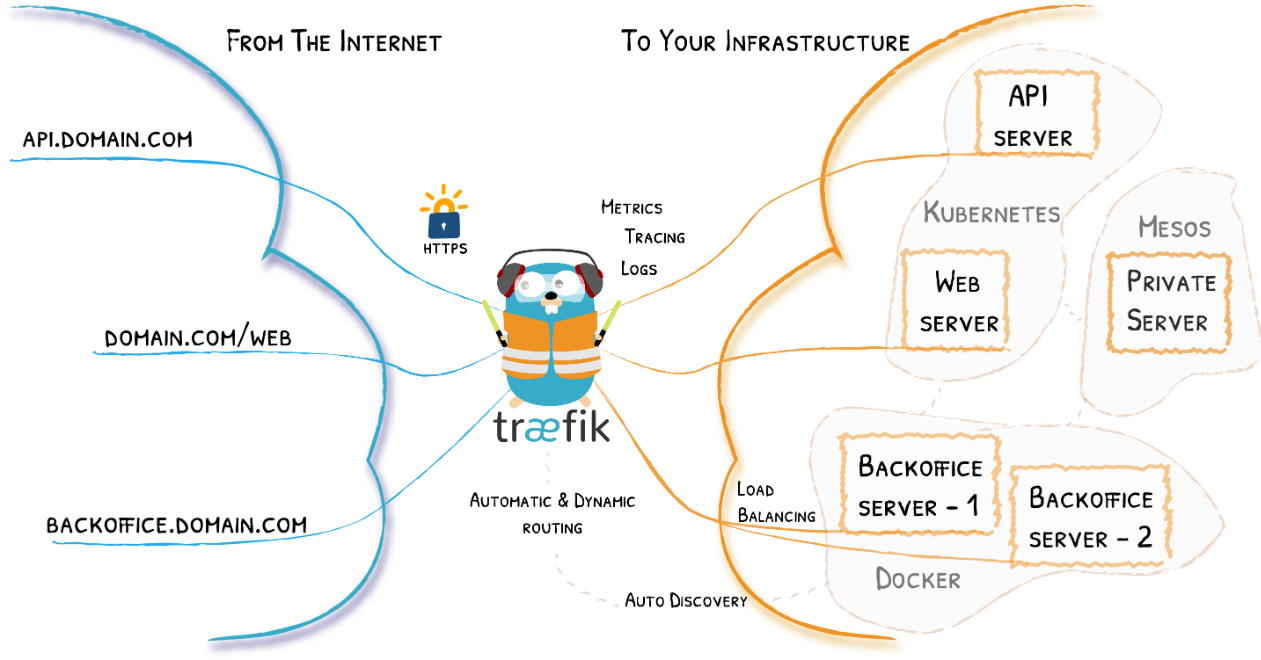
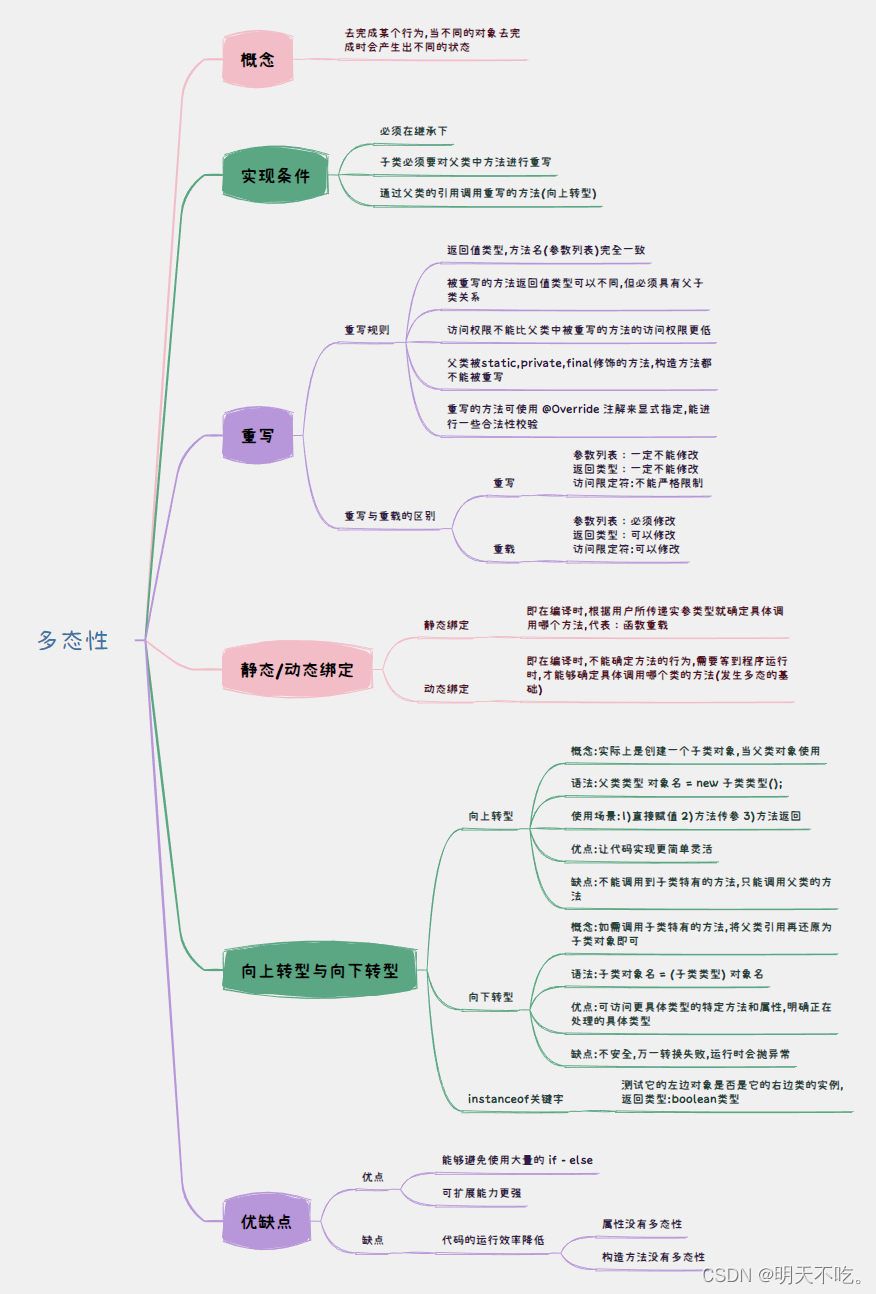
自然语言处理八-transformer实现翻译任务-一(输入)
- transformer架构
- 数据处理部分
- 模型的输入数据(图中inputs outputs outputs_probilities对应的label)
- 以处理英中翻译数据集为例的代码
- positional encoding 位置嵌入
- 代码
鉴于transfomer的重要性,在两篇介绍过transfomer模型理论的基础上,我们将分几篇文章,用pytorch代码实现一个完整的transfomer模型。
下面是之前介绍模型的文章:
自然语言处理六-最重要的模型-transformer-上
自然语言处理六-最重要的模型-transformer-下
transformer架构
在这里重新给出transfomer架构图以及用中文翻译后的对照图:
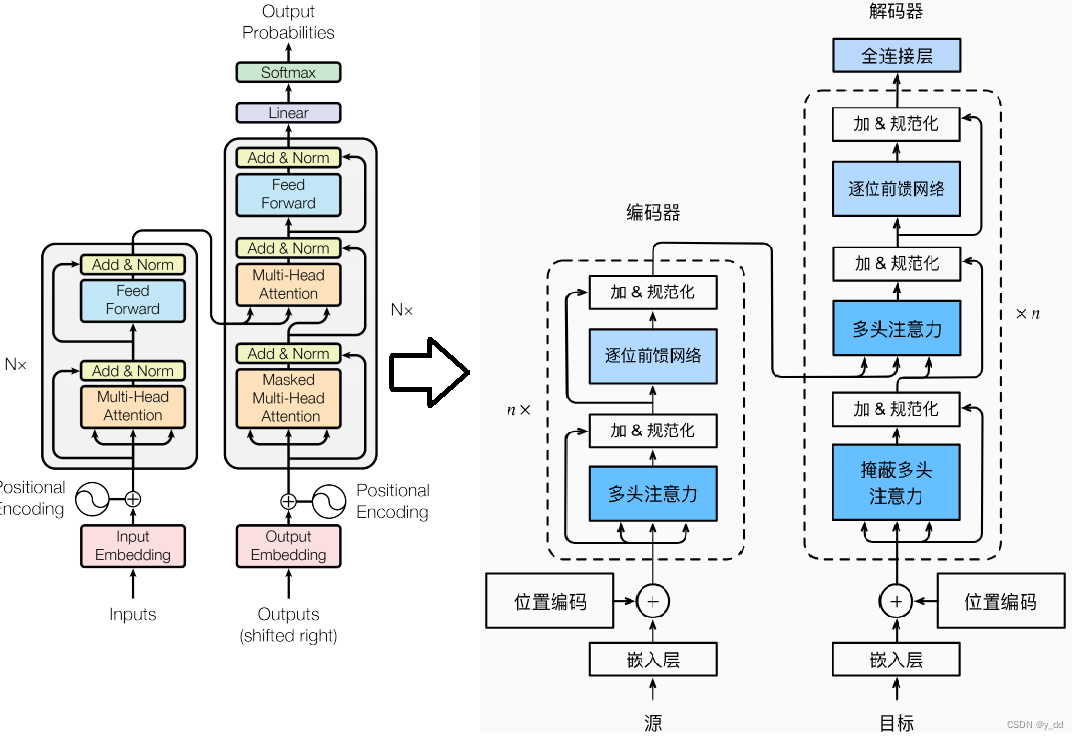
从架构图可以看出实现transformer架构,encoder和decoder大部分相同。因此也规划几篇内容,介绍以下几大块:
-
输入输出部分
处理数据,源和目标以及输出,以及位置编码 -
注意力部分
多头注意力和掩蔽多头注意力 -
前馈网络等
加和归一化,以及逐位前馈网路 -
训练和测试
本篇作为开始,先介绍处理数据部分
数据处理部分
模型的输入数据(图中inputs outputs outputs_probilities对应的label)
这部分用来处理transformer模型需要输入的数据,这部分其实和seq2seq架构是相同的,以自然语言的翻译为例:
比如transformer需要将 ich mochte ein bier 翻译成 i want a beer,那如需要输入的数据格式是这样的(假设句子最大长度5):
[ich mochte ein bier , i want a beer, i want a beer ]
那么上面那部分输入的用途都是什么呢?
encoder输入需要翻译的句子 ich mochte ein bier
decoder输入是 i want a beer
decoder的label是i want a beer
分别对应于图中inputs outputs outputs_probilities相对应的标签
其中是填充字符,用来填充到一个我们超参数中我们设定的sequence的长度
代表句子的开始, 代表句子结束
当然模型真正要处理还是需要根据词汇表转成数字格式的形式,才能被模型处理
以处理英中翻译数据集为例的代码
# -*- coding: utf-8 -*-"""
加载源数据,并处理成data set和data loader
"""
import os
import zipfile
import torch
import torch.utils.data as Data
from src.configs import config
from src.utility.utils import Utils
from src.vocabulay.vocabulary import Vocabularyclass DataSetLoader:"""数据封装成dateset和datelaoder"""def __init__(self, is_train=True, numbers=config.num_examples):"""init parameters"""self.raw_file_path = config.raw_file_pathself.raw_zip_path = config.raw_zip_pathself.batch_size = config.batch_sizeself.num_steps = config.num_stepsself.num_examples = numbersself.is_train = is_traindef load_array(self, data_arrays):"""构造一个数据迭代器:param data_arrays: 输入数据的列表:param is_train: 训练/测试数据集:return: dataloader"""dataset = Data.TensorDataset(*data_arrays)return Data.DataLoader(dataset, self.batch_size, shuffle=self.is_train)def load_data_nmt(self):"""返回翻译数据集的迭代器和词表:return: 迭代器和词表"""source, src_vocab, target, tgt_vocab = build_vocabu()src_array, src_valid_len = self.build_array_nmt(source, src_vocab)tgt_array, tgt_valid_len = self.build_array_nmt(target, tgt_vocab)data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)data_iter = self.load_array(data_arrays)return data_iter, src_vocab, tgt_vocabdef build_array_nmt(self, lines, vocab):"""将机器翻译的文本序列转换成小批量source[['hello', 'world'],..] target[['你'], [好]]source[[]]"""lines = [vocab[l] for l in lines]lines = [l + [vocab['<eos>']] for l in lines]array = torch.tensor([Utils.truncate_pad(l, self.num_steps, vocab['<pad>']) for l in lines])valid_len = Utils.reduce_sum(Utils.astype(array != vocab['<pad>'], torch.int32), 1)return array, valid_lendef extract_content():"""提取raw text中内容:return: raw text"""if not os.path.exists(config.raw_file_path):with zipfile.ZipFile(config.raw_zip_path, 'r') as zip_ref:zip_ref.extractall(os.path.dirname(config.raw_file_path))print('语料解压缩完成')with open(config.raw_file_path, 'r', encoding='UTF-8') as f:content = f.read()return contentdef build_vocabu():"""创建词表:return: 词表"""text = Utils.preprocess_nmt(extract_content())source, target = Utils.tokenize_nmt(text, config.num_examples)src_vocab = Vocabulary(source, min_freq=2)tgt_vocab = Vocabulary(target, min_freq=2)return source, src_vocab, target, tgt_vocab
positional encoding 位置嵌入
为了添加位置信息,transformer的位置嵌入,每个位置的512维的数据用sin/cos做了处理
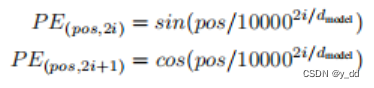
其中pos是在句子中位置,i是维度信息
代码
def get_sinusoid_encoding_table(n_position, d_model):def cal_angle(position, hid_idx):return position / np.power(10000, 2 * (hid_idx // 2) / d_model)def get_posi_angle_vec(position):return [cal_angle(position, hid_j) for hid_j in range(d_model)]其他处理会在后续章节继续实现