Day 18 Spatial Transformer Layer
因为单纯的cNN无法做到scaling(放大)and rotation(转),所以我们引入;
实战中也许我们可以做到 是因为 我们的training data 中包含了对data 的augmentation;
有一些 translation的性质,是因为 max pooling
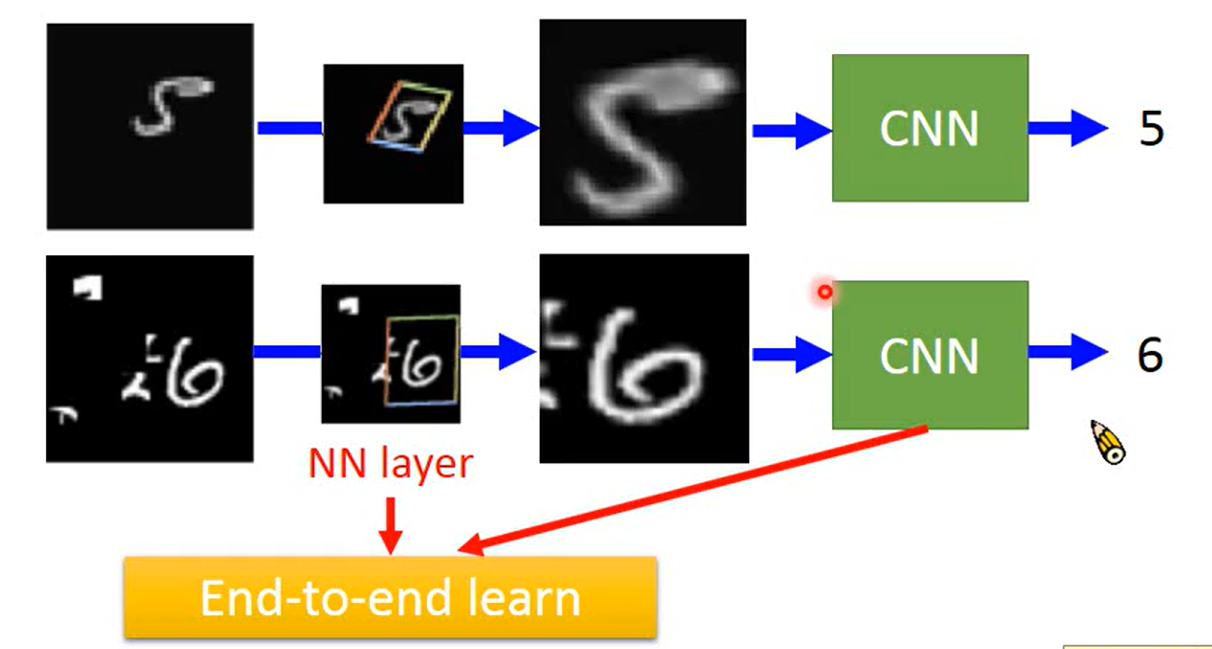
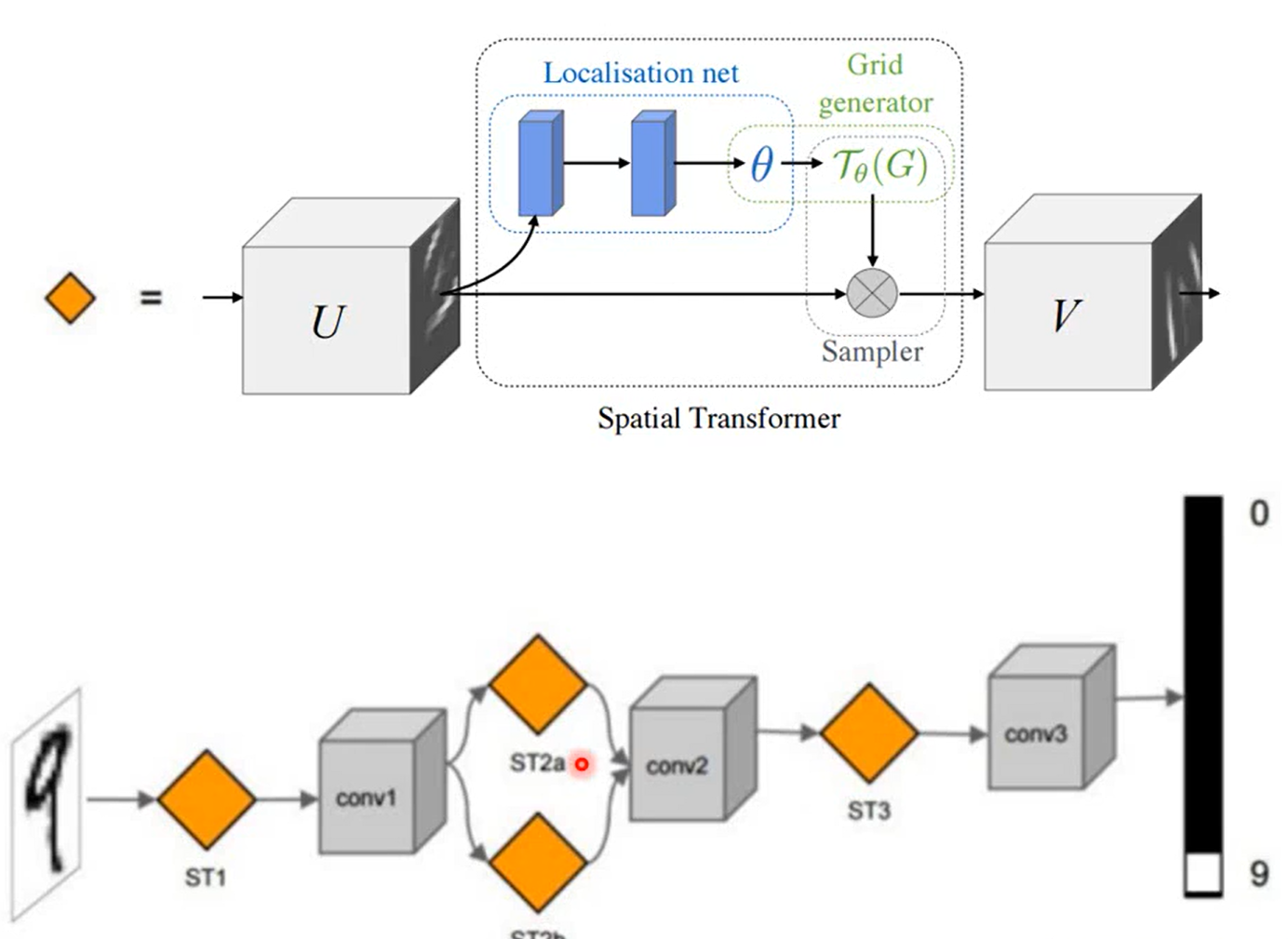
这张ppt好好理解,我感觉它说明了spatial Transformen的 本质
- 专门训练一个layer 对图像进行旋转缩放
- 由于本质上还是一个神经网络结构,所以可以和CNN join it to learn 就是一起训练嘛(End to End)
- 不仅可以对input image 做变换(transform),也可以对CNN 的feature map进行
ok 以上说的三点就是它的特性了,应该没有哪一个是不懂的吧~
至于 why 1 ,下文来介绍它的工作原理
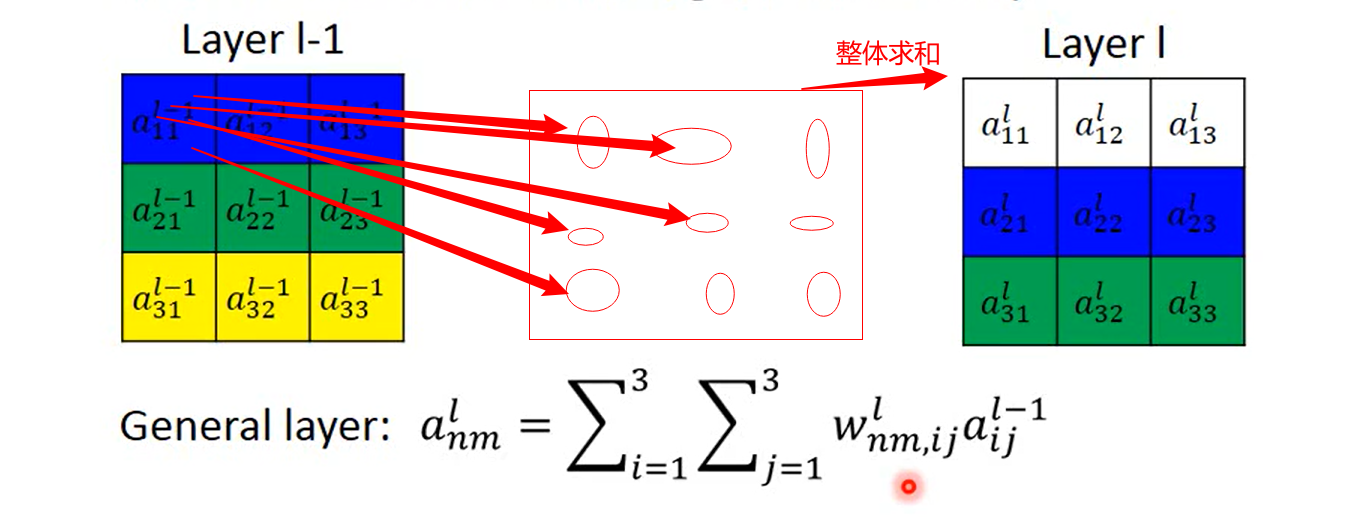
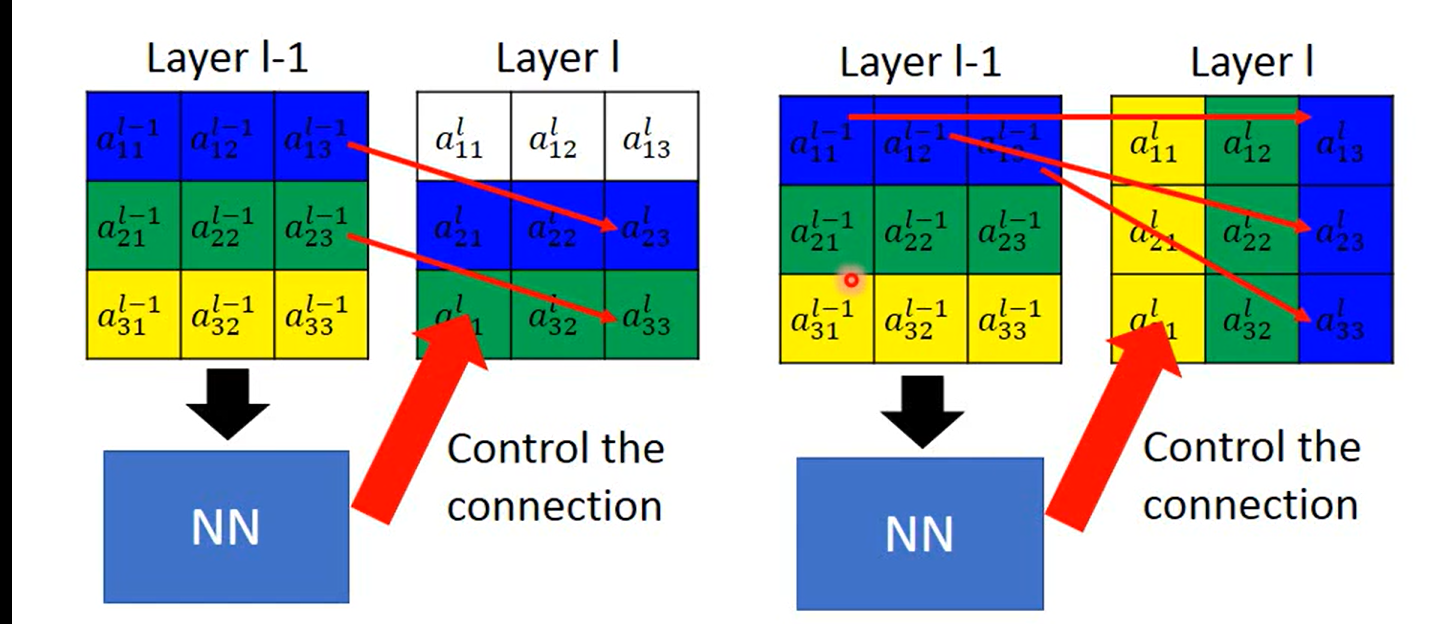
这张图我自己又加了一些笔记, 这里说的 是全连接的工作原理; hope you learned
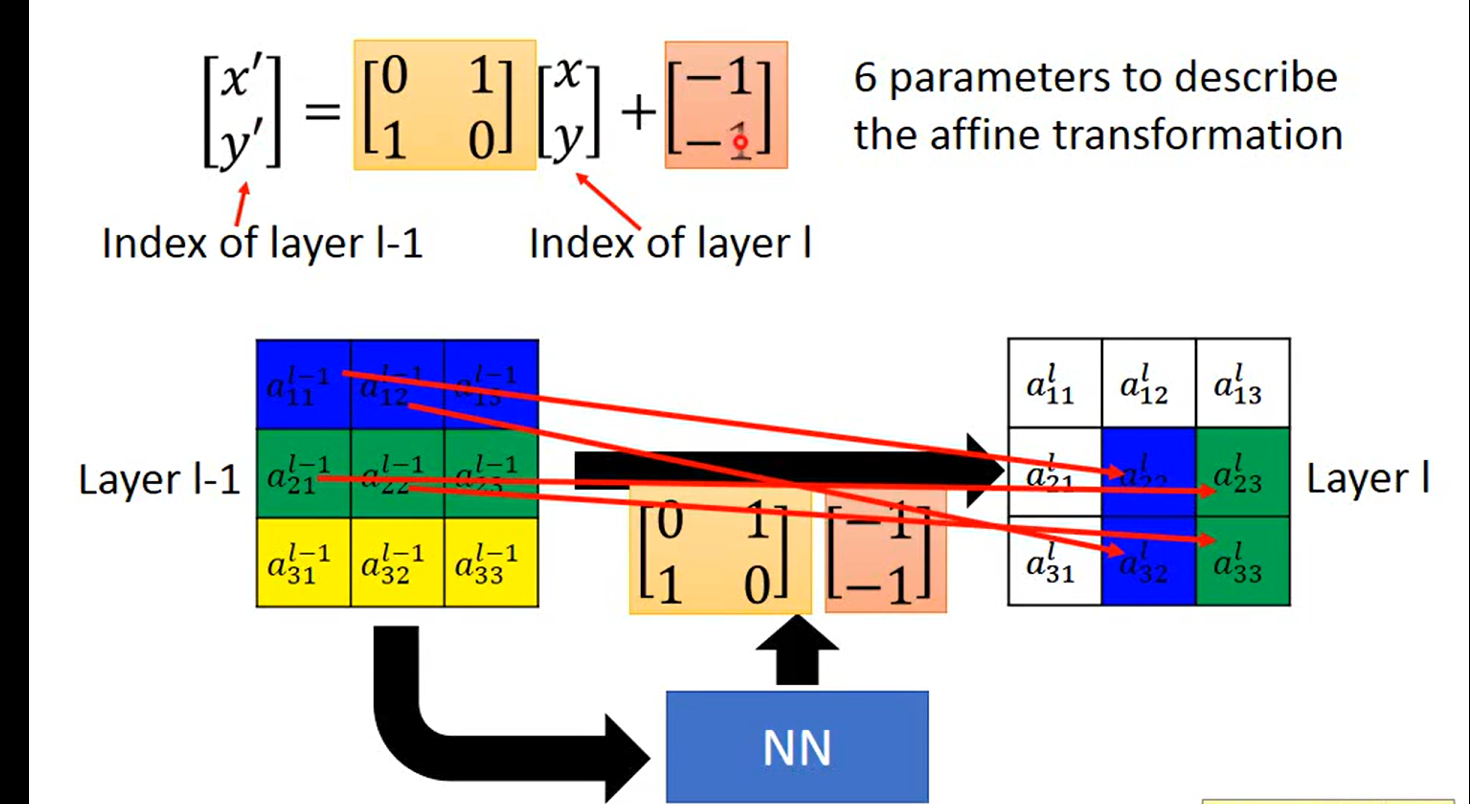
我们可以用全连接来做transform ,例如

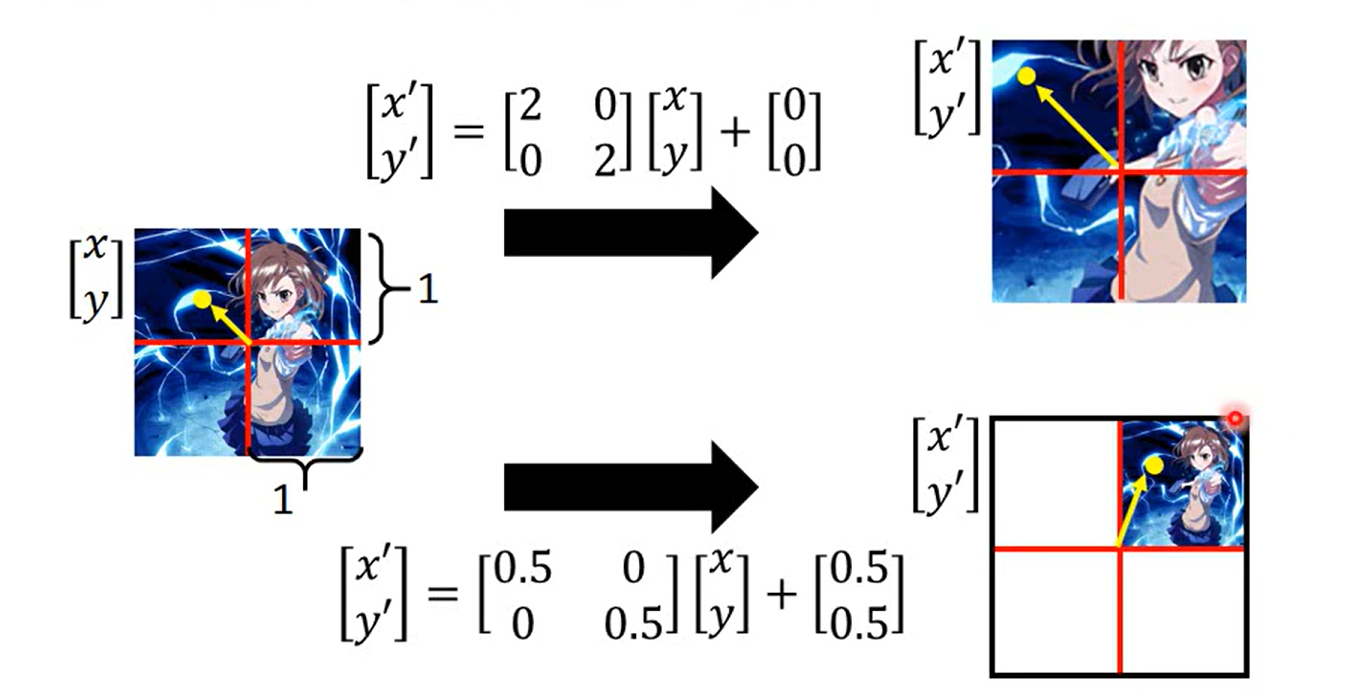
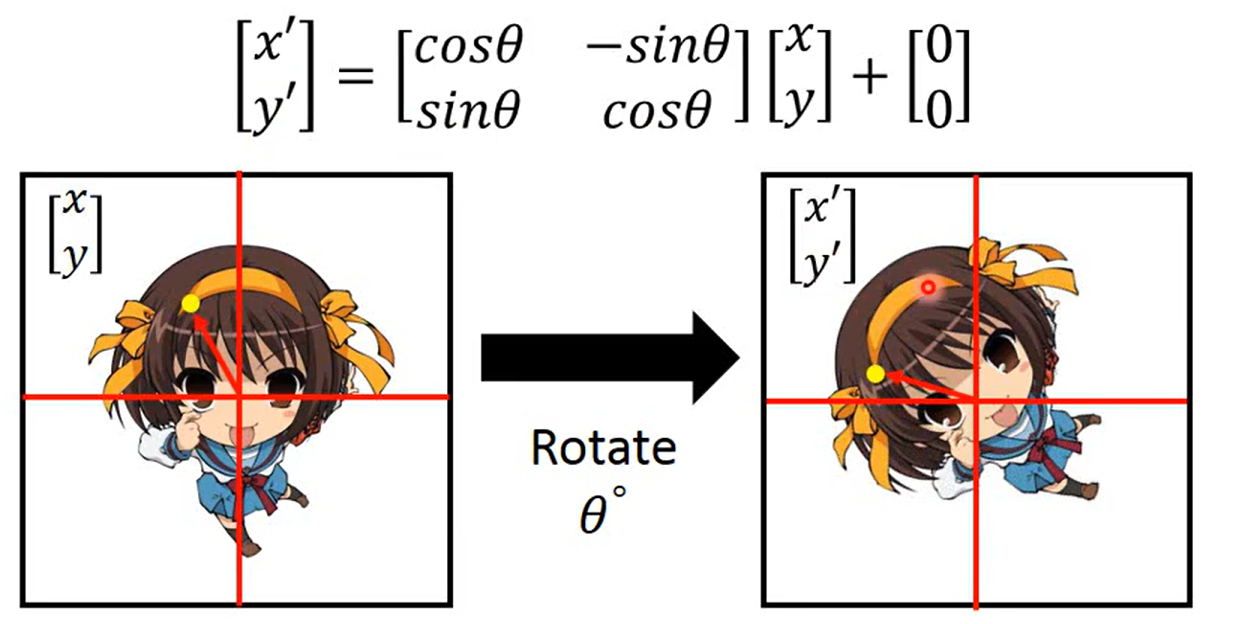
好了,基本学会了,就是数字图像处理学的那点东西,就是乘一个变换矩阵就好了
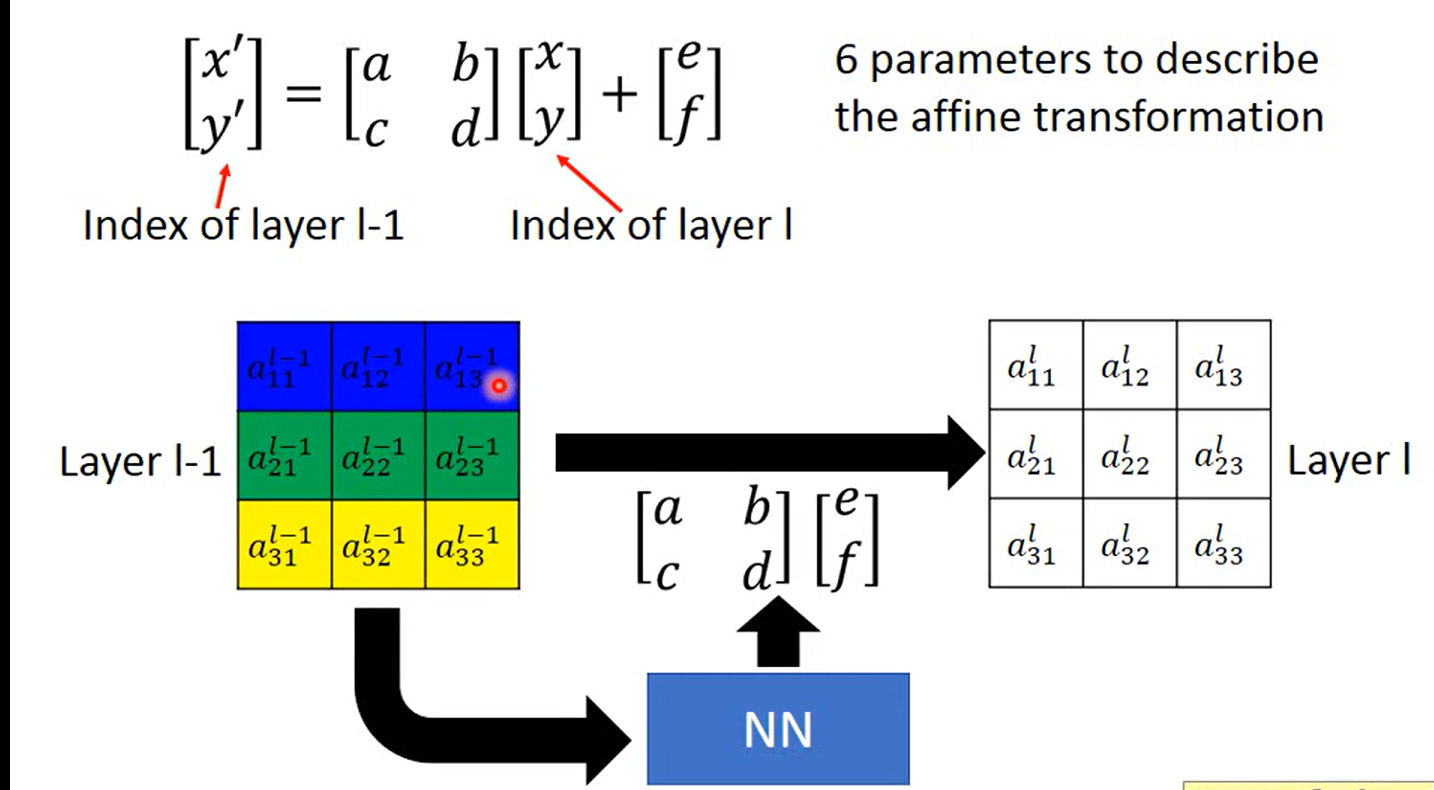
好了,没什么了不起,就是用神经网络 训练出三个变换矩阵
举例:
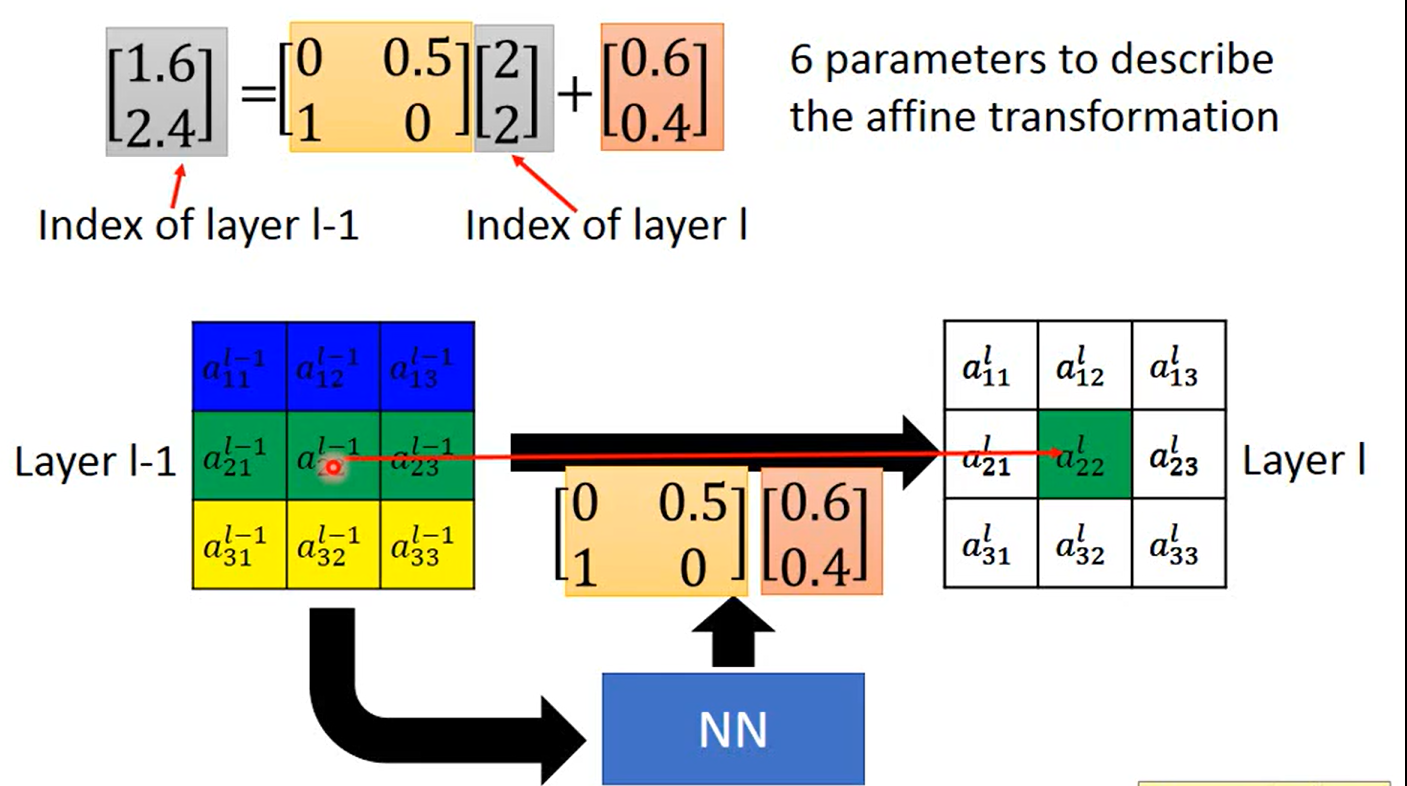
max pooling(IOU 连接网络?) 如何用Gradient Descent 解呢?
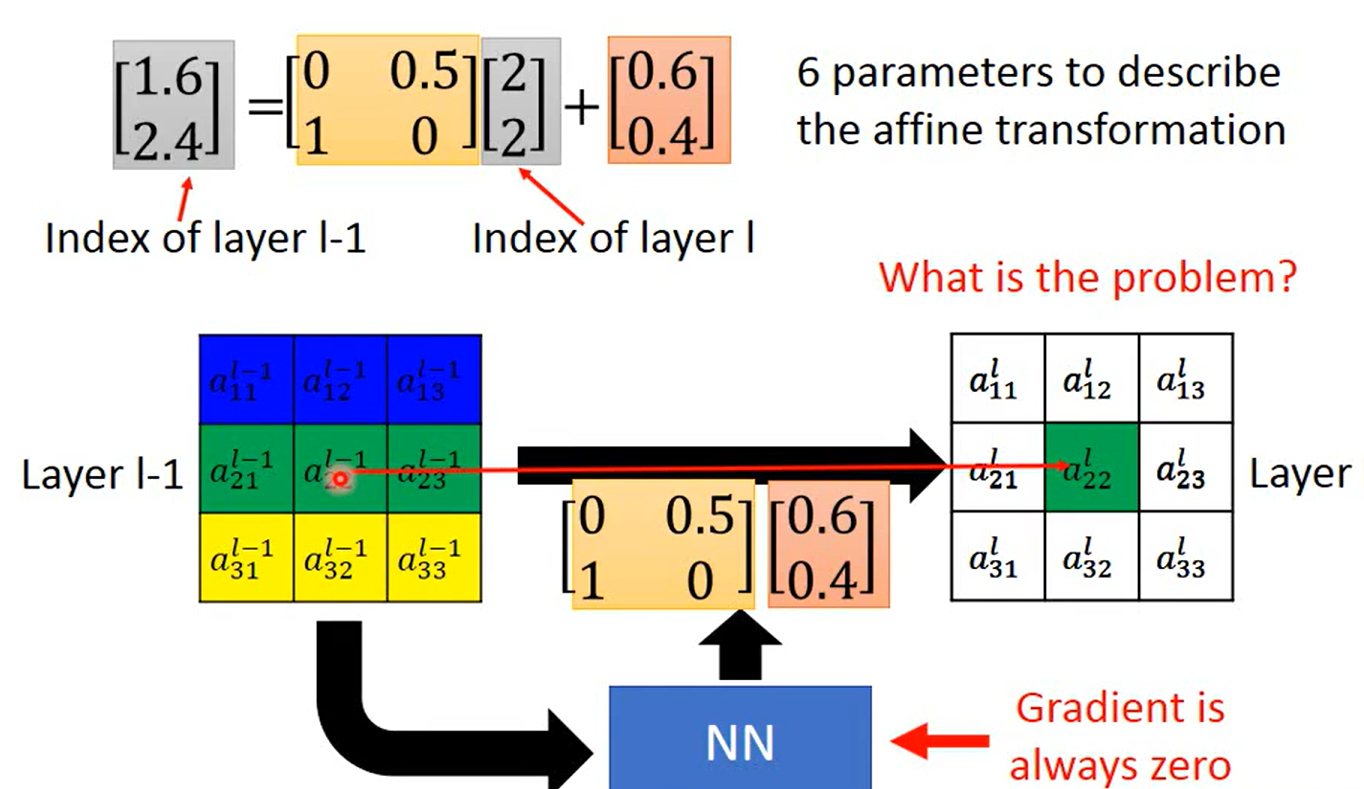
这里老师判断的角度应该是 对于参数的 Δ \Delta Δ w 会有一个 Δ \Delta Δy 与其对应,但是这个case 里面 Δ \Delta Δy = 0; 梯度为0 消失~
这样也能理解为什么老师认为max pooling 可以用来解,因为随着参数的变化,max的值一定会有变化,则可以进行梯度;即使max ()本身是不可微的
Interpolation – 双线性插值
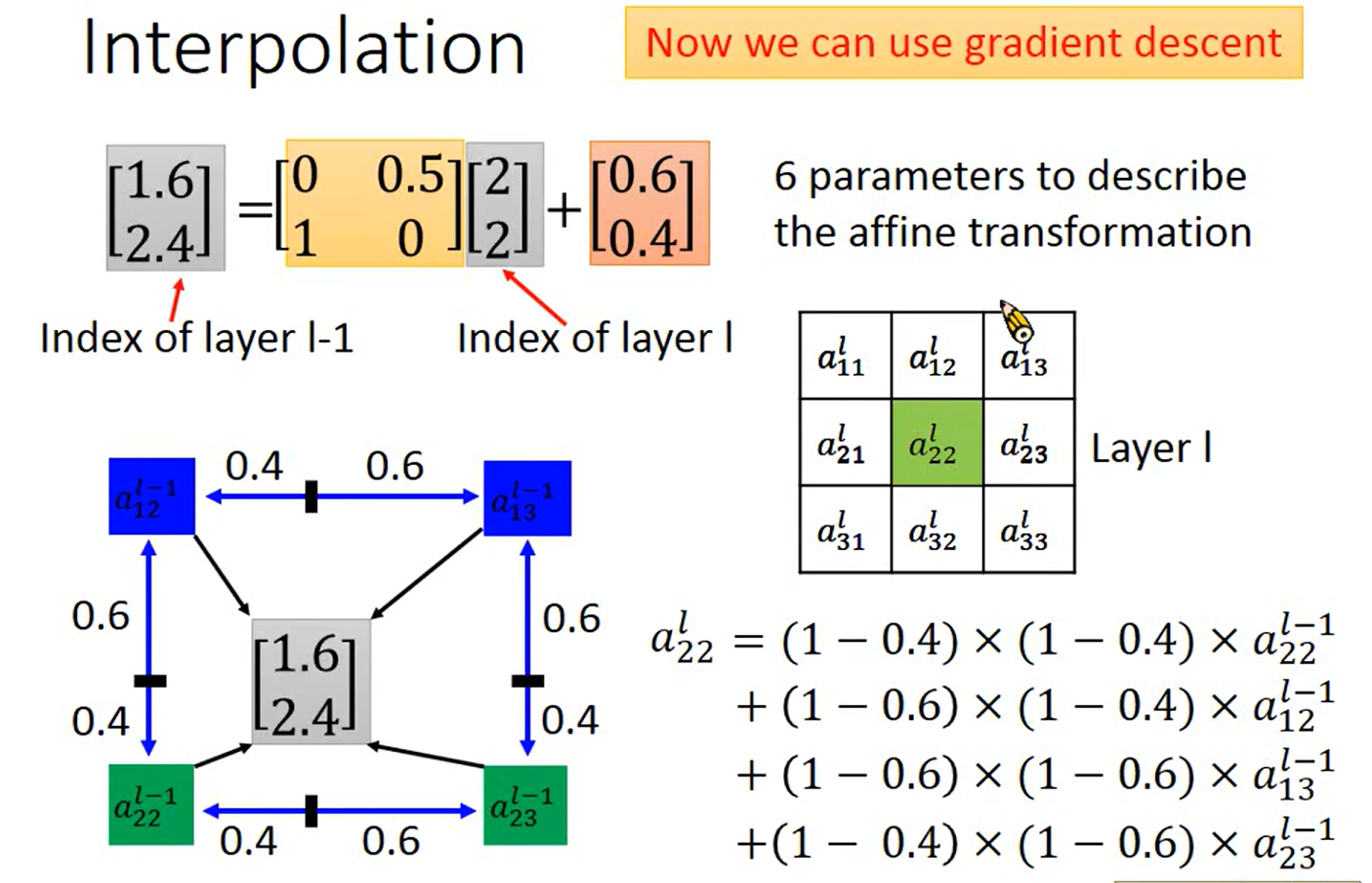
详情请参照 《数字图像处理》
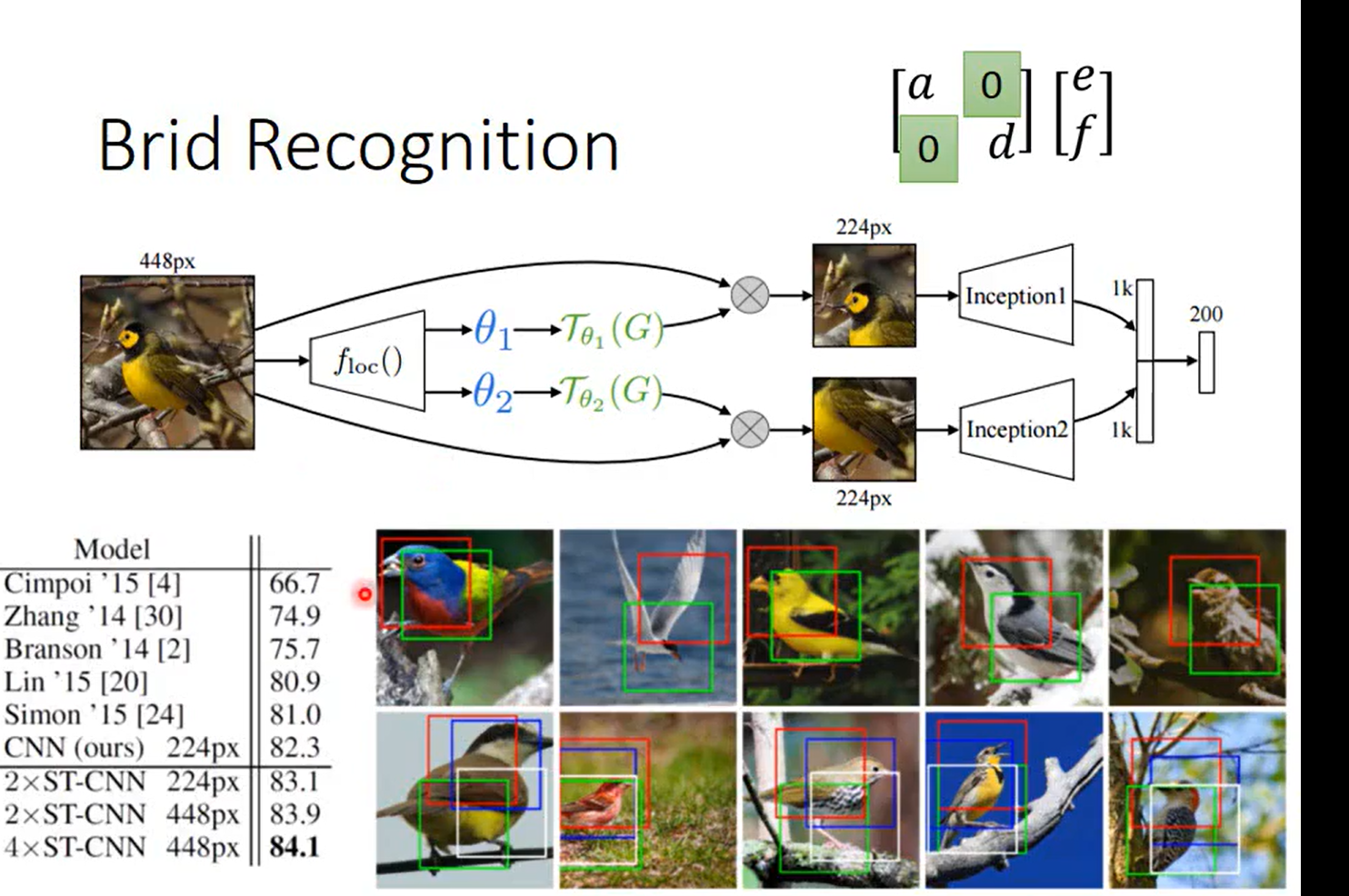
固定了两个参数, 有点focus 的味道, 因为无法做旋转嘛智能做缩放