facebook AI Similarity Search
-
Gradio
完整代码
import gradio as gr
from langchain_community.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain_community.embeddings import OllamaEmbeddings
import ollama
import re
def process_pdf(pdf_bytes):"""处理PDF文件并创建向量存储Args:pdf_bytes: PDF文件的路径Returns:tuple: 文本分割器、向量存储和检索器"""if pdf_bytes is None:return None, None, None# 加载PDF文件loader = PyMuPDFLoader(pdf_bytes)data = loader.load()# 创建文本分割器,设置块大小为500,重叠为100text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)chunks = text_splitter.split_documents(data)# 使用Ollama的deepseek-r1模型创建嵌入embeddings = OllamaEmbeddings(model="deepseek-r1:8b")# 将Chroma替换为FAISS向量存储vectorstore = FAISS.from_documents(documents=chunks, embedding=embeddings)# 从向量存储中创建检索器retriever = vectorstore.as_retriever()# # 返回文本分割器、向量存储和检索器return text_splitter, vectorstore, retriever
def combine_docs(docs):"""将多个文档合并为单个字符串Args:docs: 文档列表Returns:str: 合并后的文本内容"""return "\n\n".join(doc.page_content for doc in docs)
def ollama_llm(question, context, chat_history):"""使用Ollama模型生成回答Args:question: 用户问题context: 相关上下文chat_history: 聊天历史记录Returns:str: 模型生成的回答"""# 构建更清晰的系统提示和用户提示system_prompt = """你是一个专业的AI助手。请基于提供的上下文回答问题。- 回答要简洁明了,避免重复- 如果上下文中没有相关信息,请直接说明- 保持回答的连贯性和逻辑性"""# 只保留最近的3轮对话历史,避免上下文过长recent_history = chat_history[-3:] if len(chat_history) > 3 else chat_historychat_history_text = "\n".join([f"Human: {h}\nAssistant: {a}" for h, a in recent_history])# 构建更结构化的提示模板user_prompt = f"""基于以下信息回答问题:问题:{question}相关上下文:{context}请用中文回答上述问题。回答要简洁准确,避免重复。"""# 调用Ollama模型生成回答response = ollama.chat(model="deepseek-r1:8b",messages=[{"role": "system", "content": system_prompt},{"role": "user", "content": user_prompt}])response_content = response["message"]["content"]# 移除思考过程和可能的重复内容final_answer = re.sub(r"<think>.*?</think>", "", response_content, flags=re.DOTALL).strip()return final_answer
def rag_chain(question, text_splitter, vectorstore, retriever, chat_history):"""实现RAG(检索增强生成)链Args:question: 用户问题text_splitter: 文本分割器vectorstore: 向量存储retriever: 检索器chat_history: 聊天历史Returns:str: 生成的回答"""# 减少检索文档数量,提高相关性retrieved_docs = retriever.invoke(question, {"k": 2})# 优化文档合并方式,去除可能的重复内容formatted_content = "\n".join(set(doc.page_content.strip() for doc in retrieved_docs))return ollama_llm(question, formatted_content, chat_history)
def chat_interface(message, history, pdf_bytes=None, text_splitter=None, vectorstore=None, retriever=None):"""聊天接口函数,处理用户输入并返回回答Args:message: 用户消息history: 聊天历史pdf_bytes: PDF文件text_splitter: 文本分割器vectorstore: 向量存储retriever: 检索器Returns:str: 生成的回答"""if pdf_bytes is None:# 无PDF文件的普通对话模式response = ollama_llm(message, "", history)else:# 有PDF文件的RAG对话模式response = rag_chain(message, text_splitter, vectorstore, retriever, history)return response
def create_chat_interface():"""创建Gradio聊天界面
Returns:gr.Blocks: Gradio界面对象"""# 创建一个用户界面,并应用了一些自定义的CSS样式。with gr.Blocks() as demo:# 定义状态变量用于存储PDF处理相关的对象pdf_state = gr.State(None) # 存储文本分割器对象,用于将PDF文本分割成小块text_splitter_state = gr.State(None) # 存储向量数据库对象,用于存储文本向量vectorstore_state = gr.State(None) # 存储检索器对象,用于检索相关文本片段retriever_state = gr.State(None)
with gr.Column(elem_classes="container"):# 创建界面组件with gr.Column(elem_classes="header"):gr.Markdown("# PDF智能问答助手")gr.Markdown("上传PDF文档,开始智能对话")
# 文件上传区域with gr.Column(elem_classes="file-upload"):file_output = gr.File(label="上传PDF文件",file_types=[".pdf"],file_count="single")# 处理PDF上传def on_pdf_upload(file):"""处理PDF文件上传Args:file: 上传的文件对象Returns:tuple: 包含处理后的PDF相关对象"""# 如果文件存在if file is not None:# 处理PDF文件,获取文本分割器、向量存储和检索器text_splitter, vectorstore, retriever = process_pdf(file.name)# 返回文件对象和处理后的组件return file, text_splitter, vectorstore, retriever# 如果文件不存在,返回None值return None, None, None, None# 注册文件上传事件处理file_output.upload(# 当文件上传时调用on_pdf_upload函数处理on_pdf_upload, # inputs参数指定输入组件为file_outputinputs=[file_output],# outputs参数指定输出状态变量outputs=[pdf_state, text_splitter_state, vectorstore_state, retriever_state])
# 聊天区域with gr.Column(elem_classes="chat-container"):chatbot = gr.Chatbot(height=500,bubble_full_width=False,show_label=False,avatar_images=None,elem_classes="chatbot")with gr.Row():msg = gr.Textbox(label="输入问题",placeholder="请输入你的问题...",scale=12,container=False)send_btn = gr.Button("发送", scale=1, variant="primary")
with gr.Row(elem_classes="button-row"):clear = gr.Button("清空对话", variant="secondary")regenerate = gr.Button("重新生成", variant="secondary")
# 发送消息处理函数def respond(message, chat_history, pdf_bytes, text_splitter, vectorstore, retriever):"""处理用户消息并生成回答Args:message: 用户消息chat_history: 聊天历史pdf_bytes: PDF文件text_splitter: 文本分割器vectorstore: 向量存储retriever: 检索器Returns:tuple: (清空的消息框, 更新后的聊天历史)"""# 如果用户消息为空(去除首尾空格后),直接返回空消息和原聊天历史if not message.strip():return "", chat_history# 调用chat_interface函数处理用户消息,生成回复bot_message = chat_interface(message, chat_history, pdf_bytes, text_splitter, vectorstore, retriever)# 将用户消息和模型回复作为一轮对话添加到聊天历史中chat_history.append((message, bot_message))# 返回空消息(清空输入框)和更新后的聊天历史return "", chat_history
# 事件处理# 当用户按回车键提交消息时触发msg.submit(respond,[msg, chatbot, pdf_state, text_splitter_state, vectorstore_state, retriever_state],[msg, chatbot])# 当用户点击发送按钮时触发send_btn.click(respond,[msg, chatbot, pdf_state, text_splitter_state, vectorstore_state, retriever_state],[msg, chatbot])# 当用户点击清空按钮时触发# lambda: (None, None) 返回两个None值来清空消息框和对话历史# queue=False 表示不进入队列直接执行clear.click(lambda: (None, None), None, [msg, chatbot], queue=False)# 重新生成按钮功能def regenerate_response(chat_history, pdf_bytes, text_splitter, vectorstore, retriever):"""重新生成最后一条回答Args:chat_history: 聊天历史pdf_bytes: PDF文件text_splitter: 文本分割器vectorstore: 向量存储retriever: 检索器Returns:list: 更新后的聊天历史"""# 如果聊天历史为空,直接返回if not chat_history:return chat_history# 获取最后一条用户消息last_user_message = chat_history[-1][0]# 移除最后一轮对话chat_history = chat_history[:-1] # 使用chat_interface重新生成回答bot_message = chat_interface(last_user_message, # 最后一条用户消息chat_history, # 更新后的聊天历史pdf_bytes, # PDF文件内容text_splitter, # 文本分割器vectorstore, # 向量存储retriever # 检索器)# 将新生成的对话添加到历史中chat_history.append((last_user_message, bot_message))# 返回更新后的聊天历史return chat_history
# 为重新生成按钮绑定点击事件# 当点击时调用regenerate_response函数# 输入参数为chatbot等状态# 输出更新chatbot显示regenerate.click(regenerate_response,[chatbot, pdf_state, text_splitter_state, vectorstore_state, retriever_state],[chatbot])
return demo
# 启动接口
if __name__ == "__main__":"""主程序入口:启动Gradio界面"""demo = create_chat_interface()demo.launch(server_name="127.0.0.1", server_port=8888,show_api=False,share=False)