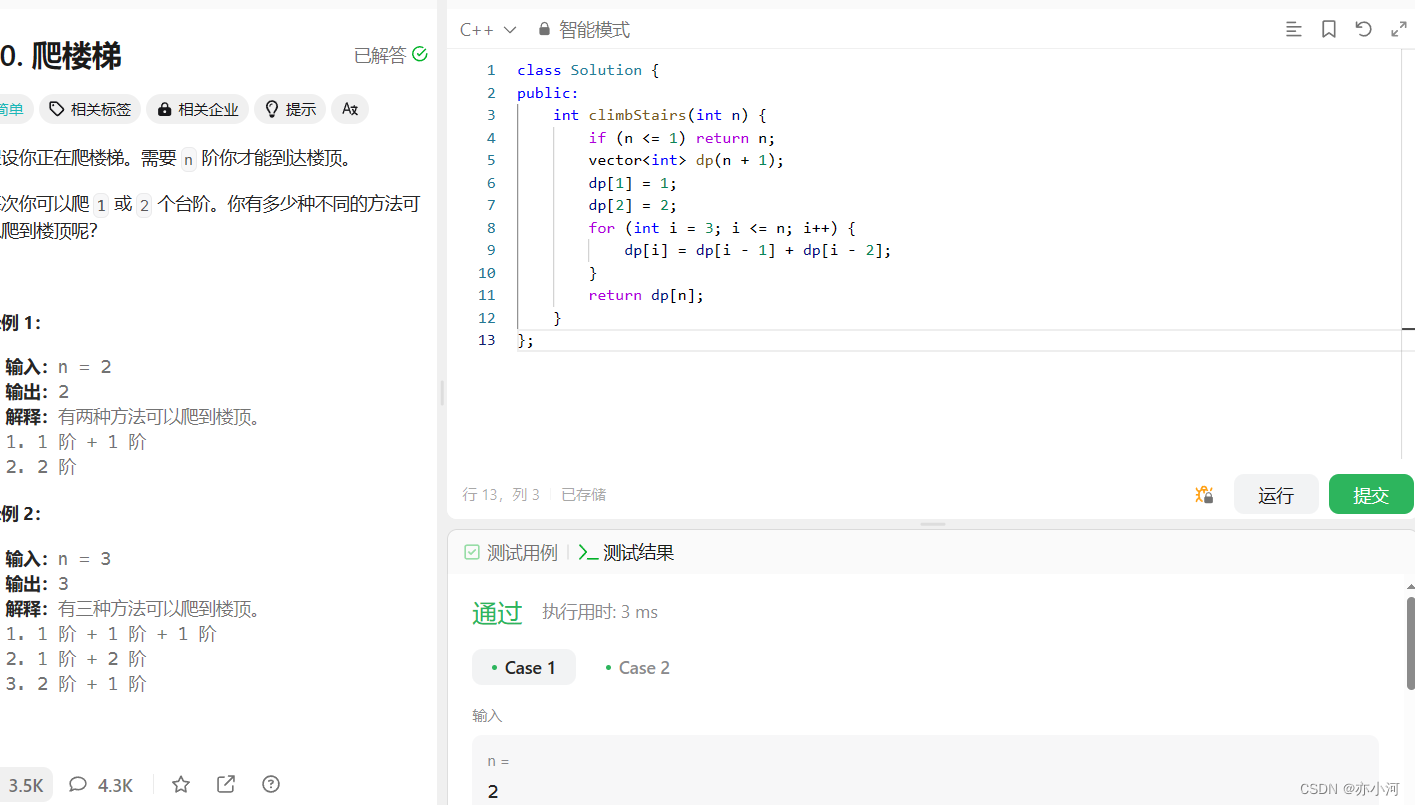
今天分享的是AI算力专题系列深度研究报告:《算力大时代,AI算力产业链全景梳理》。
(报告出品方:中信建投证券)
报告共计:98页
核心观点
生成式 AI取得突破,我们对生成式 A 带来的算力需求做了上下游梳理,并做了交叉验证,可以看到以chatGPT 为代表的大模型训练和推理端均需要强大的算力支撑,产业链共振明显,产业链放量顺序为:先进制程制造->以chiplet 为代表的2.5D/3D 封装、HBM->AI 芯片->板卡组装->交换机->光模块-液冷->AI 服务器->IDC 出租运维。综合来看,大模型仍处于混战阶段,应用处于渗透率早期,AI板块中算力需求增长的确定性较高,在未来两年时间内,算力板块都将处于高景气度阶段,重点推荐 AI算力产业链各环节相关公司。
摘要
生成式 AI取得突破,实现了从0到1的跨越,以ChatGPT为代表的人工智能大模型训练和推理需要强大的算力支撑。自2022 年底 OpenAl正式推出ChatGPT后,用户量大幅增长,围绕ChatGPT 相关的应用层出不穷,其通用性能力帮助人类在文字等工作上节省了大量时间。同时在Transformer 新架构下,多模态大模型也取得新的突破,文生图、文生视频等功能不断完善,并在广告、游戏等领域取得不错的进展。生成式A将是未来几年最重要的生产力工具,并深刻改变各个产业环节,围绕生成式A,无论是训练还是推理端,算力需求都将有望爆发式增长。
训练和推理端 AI算力需求或几何倍数增长。首先是训练侧参考 OpenAl论文,大模型训练侧算力需求=训练所需要的token数量*6*大模型参数量。可以看到从GPT3.5到GPT4,模型效果越来越好,模型也越来越大,训练所需要的token 数量和参数量均大幅增长,相应的训练算力需求也大幅增长。并且,与GPT4相关的公开论文也比较少,各家巨头向GPT4迈进的时候,需要更多方向上的探索,也将带来更多的训练侧算力需求。根据我们的推算,2023年-2027年,全球大模型训练端峰值算力需求量的年复合增长率有望达到78.0%,2023年全球大模型训练端所需全部算力换算成的 A100 芯片总量可能超过200万张。其次是推理侧,单个 token 的推理过程整体运算量为2*大模型参数量,因此大模型推理侧每日算力需求=每日调用大模型次数*每人平均查询 Token 数量*2*大模型参数量,仅以 Google 搜索引擎为例,每年调用次数至少超过2万亿,一旦和大模型结合,其A1算力需求将十分可观。随着越来越多的应用和大模型结合,推理侧算力需求也有望呈现爆发增长势头。根据我们的推算,2023年-2027年,全球大模型云端推理的峰值算力需求量的年复合增长率有望高达113%。
算力产业链价值放量顺序如下:先进制程制造->以chiplet为代表的 2.5D/3D封装、HBM->AI芯片->板卡组装->交换机->光模块->液冷->AI服务器->IDC 出租运维。
先进封装、HBM:为了解决先进制程成本快速提升和“内存墙”等问题,Chiplet 设计+异构先进封装成为性能与成本平衡的最佳方案,台积电开发的CoWos封装技术可以实现计算核心与HBM 通过 2.5D封装互连,因此英伟达 A100、H100等A1芯片纷纷采用台积电CoWos封装,并分别配备40GBHBM2E、80GB的HBM3内存。全球晶圆代工龙头台积电打造全球 2.5D/3D 先进封装工艺标杆,未来几年封装市场增长主要受益于先进封装的扩产。先进封装市场的快速增长,有望成为国内品圆代工厂商(中芯国际)与封测厂商(长电科技、通富微电、甬矽电子和深科技)的新一轮成长驱动力。
AI芯片/板卡封装:以英伟达为代表,今年二季度开始释放业绩。模型训练需要规模化的算力芯片部署于智能服务器,CPU不可或缺,但性能提升遭遇瓶颈,CPU+xPU异构方案成为大算力场景标配。其中GPU并行计算优势明显,CPU+GPU成为目前最流行的异构计算系统,而NPU在特定场景下的性能、效率优势明显,推理端应用潜力巨大,随着大模型多模态发展,硬件需求有望从GPU扩展至周边编解码硬件。A1加速芯片市场上,英伟达凭借其硬件产品性能的先进性和生态构建的完善性处于市场领导地位,在训练、推理端均占据领先地位。根据 Liftr nsights 数据,2022年数据中心 A1 加速市场中,英伟达份额达 82%。因此 A1 芯片需求爆发,英伟达最为受益,其 Q2收入指引 110亿美金,预计其数据中心芯片业务收入接近翻倍。国内厂商虽然在硬件产品性能和*业链生态架构方面与前者有所差距,但正在逐步完善产品布局和生态构建,不断缩小与行业龙头厂商的差距,并且英伟达、AMD对华供应高端 GPU芯片受限,国产算力芯片迎来国产替代窗口期。当前已经涌现出一大批国产算力芯片厂商:1)寒武纪:国内人工智能芯片领军者,持续强化核心竞争力:2)海光信息:深算系列GPGPU提供高性能算力,升级迭代稳步推进:3)龙芯中科:自主架构CPU行业先行者,新品频发加速驱动成长;4)芯原股份:国内半导体IP龙头,技术储备丰富驱动成长:5)工业富联:提供GPU芯片板块组装服务。
交换机:与传统数据中心的网络架构相比,A1数据网络架构会带来更多的交换机端口的需求。交换机具备技术壁垒,中国市场格局稳定,华为与新华三(紫光股份)两强争,锐捷网络展现追赶势头,建议重点关注。
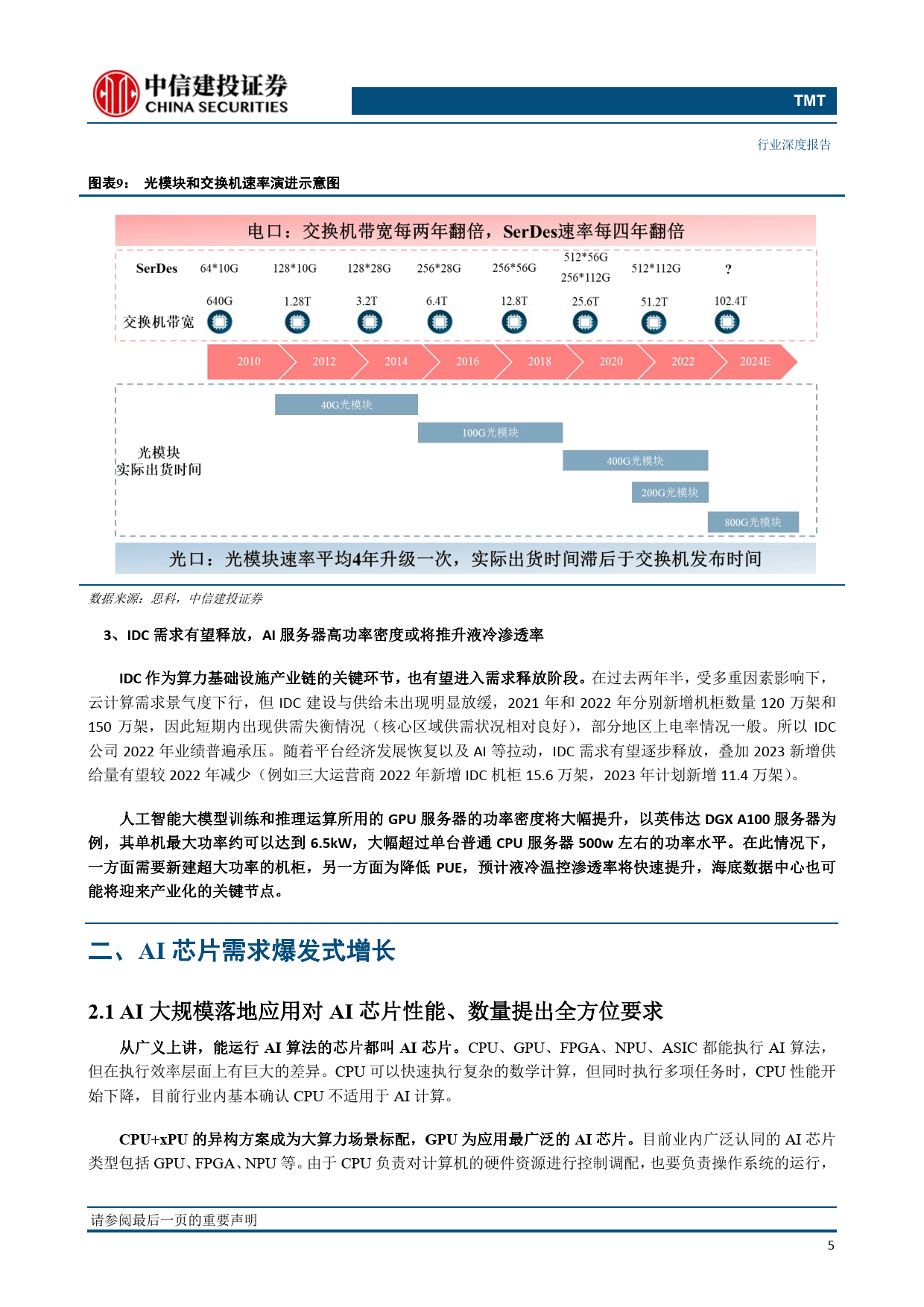
光模块:AI 算力带动数据中心内部数据流量较大,光模块速率及数量均有显著提升。训练侧光模块需求与GPU 出货量强相关,推理侧光模块需求与数据流量强相关,伴随应用加速渗透,未来推理所需的算力和流量实际上可能远大于训练。目前,训练侧英伟达的 A100 GPU 主要对应 200G光模块和 400G光模块,H100 GPU 可以对应 400G或 800G光模块。根据我们的测算,训练端 A100和 200G光模块的比例是1:7,H100和800G光模块的比例是 1:3.5。800G 光模块 2022年底开始小批量出货,2023 年需求主要来自于英伟达和谷歌。在 2023 年这个时间点,市场下一代高速率光模块均指向 800G光模块,叠加 AIGC 带来的算力和模型竞赛,我们预计北美名大云厂商和相关科技巨头均有望在 2024年大量采购800G光模块,同时2023年也可能提前采购。
光模块上游--光芯片:以 AWG、PLC等为代表的无源光芯片,国内厂商市占率全球领先。以 EEL、VCSELDFB 等激光器芯片、探测器芯片和调制器芯片为代表的有源光芯片是现代光学技术的重要基石,是有源光器件的重要组成部分。以源杰科技、光库科技为代表的国内光芯片厂商不断攻城拔寨,在多个细分产品领域取得了较大进展,国产替代化加速推进,市场空间广阔。
液冷:AI大模型训练和推理所用的 GPU服务器功率密度将大幅提升,以英伟达DGXA100服务器为例,其单机最大功率约可达到6.5kw,大幅超过单台普通CPU服务器500w 左右的功率水平。根据《冷板式液冷服务器可靠性白皮书》数据显示,自然风冷的数据中心单柜密度一般只支持8kW-10kW,通常液冷数据中心单机柜可支持 30kw 以上的散热能力,并能较好演进到 100kW 以上,相较而言液冷的散热能力和经济性均有明显优势。司时“东数西算” 明确 PUE(数据中心总能耗/T 设备能耗)要求,枢纽节点 PUE要求更高,同时考虑到整体规划布局,未来新增机柜更多将在枢纽节点内,风冷方案在某些地区可能无法严格满足要求,液冷方案渗透率有望加速提升。目前在 A 算力需求的推动下,如浪潮信息、中兴通讯等服务器厂商已经开始大力布局液冷服务器产品。
AI服务器:预计今年 Q2-03开始逐步释放业绩。具体来看,训练型AI服务器成本中,约7成以上中 GPU构成,其余 CPU、存储、内存等占比相对较小,均价常达到百万元以上。对于推理型服务器,其 GPU 成本约为2-3成,整体成本构成与高性能型相近,价格常在 20-30万。根据IDC数据,2022年全球 A1服务器市场规模 202亿美元,同比增长 29.8%,占服务器市场规模的比例为16.4%,同比提升 1.2pct。我们认为全球 AI 服务器市场规模未来3年内将保持高速增长,市场规模分别为395/890/1601亿美元,对应增速96%/125%/80%。根据IDC数据,2022年中国A1服务器市场规模67亿美元,同比增长24%。我们预计,2023-2025年,结合对于全球 A1 服务器市场规模的预判,以及对于我国份额占比持续提升的假设,我国A服务器市场规模有望达到 134/307/561亿美元,同比增长101%/128%/83%。竞争格局方面,考虑到AI服务器研发和投入上需要更充足的资金及技术支持,国内市场的竞争格局预计将继续向头部集中,保持一超多强的竞争格局。重点推荐:1)浪潮信息:全球服务器行业龙头厂商,其 AI服务器多次位列全球市占率第一:2)工业富联:为英伟达提供 H100 等芯片组装,以及 A服务器生产:3)紫光股份:子公司新华三A服务器在手订单饱满,同时可以提供交换机、路由器等:4)中科曙光:高性能计算及国产化服务器龙头;5)中兴通讯:服务器业务快速增长;6)拓维信息:华为昇腾+鲲鹏核心合作伙伴:7)联想集团:全球领先的ICT设备企业。







报告共计:98页
精选报告来源/公众号:海选智库
本文仅供参考,不代表我们的任何投资建议。海选智库整理分享的资料仅推荐阅读,如需使用请参阅报告原文。



![[RK3399 Linux] 使用ubuntu 20.04.5制作rootfs](https://img-blog.csdnimg.cn/direct/ac972cc3684b445abe2d6d0d2a62d116.png#pic_center)